[JavaScript 오디오 이펙터 만들기] 오디오 이펙터로 나만의 소리 만들기
Logic Pro, Pro Tools처럼? 웹에서 오디오 이펙트 구현하기
![[JavaScript 오디오 이펙터 만들기] 오디오 이펙터로 나만의 소리 만들기](/static/026a9fe9c894f201ec1e45217221447c/b384d/thumbnail.webp "[JavaScript 오디오 이펙터 만들기] 오디오 이펙터로 나만의 소리 만들기")
이번 포스팅에서는 저번 포스팅에 이어 HTML5 Audio API를 사용하여 실제로 오디오 이펙터를 만드는 과정에 대해서 포스팅 하려고 한다.
저번 포스팅에서 이미 이야기 했듯이 Audio API는 여러 개의 노드를 연결하여 오디오의 흐름을 만들어 내는 것을 기본 개념으로 가지고 있고, 이펙터를 만들기 위해 필요한 몇 개의 추상화된 노드들을 기본적으로 제공해주기 때문에 그렇게 어려울 건 없다.
우리는 단지 우리가 만드려고 하는 이펙터들이 각각 어떤 역할을 하며, 어떤 원리를 가지고 있고, 어떤 용도로 사용되는지만 알고 있으면 된다. 오디오에 사용하는 이펙터는 그 종류가 굉장히 많기 때문에 모든 이펙터를 만들어 볼 수는 없고, 필자가 생각했을 때 가장 대표적으로 많이 사용되는 기본적인 이펙터 5개 정도를 구현해볼 생각이다.
기본적으로 오디오를 로드하여 소스 노드(Source Node)를 생성하는 과정은 이미 저번 포스팅에서 설명했기 때문에 따로 설명하지 않겠다. 이번 포스팅에서는 바로 이펙터를 구현하는 내용부터 설명한다. 모든 이펙터는 먼저 해당 이펙터가 하는 일과 원리에 대해서 간략하게 설명하고 이후 묻지도 따지지도 않고 바로 구현 들어가도록 하겠다.
자, 그럼 하나하나 뜯어보도록 하자.
Compressor
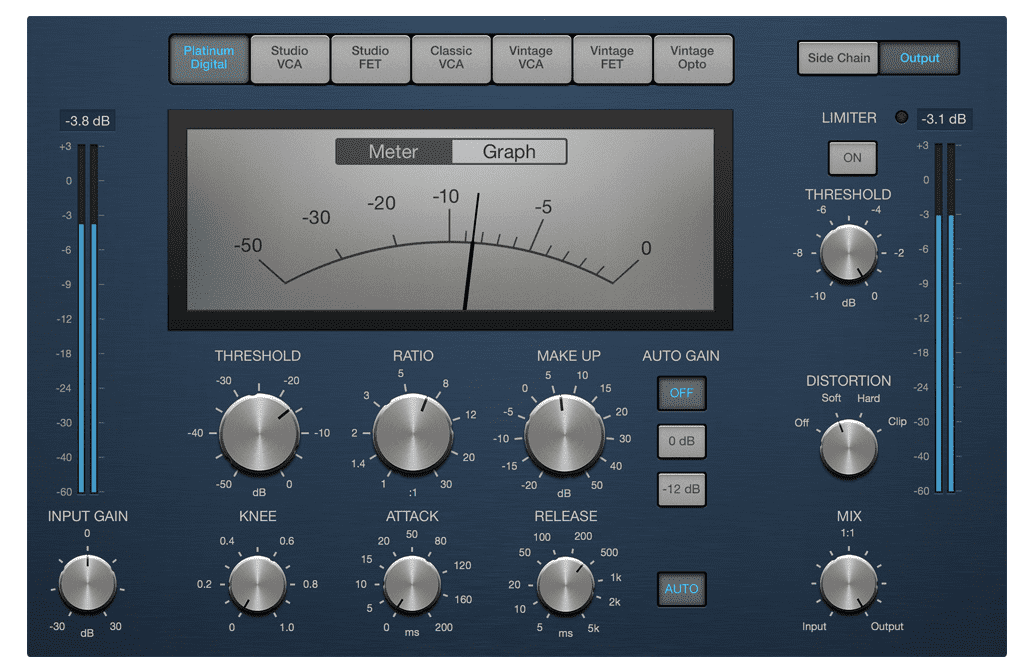
컴프레서(Compressor)는 소리가 일정 크기 이상으로 커질 경우에 이를 꾹꾹 눌러서 다시 작은 소리로 만드는 일종의 압축기 역할을 하는 이펙터이다. 이렇게 소리의 크기를 조절하는 이펙터를 다이나믹 이펙터(Dynamic Effector)라고 한다.
기본적으로 오디오 소스를 사용할 때 기본적으로 컴프레서를 걸어놓고 믹싱을 시작하는 경우가 많은데, 이는 오디오 신호가 일정 크기 이상으로 갑자기 커졌을 때 발생하는 클리핑(Clipping) 현상을 방어하기 위해서이기도 하다. 그럼 여기서 한가지 의문이 들 수 있는데,
아니 단순히 클리핑을 막는 거면 그냥 Gain을 줄이면 해결되는 거 아니야?
맞다. 사실 게인을 줄여도 어느 정도 클리핑을 방어할 수는 있다. 하지만 일반적으로 음악이란 셈여림이 존재하기 때문에 무작정 게인을 낮추면 작은 소리는 아예 입력되지도 않는 슬픈 상황이 발생하게 된다.
예를 들어 여러분이 노래방에 갔을 때를 생각해보자. 일반적으로 발라드를 부른다면 노래의 도입부에서는 잔잔한 느낌으로 조용히 부르다가 후렴에서는 고음을 내기위해 성대를 통과하는 공기의 압력이 올라가며 음량이 커진다.
이때 무작정 게인을 낮춰서 녹음하는 방향으로 접근한다면 필연적으로 가장 큰 소리인 후렴의 빵빵 지르는 소리의 크기에 게인을 맞출 수 밖에 없고, 그러면 도입부의 잔잔한 부분은 거의 입력되지 않을 것이다.
 창법에 따라 조금씩 다르지만 이 음량 차이는 생각보다 크다.
창법에 따라 조금씩 다르지만 이 음량 차이는 생각보다 크다.
이때 컴프레서로 입력 게인을 적당한 수준으로 높혀주고 너무 큰 소리는 압축하여 노래 도입부의 작은 소리와 후렴부의 큰 소리의 격차를 좁혀 전체적인 소리의 크기를 맞추기 위해서 사용하는 것이다.
 Threshold를 넘어선 세기의 신호를 압축해서 Threshold 밑으로 들어가도록 만든다
Threshold를 넘어선 세기의 신호를 압축해서 Threshold 밑으로 들어가도록 만든다
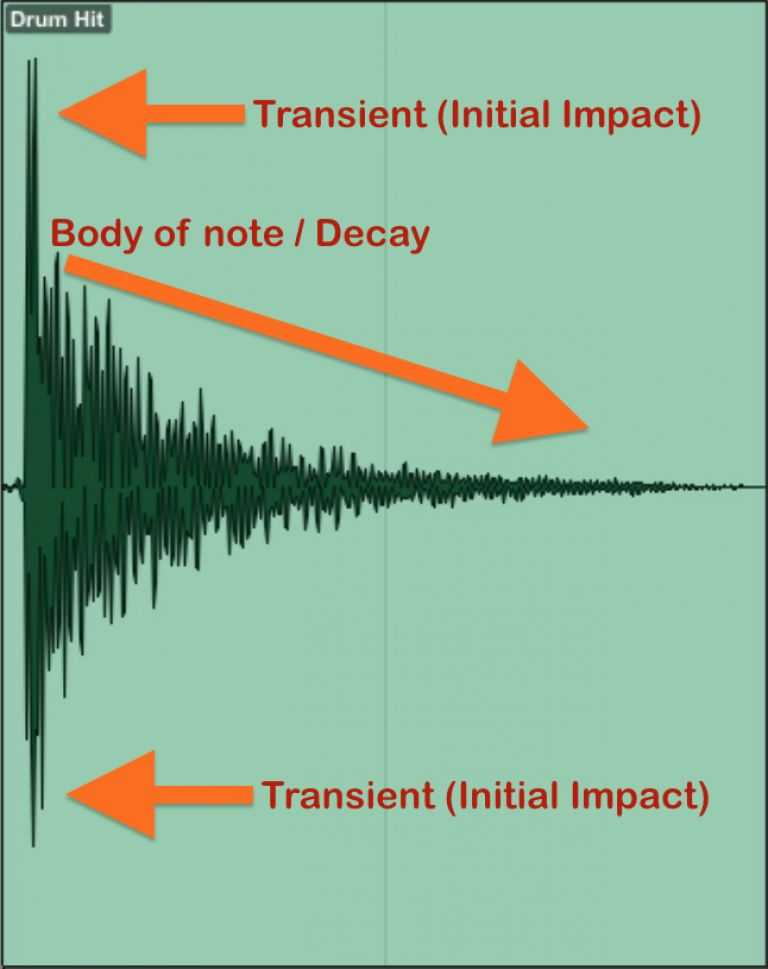
또한 필자가 컴프레서 소리를 압축한다고 했는데, 소리를 압축한다는 것이 뭔지 잘 이해가 안갈 수 있다. 대표적인 예로 우리가 일반적인 음원에서 듣고 있는 “퍽!”, “탁!” 하는 깔끔한 드럼소리가 바로 압축된 소리이다. (보통 이렇게 팍팍치는 소리를 Damping이라고 한다.)
일반적으로 드럼을 녹음하면 드럼 특유의 통이 울리는 잔향이 남는데, 이 소리를 컴프레서로 압축하면 우리가 일반적으로 듣는 깔끔한 드럼소리로 만들 수 있다.
그 외에도 베이스에 컴프레서를 사용하여 단단한 느낌을 부여하거나 멀리 있는 소리를 가까이로 끌어오거나 그 반대 역할도 할 수 있는 등, 컴프레서만 잘 사용해도 소리에 굉장히 많은 느낌을 부여할 수 있다. 그래서 필자에게 사운드 엔지니어닝을 알려주셨던 선생님도 컴프레서의 중요성을 굉장히 강조하셨던 기억이 난다.
컴프레서는 몇가지 값들을 사용하여 신호를 언제부터 압축할 것인지, 어느 정도의 속도로 압축할 것인지와 같은 세팅을 할 수 있도록 설계되었다. HTML5 Audio API에서 제공하는 DynamicsCompressorNode도 이 값들을 동일하게 제공하고 있으므로 우리는 이 값들이 어떤 의미를 가지고 있는지 알아야 올바른 방법으로 이 노드를 사용할 수 있다.
Threshold
Threshold는 소리를 어느 크기부터 압축할 것인지를 정하는 임계점을 의미한다. 단위는 DB(데시벨)을 사용한다.
Ratio
Ratio는 Threshold를 넘은 소리가 어느 정도의 비율로 줄어들 것인지를 정하는 값이다. 이 값은 입력:출력의 비를 의미하기 때문에 일반적으로는 2:1, 5:1와 같은 비율로 이야기한다.
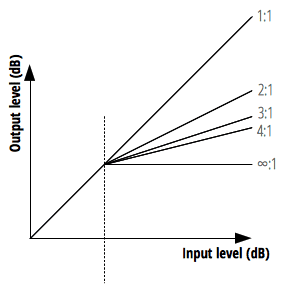
하지만 HTML5 Audio API의 속성에서는 단위가 조금 다르다. 공식 문서에는 “출력 값의 1db를 변경하기 위해 필요한 db값”이라고 적혀있는데 그냥 이 속성에 12를 할당하면 압축 비율이 12:1라고 생각하면 된다.
보통 컴프레서를 적당히 걸었다고 하면 4:1 정도의 비율을 말하기 때문에 해당 속성의 기본 값인 12:1은 상당히 하드한 압축 비율이라고 할 수 있다.
Attack
Attack은 소리를 어느 정도의 빠르기로 압축할 것인지를 정하는 값이다. Threshold를 넘은 값을 얼마나 빠르게 때려서 눌러 담을 지를 정하면 된다고 생각하자.
많은 분들이 여기서 정해주는 어택 타임이 “Attack이 시작되는 시간”으로 잘못 알고 있는 데, 사실 신호의 크기가 Threshold를 넘으면 Attack 자체는 바로 시작된다. 우리가 정해주는 어택 타임은 정해진 “Ratio로 정해준 비율까지 도달하는 데 걸리는 시간”이다.
단위는 보통 밀리초(Milliseconds)를 사용하지만 Audio API에서는 초(Seconds)를 사용한다.
Release
Attack이 소리를 누르는 빠르기였다면 Release는 압축한 소리를 어느 정도의 빠르기로 다시 풀어줄 것인가를 정하는 값이다. 이때 풀어주는 값은 소리의 원래 크기가 아니라 표준 음량인 10db에 도달하는 시간을 목표로 한다.
Release도 Attack과 마찬가지로 단위는 보통 밀리초를 사용하지만 Audio API에서는 초를 사용한다.
Knee
Knee는 사실 대부분의 하드웨어 컴프레서에는 없는 기능이지만 소프트웨어 컴프레서에서는 꽤 자주 볼 수 있는 기능이다. 이 값은 컴프레서가 얼마나 자연스럽게 적용될 것인지를 결정한다.
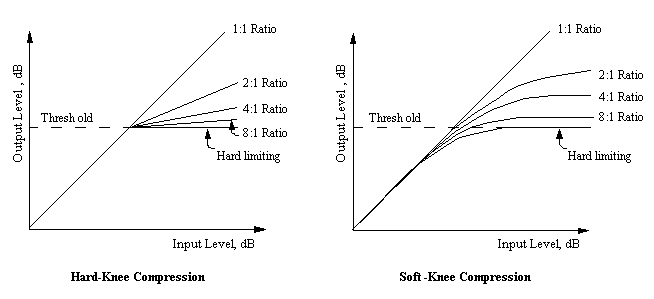
위 그림의 그래프의 꺾이는 정도가 컴프레서가 얼마나 서서히 적용되는지를 보여주고 있다. 이때 빠르게 팍! 적용하는 컴프레션을 Hard하다고 하고 천천히 적용하는 컴프레션을 Soft하다고 한다.
Compressror 구현해보기
사실 위에서 이야기 했듯이 HTML5 Audio API는 자체적으로 DynamicsCompressorNode를 제공하기 때문에 우리가 소리를 압축하는 알고리즘을 직접 구현할 필요가 없다. 단지 노드를 생성한 후 연결해주기만 하면 될 뿐이다.
이번에는 사용자가 업로드한 오디오 파일에서 오디오 버퍼를 추출하여 소스 노드를 생성하는 것이 아니라 <audio> 태그에서 추출하여 소스 노드를 생성하는 방식으로 진행하도록 하겠다. (이렇게 하면 코드가 훨씬 간단해진다) 지금 생성한 소스노드는 앞으로 다른 이펙터를 구현할 때도 계속 사용할 것이다.
const audioContext = new (AudioContext || webkitAudioContext)();
const audioDOM = document.getElementById('my-audio');
const sourceNode = audioContext.createMediaElementSource(audioDOM);
const threshold = -24;
const attack = 0.003;
const release = 0.25;
const ratio = 12;
const knee = 30;
const compressorNode = audioContext.createDynamicsCompressor();
compressorNode.threshold.setValueAtTime(threshold, audioContext.currentTime);
compressorNode.attack.setValueAtTime(attack, audioContext.currentTime);
compressorNode.release.setValueAtTime(release, audioContext.currentTime);
compressorNode.ratio.setValueAtTime(ratio, audioContext.currentTime);
compressorNode.knee.setValueAtTime(knee, audioContext.currentTime);
const inputGainNode = audioContext.createGain();
const outputGainNode = audioContext.createGain();
sourceNode.connect(inputGainNode);
inputGainNode.connect(compressorNode);
compressorNode.connect(outputGainNode);
outputGainNode.connect(audioContext.destination);필자는 소스 > 게인 > 컴프레서 > 게인의 순서로 오디오 소스의 흐름을 생성했는데, 사실 이건 개인의 취향이다. 하지만 일반적으로 대부분의 컴프레서는 인풋 게인과 아웃풋 게인을 모두 가지고 있으므로 필자도 이와 동일하게 구현했다.
이후 소스노드를 재생해보면 압축된 소리를 들을 수 있긴 한데, 사실 사운드 엔지니어가 아닌 일반인이 소리의 미세한 압축의 정도를 느끼기는 힘드므로 위의 값들을 조금 극단적으로 바꿔보는 것을 추천한다.
Reverb

리버브(Reverb)는 소리에 울림을 통해 공간감을 부여하는 공간계 이펙터이다. 소리에 울림을 통해 공간감을 부여한다는 게 어떤 의미일까?
사실 우리는 소리를 듣고 현재 있는 공간이 넓은지 좁은지, 이 공간이 거친 벽면으로 이루어져 있는지, 아니면 유리같은 맨들맨들한 공간으로 이루어져 있는지를 대략적으로 파악할 수 있다. 그 차이가 워낙 미세해서 훈련되지 않은 사람이라면 알아채기 힘들 뿐이다.
어떻게 이런 일이 가능할까? 바로 소리의 반사에 의한 잔향 때문이다. 먼저, 소리를 듣고 공간의 크기를 감지하는 원리는 간단하다. 필자가 어떤 방 안에서 소리를 “왁!”하고 지른 뒤 얼마 후에 첫번째 반사음이 들리는지를 감지하면 된다.
하지만 이 첫번째 반사음은 밀리초 단위의 굉장히 빠른 속도로 다시 필자에게 돌아오기 때문에 1초, 2초 이렇게 세는 것이 아니라 그냥 느껴야하는 것이다. 이때 이 반사음을 초기 반사음(Early Reflection)이라고 한다.
하지만 여기서 끝이 아니다. 소리가 한번 반사되어 여러분의 귀로 전달된 뒤에도 반사는 계속 될 것이다. 이때 이 잔향들은 공간의 사방팔방으로 부딪히고 반사되어 여러분의 귀로 다시 돌아올 것이다.
 초록색 선이 초기 반사음, 사방팔방 부딪히는 파란색 선이 바로 잔향이다
초록색 선이 초기 반사음, 사방팔방 부딪히는 파란색 선이 바로 잔향이다
이때 이 잔향이 얼마나 오래 들리는가, 얼마나 선명하게 들리는가와 같은 특성이 방의 재질을 결정한다. 이야기만 들으면 이렇게 소리를 듣고 공간을 판별한다는 것이 불가능한 것 같지만 여러분이 이미 평소에 듣고 음악에는 모두 이 원리를 적용한 공간적 설계가 함께 담겨있다.
이렇게 리버브는 말 그대로 잔향을 만들어내기만 하면 되기 때문에 하드웨어 리버브 중에서는 스프링이나 철판 등의 재료를 장비 내부에 넣어놓고 오디오를 재생하여 재료가 떨리며 발생한 잔향을 증폭하는 방식을 사용하는 것도 있다. 즉, 뜯어보면 장비 내부에 스프링이나 철판 하나 딸랑 들어있다는 것이다. (이런 단순한 구조로 좋은 소리를 뽑는다는 게 더 무섭…)
그러나 리버브를 소프트웨어로 구현할 때는 이야기가 조금 다르다. 컴퓨터는 스프링이나 철판의 떨림과 같은 자연적인 아날로그 신호를 생성할 수 없으므로 직접 계산을 통해 구현해야한다. 이때 소프트웨어 리버브는 크게 두 가지 종류로 나누어지는데 바로 Convolution Reverb와 Algorithm Reverb이다.
하지만 이 포스팅에서 두 리버브를 모두 구현하기에는 글이 너무 길어질 것 같으므로 아쉬운대로 컨볼루션 리버브에 초점을 맞춰 진행하겠다. (알고리즘 리버브만 해도 포스팅 하나 분량이다.)
Convolution Reverb
컨볼루션 리버브(Convolution Reverb)는 실제 공간의 잔향을 녹음한 후에 잔향 오디오 소스와 원본 오디오 소스를 실제 공간의 울림을 원본 오디오 소스에 합성하는 방법이다.
이때 실제 공간의 잔향을 녹음하는 대표적인 방법을 간단하게 설명하자면, 녹음하고자 하는 공간에 순수한 사인파(Sine Wave)의 소리를 낮은 주파수부터 높은 주파수까지 쭈우우욱 이어서 틀고 그때 발생하는 잔향을 녹음하는 것이다.
 공간의 IR을 녹음하는 모습 - 출처: http://www.alanjshan.com/impulse-response-capture/
공간의 IR을 녹음하는 모습 - 출처: http://www.alanjshan.com/impulse-response-capture/
이때 이 잔향 신호를 Impulse Response(IR)이라고 부르기 때문에 컨볼루션 리버브는 IR 리버브라는 이름으로도 불린다. 이렇게 녹음한 IR은 원본 소스에 컨볼루션(Convolution), 또는 합성곱이라고 불리우는 연산을 통해 합쳐지게 된다.
이 컨볼루션이라는 개념을 수학적으로 접근하기 시작하면 머리도 아프고 또 포스팅이 길어지니까 간단하게 정의해보자면, 그냥 서로 다른 정보들을 섞는 것이라고 표현할 수 있다.
이 포스팅을 읽는 분들은 아마 개발자 분들이 많을 테니 우리에게 좀 더 친숙한 머신러닝을 사용하여 컨볼루션을 설명하자면 학습 알고리즘 중 하나인 CNN(Convolution Neural Network)을 예로 들어볼 수 있겠다.
CNN에서도 첫번째 레이어의 이미지를 두번째 레이어로 보낼 때 행렬로 구현한 커널(또는 필터)와 이미지를 섞어서 피처맵을 생성한 후 다음 레이어로 보내게된다. 이때 첫번째 레이어의 이미지와 커널의 정보가 섞인 것이라고 생각할 수 있다.
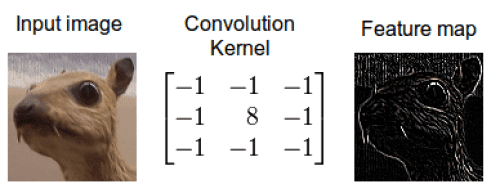 원본 이미지와 커널을 섞어서 새로운 정보인 피처맵을 만들어낸다
원본 이미지와 커널을 섞어서 새로운 정보인 피처맵을 만들어낸다
오디오에서의 컨볼루션 리버브도 이와 마찬가지다. 이 경우에는 섞어야하는 정보가 원본 소스와 IR이 된 것 뿐이다.
컨볼루션은 원본 소스와 IR이라는 두 오디오 소스의 주파수 스펙트럼을 곱하는 과정이기 때문에 이를 통해 두 소스 간에 겹치는 주파수는 강조되고 겹치지 않는 주파수는 감쇠된다. 이렇게 원본 소스와 IR 간 겹치는 주파수가 강조되면 원본 소스는 IR의 음질의 특성을 띄게 되는데, 이게 바로 컨볼루션 리버브의 원리이다.
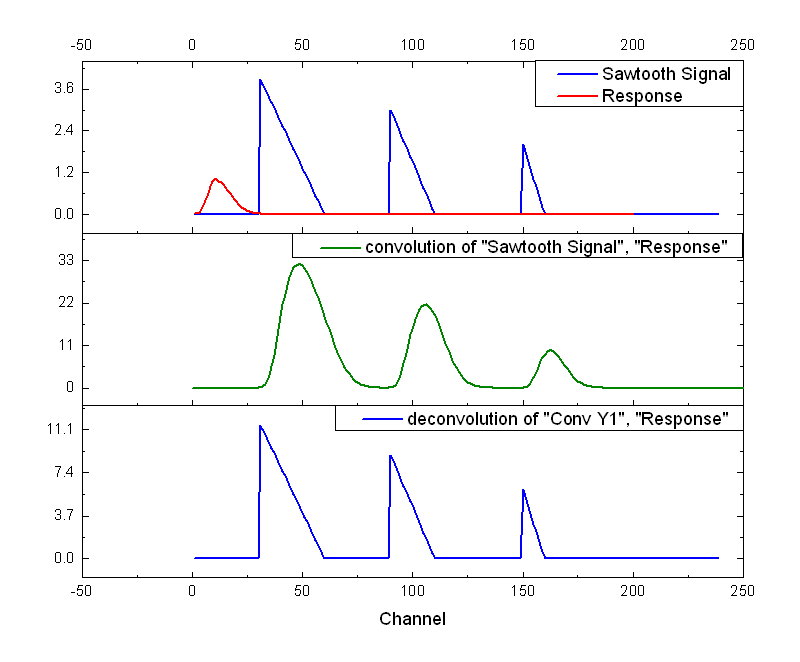 원본 신호와 녹음한 IR 신호를 컨볼루션 연산한 모습
원본 신호와 녹음한 IR 신호를 컨볼루션 연산한 모습
사실 HTML5 Audio API는 컨볼루션 연산을 대신 수행해주는 ConvolverNode를 제공하기 때문에 컨볼루션이 무엇인지 몰라도 컨볼루션 리버브를 만드는 데는 아무 문제가 없다.
그러나 적어도 이 이펙터가 2개의 신호 정보를 곱해서 새로운 신호를 만들어내는 원리를 가지고 있다는 것을 알아야 필자가 왜 이런 코드를 작성하는지도 알 수 있기 때문에 대략적인 설명을 하는 것이다.
어쨌든 컨볼루션 리버브의 대략적인 원리를 파악했다면 이제 바로 만들어보도록 하자.
Convolution Reverb 구현해보기
먼저 HTML5 Audio API는 ReverbNode 같은 건 제공하지 않는다. 하지만 위에서 설명했듯이 컨볼루션 연산을 지원하는 ConvolverNode를 제공해주고 있기 때문에 우리는 잔향 소스인 IR(Impulse Response)만 직접 만들어주면 된다.
그리고 일반적으로 리버브는 wet과 dry라는 수치로 원본 소스와 잔향 소스를 비율에 맞게 섞을 수 있도록 제작되므로 필자도 동일하게 코드를 작성하겠다.
const mix = 0.5;
const time = 0.01;
const decay = 0.01;리버브의 사용할 3개의 변수를 먼저 설명하자면, mix는 wet/dry의 비율을 의미하고, time은 잔향의 길이, decay는 잔향이 감소하는 빠르기를 의미한다. 그럼 이제 이 값들을 사용하여 직접 IR을 생성해보자.
function generateImpulseResponse () {
const sampleRate = audioContext.sampleRate;
const length = sampleRate * time;
const impulse = audioContext.createBuffer(2, length, sampleRate);
const leftImpulse = impulse.getChannelData(0);
const rightImpulse = impulse.getChannelData(1);
for (let i = 0; i < length; i++) {
leftImpulse[i] = (Math.random() * 2 - 1) * Math.pow(1 - i / length, deacy);
rightImpulse[i] = (Math.random() * 2 - 1) * Math.pow(1 - i / length, deacy);
}
return impulse;
}뭔가 복잡해보이지만 뜯어보면 별 거 없다. sampleRate는 우리가 생성하고자 하는 IR의 샘플레이트, 즉 음질을 의미하고 length는 sampleRate * time, 즉 time초 만큼의 잔향을 표현하기 위한 버퍼의 길이를 의미한다.
그리고 그냥 버퍼 노드를 하나 생성한 다음 -1 ~ 1의 무작위 값을 생성한 후 1 - i / length에 decay를 제곱한 후 방금 생성한 난수에 곱해준다. 이러면 i값이 커질수록 값이 작아질 것이고, deacy 값이 커질수록 더 빠르게 작아질 것이다. 이는 잔향의 감쇠를 표현 해준 것이다. 이후 이 샘플을 방금 만든 버퍼 노드에 쭈르륵 담아주면 끝이다.
이렇게 생성된 IR 버퍼를 파형으로 표현해보면 대략 다음과 같은 모양을 가질 것이다.
쨘, 이렇게 간단하게 IR을 생성해보았다. 이제 ConvolverNode를 사용하여 원본 소스와 이 IR을 합성해주는 것만 남았다. 리버브 이펙터의 오디오 흐름을 만들기 위해서 필요한 노드들을 먼저 생성해보자.
const inputNode = audioContext.createGain();
const wetGainNode = audioContext.createGain();
const dryGainNode = audioContext.createGain();
const reverbNode = audioContext.createConvolver();
const outputNode = audioContext.createGain();위에서도 설명했듯이 일반적인 리버브 이펙터는 wet/dry라는 수치를 사용하여 원본 소스와 리버브가 적용된 소스를 섞어서 출력하는 기능을 제공한다. 이때 dry한 소스는 리버브 이펙터를 거치지 않고 바로 outputNode로 연결되서 출력되어야 하며, wet한 소스는 우리가 만든 reverbNode를 한번 거치고 outputNode로 출력되어야 한다.
sourceNode.connect(inputNode);
// Dry 소스 노드 연결
inputNode.connect(dryGainNode);
dryGainNode.connect(outputNode);
dryGainNode.gain.value = 1 - mix;
// IR을 생성하여 Convolver의 오디오 버퍼에 입력해준다.
reverbNode.buffer = generateImpulseResponse();
// Wet 소스 노드 연결
inputNode.connect(reverbNode);
reverbNode.connect(wetGainNode);
webGainNode.connect(outputNode);
wetGainNode.gain.vaule = mix;
outputNode.connect(audioContext.destination);이렇게 컨볼루션 리버브를 간단하게 구현해보았다. 사실 컨볼루션 리버브의 퀄리티에 가장 큰 영향을 끼치는 것은 IR의 퀄리티인데, 우리는 대충 만든 샘플 오디오로 IR을 만들었으므로 이 리버브의 퀄리티는 좋을 수가 없다. 그러나 소스 노드를 재생해서 들어보면 신기하게도 소리에 공간감이 부여된 것을 들어볼 수 있다.
만약 기회가 된다면 다음에는 알고리즘 리버브의 구현체도 한번 포스팅 해보도록 하겠다. 알고리즘 리버브는 실제 공간의 잔향을 녹음하여 사용하는 컨볼루션 리버브와는 다르게 100% 알고리즘으로만 구현된 리버브이다. 그렇기 때문에 약간 인위적인 느낌이 나기는 하지만 컨볼루션 리버브와는 또 색다른 느낌을 부여할 수 있으므로 사운드 엔지니어들은 이 두가지 리버브의 특성을 파악하고 적재적소에 사용한다.
그렇기 때문에 개발자들에게는 오히려 컨볼루션 리버브보다 알고리즘 리버브 쪽이 더 이해가 잘될 수 있으나, ConvolverNode 하나와 대충 만든 IR만 있으면 나머지는 알아서 다 연산해주는 컨볼루션 리버브와는 다르게 알고리즘 리버브는 진짜 밑바닥부터 만들어야한다. 그래서 아쉽지만 알고리즘 리버브는 다음에 포스팅 하도록 하겠다.
만약 알고리즘 리버브의 구현체가 궁금하신 분은 필자의 깃허브 레파지토리에서 확인해볼 수 있다.
Delay
딜레이(Delay)는 리버브와 같은 공간계 이펙터이고 소리를 반복해서 들려준다는 점이 같기 때문에 비슷하다고 생각할 수 있지만 그 원리와 용도는 많이 다르다.
먼저, 딜레이는 단순히 소리를 반복하는 효과이지만 리버브는 공간 내에서의 복잡한 반사음을 흉내내는 것이므로 딜레이만 사용하면 리버브와 같은 자연스러운 공간감을 표현하기가 힘들다.
방금 만들어봤던 리버브 이펙터는 사실적인 공간 표현이 목적이기 때문에 컨볼루션이나 복잡한 알고리즘을 사용하지만 딜레이는 그냥 원본 소스를 잠깐 지연시켰다가 초 후에 다시 틀어주면서 조금씩 소리를 작게 해주면 끝이다.
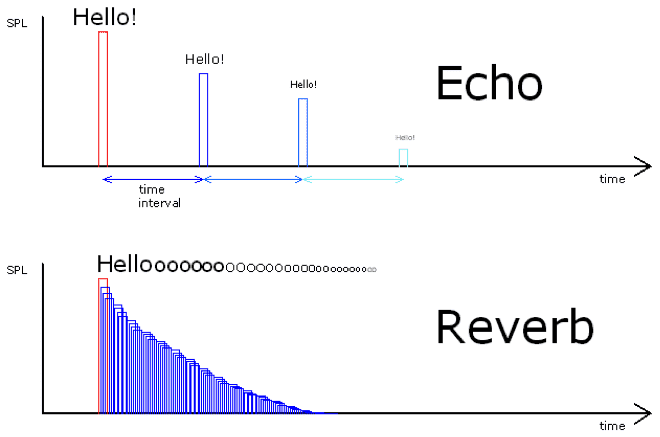 Echo(Delay)와 Reverb의 차이
Echo(Delay)와 Reverb의 차이
딜레이는 이렇게 간단한 원리를 가지고 있기 때문에 만드는 것 역시 그렇게 어렵지 않다.
Delay 구현해보기
HTML5의 Audio API는 인풋으로 받은 신호를 지연시켜서 다시 출력하는 DelayNode를 제공해주기 때문에 우리는 이 노드를 사용하여 간단하게 딜레이 이펙터를 구현할 수 있다.
그러나 단순히 DelayNode만 사용한다면 단 한번의 지연만 발생시킬 수 있기 때문에 우리는 한가지 얌생이를 사용하여 딜레이를 구현할 것이다. 먼저 딜레이에 필요한 변수들을 선언해보도록 하자.
const mix = 0.5;
const feedback = 0.5;
const time = 0.3;리버브와 마찬가지로 대부분의 딜레이 이펙터도 wet/dry 값을 사용하여 원본 소스와 딜레이된 소스를 섞어서 출력해주는 기능을 가지고 있기 때문에 필자도 동일하게 구현해줄 것이다. 그리고 feedback 변수는 원본 소스가 한번 딜레이될 때 감소시킬 음량이고 time 변수는 메아리들의 간격을 의미한다. 딜레이에 사용할 변수들을 모두 선언했다면 이제 노드들을 만들 차레이다.
const inputNode = audioContext.createGain();
const wetGainNode = audioContext.createGain();
const dryGainNode = audioContext.createGain();
const feedbackNode = audioContext.createGain();
const delayNode = audioContext.createDelay();
const outputNode = audioContext.createGain();webGainNode와 dryGainNode는 리버브와 동일하기 때문에 그냥 넘어가고, 새로운 노드인 feedbackNode와 delayNode에 집중해보자. 사실상 딜레이 이펙터는 이 두개의 노드가 핵심이다. 먼저, 딜레이 이펙터가 하는 일에 대해서 다시 한번 살펴보자.
입력 -> 지연 -> 감소된 신호 출력 -> 입력 -> 지연 -> 감소된 신호 출력…
딜레이 이펙터가 하는 일은 이게 전부다. 신호를 조금씩 지연시키고 감소된 신호를 다시 출력하는 일을 반복한다. 그래서 필자는 delayNode와 feedbackNode를 서로 연결해주는 방법으로 이 이펙터를 구현하려고 한다.
 이렇게 간단한 연결만으로 딜레이를 구현할 수 있다
이렇게 간단한 연결만으로 딜레이를 구현할 수 있다
이렇게 노드들을 연결하게되면 DelayNode를 통해 입력된 오디오 신호가 지연된 후 FeedbackNode와 OutputNode로 출력되고, FeedbackNode를 통해서 게인이 감소된 소리는 다시 DelayNode로 입력되어 지연된 후 OutputNode로 출력될 것이다. 그럼 위 그림대로 한번 노드들을 연결해보도록 하자.
sourceNode.connect(inputNode);
// Dry 소스 노드 연결
inputNode.connect(dryGainNode);
dryGainNode.connect(outputNode);
dryGainNode.gain.value = 1 - mix;
// Delay 루프 생성
delayNode.connect(feedbackNode);
feedbackNode.connect(delayNode);
// Wet 소스 노드 연결
inputNode.connect(delayNode);
delayNode.connect(wetGainNode);
wetGainNode.connect(outputNode);
wetGainNode.gain.vaule = mix;
outputNode.connect(audioContext.destination);이제 소스 노드를 재생해보면 딜레이 이펙터를 통해 메아리가 치는 듯한 효과가 적용된 소리를 들어볼 수 있다.
Filter
필터(Filter)는 무언가를 걸러내는 도구 혹은 개념을 의미한다. 우리는 이미 필터라는 개념을 평소에 많이 사용하고 있기 때문에 그렇게 이해하기 어려운 개념은 아닐 것이다. 그리고 오디오 이펙터에서의 필터는 바로 주파수를 걸러내는 역할을 한다.
쉽게 말하면 필터는 오디오의 음역대 중 특정한 음역대만 콕 집어내어 없애버릴 수 있는 이펙터인 것이다. 그래서 필터는 주로 소리에 섞여있는 노이즈를 걸러내거나 너무 낮거나 너무 높아서 쓸데없는 울림을 생성하는 주파수를 걸러내는데 많이 사용된다.
이러한 필터의 특성을 잘 사용하면 상당히 재미있는 짓을 많이 할 수 있는데 대표적인 예를 두개 정도 들자면, 바로 전화기에서 나오는 목소리를 만들거나 클럽에서 나는 음악 소리와 같은 소리를 만드는 경우가 있다.
먼저, 전화기에서 나오는 목소리는 전체 주파수 중에서 특정한 대역의 주파수만 통과시키는 Bandpass 필터를 사용하여 만들어 낼 수 있다. 전화기가 전송할 수 있는 주파수 대역에 한계가 있다는 것을 이용하여 인간의 목소리 대역인 100 ~ 250hz의 주파수를 제외한 나머지 주파수를 모두 잘라내는 것이다.
그러므로 사람의 목소리 소스에 필터를 사용하여 100 ~ 250hz 대역을 제외하고 나머지 주파수를 모두 날려버리게되면 우리가 일반적으로 전화를 할때 들리는 목소리로 만들어낼 수 있는 것이다.
클럽에서 나는 음악 소리도 비슷한 원리로 만들어내는 것이다. 클럽의 특성 상 보통 지하에 위치하고 좁은 입구를 가지고 있는 경우가 많다. 그런 상황에서 클럽에서 노래를 틀게되면 소리가 밖으로 빠져나올 수 있는 통로가 거의 없기 때문에 우리가 지상에서 클럽에서 틀고 있는 노래를 들어보면 굉장히 묵직한 “붐~ 붐~“하는 소리가 들리게 된다.
클럽 음악의 특성 상 강한 드럼과 베이스로 인해 저음이 부각되는 경우가 많고, 고음보다는 저음의 물체 투과율이 높기 때문에 클럽 외부에서는 상대적으로 고음에 비해 많이 투과된 저음을 위주로 듣게 되는 것이다. 이러한 파동의 특성은 소리에 한정되는 것은 아니고 빛과 같은 다른 파동또한 고주파의 에너지 손실률이 저주파보다 높다.
이렇듯 사운드 엔지니어들은 특정 상황의 소리가 어떻게 들리는지 분석하고 필터를 포함한 여러가지 이펙터들을 사용하여 그 상황의 현장감을 부여하기도 한다.
다행히도 HTML5 Audio API는 이런 필터를 만들 수 있는 BiquadFilterNode를 제공해주고 있기 때문에 우리가 직접 오디오 버퍼를 까서 주파수를 분석해야하는 슬픈 상황은 피할 수 있다. 우리는 이 노드가 제공하는 값들이 어떤 것을 의미하는지만 알고 있으면 된다.
그럼 BiquadFilterNode가 제공하는 속성들이 무엇을 의미하는지 하나하나 살펴보도록 하자.
Frequency
Frequency는 어떤 대역의 주파수를 걸러낼 것인지를 정하는 값이다. 단위는 hz(헤르츠)를 사용하며, 10hz부터 오디오의 샘플레이트의 절반까지의 값을 할당할 수 있다. 만약 오디오 소스의 샘플레이트가 44,100hz라면 22,050까지를 할당할 수 있다는 의미이다.
Q
신호를 걸러낸다는 것은 기본적으로 칼처럼 딱 자를 수 있는 것이 아니다. 소리 자체는 아날로그 신호이기 때문에 네모 반듯하게 잘라낼 수 없고 어느 정도 바운더리를 가지고 걸러낼 수밖에 없는데, 이때 Q는 특정 주파수를 걸러낼 때 얼마나 예민하게 걸러낼 수 있는 지를 의미한다.
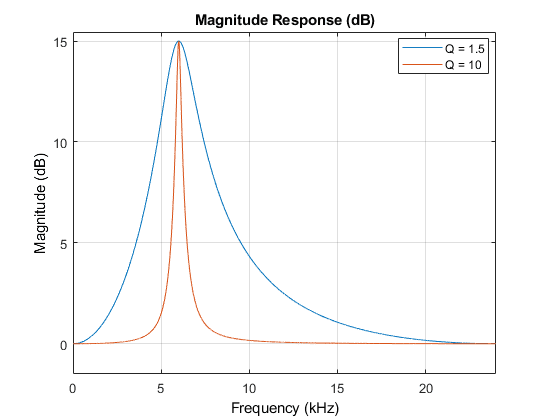
Q에는 0.0001 ~ 1000 사이의 값을 할당할 수 있으며, Q의 값이 높을 수록 잡아낸 주파수를 더 예민하게 걸러낼 수 있다. 그러나 오디오 신호를 필터링 할 때 Q가 너무 높다면 자연스럽게 들리지 않고 인위적으로 들릴 수 있기 때문에 적당한 값을 찾는 것이 중요하다.
Type
BiquadFilterNode로는 여러가지 타입의 필터를 만들어 낼 수 있는데, 크게는 주파수를 아예 걸러내버리는 타입과, 특정 주파수를 증폭시키거나 감소시킬 수 있는 타입으로 나눠진다.
주파수를 걸러내는 타입
lowpass(highcut): 지정한 주파수보다 높은 주파수를 모두 걸러낸다.highpass(lowcut): 지정한 주파수보다 낮은 주파수를 모두 걸러낸다.bandpass: 지정한 주파수를 제외한 모든 주파수를 걸러낸다.notch: 지정한 주파수를 걸러낸다.
주파수를 증폭/감소하는 타입
lowshelf: 지정한 주파수보다 낮은 주파수를 증폭/감소 시킨다.highshelf: 지정한 주파수보다 높은 주파수를 증폭/감소 시킨다.peaking: 지정한 주파수를 증폭/감소 시킨다.
이 중 주파수를 증폭/감소시키는 타입은 밑에서 후술할 EQ(Equalizer)에서도 사용할 수 있다. 이번에는 단순히 주파수를 걸러내는 필터를 만들 예정이므로 필자는 주파수를 걸러내는 타입만을 사용하여 필터를 구현할 것이다.
필자는 특정 주파수보다 높은 주파수를 모두 걸러내는 Lowpass 필터와 특정 주파수보다 낮은 주파수를 모두 걸러내는 Highpass 필터를 구현할 것이다. 그럼 한번 간단하게 필터를 구현해보도록 하자.
Filter 구현해보기
우선 AudioContext 객체의 createBiquadFilter 메소드를 사용하여 BiquadFilterNode를 생성한다. 필자가 가지고 있는 오디오 샘플은 44,100hz의 샘플레이트를 가지고 있으므로 Lowpass 필터의 주파수는 1,000hz로 Highpass 필터의 주파수는 20,000hz로 설정하겠다.
const lowpassFilterNode = audioContext.createBiquadFilter();
lowpassFilterNode.type = 'lowpass';
lowpassFilterNode.frequency.setValueAtTime(1000, audioContext.currentTime);
const highpassFilterNode = audioContext.createBiquadFilter();
highpassFilterNode.type = 'highpass';
highpassFilterNode.frequency.setValueAtTime(20000, audioContext.currentTime);Q값을 따로 설정해주지 않았는데, 그래도 사실 상관없다. BiquadFilterNode의 Q는 기본 값으로 350을 가지고 있고 이 값은 너무 과하지도 부족하지도 않은 적당한 값이기 때문에 그냥 기본 값을 사용할 것이다.(조금 귀찮기도 하다.)
이제 생성한 필터 노드들을 오디오 소스와 연결해주면 1,000hz보다 낮고 20,000hz보다 높은 주파수가 제거된 오디오 샘플을 들어볼 수 있다.
sourceNode.connect(lowpassFilterNode);
lowpassFilterNode.connect(highpassFilterNode);
highpassFilterNode.connect(audioContext.destination);여기까지 읽으신 분들은 슬슬 느끼기 시작했겠지만 사실 HTML5 Audio API가 워낙 잘 만들어져있어서 개발자가 만져야할 부분이 거의 없다. 필자는 BiquadFilterNode의 존재를 알기 전에는 “와 이거 필터는 어떻게 만들지…?”라고 고민했었는데 사실 제일 고민할 필요가 없는 놈이었다. (그래서 약간 허무하기도 했다.)
EQ
Equalizer(EQ, 이퀄라이저)는 이름에서도 알 수 있듯이 일종의 주파수 평탄화 작업(Frequancy Equalizing)을 하는 목적으로 사용하는 이펙터이다.
EQ는 컴프레서와 함께 오디오 믹싱의 기본으로 깔고 들어가는 이펙터인데, 원본 소스에서 쓸데없는 소리를 없애고 다른 소리들과의 조화를 이루도록 하는 용도로 주로 사용한다. EQ는 결국 주파수를 컨트롤하는 이펙터이므로 필터를 사용하여 구현하는데, 이미 우리는 필터를 한번 만들어봤기 때문에 EQ 정도는 뚝딱 만들 수 있다.
EQ는 크게 파라메트릭 이퀄라이저(Parametric EQ)와 그래픽 이퀄라이저(Graphic EQ) 두 가지 종류로 나누어지는데, 필자는 이 중 그래픽 이퀄라이저를 구현할 예정이다. 참고로 상단의 그림은 파라메트릭 EQ인데, 그냥 이미지가 더 멋있어서 넣었다. 참고로 그래픽 EQ는 이렇게 생겼다.
 짙은 아날로그의 향수가 풍겨오는 그래픽 EQ의 비주얼
짙은 아날로그의 향수가 풍겨오는 그래픽 EQ의 비주얼
두 개의 EQ 모두 장단점이 존재하는데, 일단 그래픽 EQ의 장점은 파라메트릭 EQ에 비해 조절할 수 있는 주파수 대역의 수가 많고 직관적인 인터페이스를 가지고 있다는 것이다. 여러분은 이 단락의 맨 위에 첨부된 파라메트릭 EQ 이미지를 보고 “엥? 파라메트릭도 나름 직관적인데?”라고 하실 수 있는데, 원래 하드웨어 파라메트릭 EQ는 이렇게 생겼다.
 까만 것은 노브요. 하얀 것은 숫자로다.
까만 것은 노브요. 하얀 것은 숫자로다.
그래서 그래픽 EQ는 보통 빠른 대응이 필요한 공연장같은 곳에서 많이 사용되고 있으며, 짬이 많이 쌓인 시니어 사운드 엔지니어들은 공연장에서 하울링(노래방에서 삐- 하며 가끔 나는 날카로운 소리)이 발생하면 바로 해당 주파수를 캐치해서 그래픽 EQ로 죽여버리는 무서운 스킬을 가지고 있다.
그래픽 EQ의 단점은 조절할 수 있는 주파수 대역이 정해져 있다는 것과 주파수의 세밀한 조정이 힘들다는 것이다. 반면 파라메트릭 EQ는 그래픽 EQ와 다르게 조절할 수 있는 주파수 대역까지 모두 정해줄 수 있다.
그러나 한번에 조절할 수 있는 주파수의 개수는 그래픽 EQ에 비해 크게 부족하다. 일반적인 파라메트릭 EQ가 3-5개의 주파수 대역을 조절할 수 있는 반면에 그래픽 EQ는 한번에 조절 가능한 주파수가 40개가 넘어가는 굇수도 존재한다.
필자 생각에 하드웨어 파라메트릭 EQ의 최대 단점은 바로 직관적이지 않은 인터페이스를 가지고 있다는 것인데, 이 단점은 소프트웨어로 구현하면 UI로 커버할 수 있는 영역이기도 하고 대부분의 녹음실에서는 즉각적인 대응보다는 계속 소리를 들어보면서 이퀄라이징을 할 수 있는 상황이 대부분이기 때문에 많은 소프트웨어 EQ가 주파수 대역 조절에 자유도가 높은 파라메트릭 EQ로 구현된다.
하지만 필자가 만드는 데모처럼 간단히 구현해보는 상황에서는 저 위에 하드웨어 파라메트릭 EQ와 비슷한 UI로 구현될 것이 뻔하므로 필자는 상대적으로 UI 만들기가 쉬운 그래픽 EQ를 선택했다.(이 말이 잘 이해가 안된다면 EQ 챕터의 가장 위에 첨부한 파라메트릭 EQ를 한번 보고 오자)
위에서 한번 이야기했듯이 EQ는 필터를 사용하여 구현하므로 그렇게 복잡하지 않다. 그럼 이제 한번 간단하게 뚝딱 만들어보도록 하자.
그래픽 EQ 구현하기
위에서 그래픽 EQ 이미지를 봤다면 알겠지만 이 친구는 조절할 수 있는 주파수 대역의 개수가 정해져 있는 장비이다. 그렇기 때문에 필자도 조절할 수 있는 주파수가 들어있는 배열을 하나 선언하고 이 배열을 이터레이션하면서 필터들을 생성할 것이다.
const frequencies = [
25, 31, 40, 50, 63, 80, 100, 125, 160, 200,
250, 315, 400, 500, 630, 800, 1000, 1250, 1600, 2000,
2500, 3150, 4000, 5000, 6300, 8000, 10000, 12500, 16000, 20000
];이때 주의해야할 점이 있다. EQ는 여러 개의 필터를 사용하기 때문에 각 필터를 서로 체이닝해서 연결해주어야한다. 이때 필터의 게인이 1보다 조금이라도 높다면 한번 필터를 통과할 때마다 소리가 조금씩 증폭되어 여러분의 귀에 들어올 때 쯤이면 엄청 큰 소리가 되어 여러분의 고막을 영원히 이별시킬 수도 있다.
🚨 그렇기 때문에 반드시 필터들의 게인을 0 이하로 설정해주어야 한다.
const inputNode = audioContext.createGain();
sourceNode.connect(inputNode);
const filters = frequencies.map((frequency, index, array) => {
const filterNode = audioContext.createBiquadFilter();
filterNode.gain.value = 0;
filterNode.frequency.setValueAtTime(frequency, audioContext.currentTime);
if (index === 0) {
filterNode.type = 'lowshelf';
}
else if (index === array.length - 1) {
filterNode.type = 'highshelf';
}
else {
filterNode.type = 'peaking';
}
return filterNode;
});
filters.reduce((prev, current) => {
prev.connect(currentNode);
return currentNode;
}, inputNode);
const outputNode = audioContext.createGain();
filters[filters.length - 1].connect(outputNode);
outputNode.connect(audioContext.destination);map 메소드 내부의 if 문을 보면 해당 첫번째 필터와 마지막 필터의 타입만 다르게 주고 있는 것을 볼 수 있는데, 이는 Shelf 타입의 필터를 사용하여 첫번째 필터의 주파수보다 낮은 주파수와 마지막 필터의 주파수보다 높은 주파수까지 모두 커버하기 위해서이다. (필터 타입이 잘 기억나지 않는다면 Filter 부분을 다시 보고 오자)
그 후 생성된 필터를 reduce 메소드를 통해 모두 체이닝해주고 outputNode와도 연결해주었다. 여기까지 작성한 후 sourceNode를 재생시켜보면 아무 변화도 없는 것을 알 수 있다.
당연히 모든 필터의 게인이 0이기 때문에 아무런 변화가 없는 것이다. 이때 저 필터들의 값을 -1 ~ 1사이의 랜덤한 난수로 할당하면 소리가 조금씩 변하는 것을 들어볼 수도 있다. 필자는 개인적으로 input[type="range"] 엘리먼트와 연동하여 필터들의 게인을 조절할 수 있도록 만들고 직접 이것저것 만져보는 것을 추천한다.
또한 가장 낮은 주파수와 높은 주파수의 필터를 Shelf 타입으로 설정했기 때문에 이 필터들의 게인을 낮추면 Lowpass 필터나 Highpass 필터와 같은 효과도 낼 수 있다.
마치며
자, 여기까지 대표적으로 많이 사용하는 이펙터들인 컴프레서, 리버브, 딜레이, 필터, EQ를 만들어보았다. 사실 이 5개 외에도 재밌는 여러가지 이펙터가 있지만 분량조절 대실패로 인해 여기까지만 노는 것으로 하겠다.
필터를 만들 때 한번 이야기 했듯이 HTML5 Audio API는 굉장히 높은 수준의 추상화된 노드를 제공해주기 때문에 사실 개발자가 직접 구현할 것들이 별로 없다. 이는 다르게 말하면 세밀한 수준의 구현이 힘들다는 뜻이기도 하지만 필자가 무슨 오디오 이펙터 회사를 차릴 것도 아니기 때문에 단순 재미로 만들어보기에는 충분한 것 같다.
이렇게 여러가지 이펙터를 구현해보며 필자도 예전에 사운드 엔지니어로 일할 때의 추억이 새록새록 떠오르기도 했고 또 이펙터에 대해서 새롭게 알게된 내용도 있어서 굉장히 재밌게 작업을 했다. 필자는 포스팅에 작성한 이펙터 외에도 여러가지 이펙터를 계속 구현해볼 예정이므로 관심있는 분들은 필자의 깃허브에서 한번 쓱 둘러보고 PR을 날려도 된다. (좋은 건 나누면 배가 되는 법이다.)
이상으로 JavaScript로 오디오 이펙터를 만들어보자 - 나만의 소리 만들기 포스팅을 마친다.