[번역] 프로그래머를 위한 카테고리 이론 - 7. 펑터
구조를 보존한 채 맥락을 옮기는 매핑의 규칙
![[번역] 프로그래머를 위한 카테고리 이론 - 7. 펑터](/static/eea67acfacfc20db2c9d3f6b3a3a786d/b384d/thumbnail.webp "[번역] 프로그래머를 위한 카테고리 이론 - 7. 펑터")
이번 챕터에서는 펑터(Functor)에 대해서 이야기를 해보려고 한다. 펑터는 간단하지만 매우 강력한 개념이며 카테고리 이론은 이처럼 간단하지만 강력한 아이디어로 가득 차있다.
펑터는 카테고리 간의 매핑이다. 즉, 두 카테고리 와 가 주어졌을 때, 펑터 는 카테고리 의 대상을 카테고리 의 대상으로 매핑하는 것이며, 결국 대상들에 대한 함수라고 볼 수 있다.
만약 카테고리 의 대상을 라고 한다면, 우리는 매핑된 카테고리 의 대상을 라고 표현할 수 있다. 하지만 카테고리는 대상으로만 구성되어있지 않으며 대상과 그들을 연결하는 사상까지 모두 포함하는 개념이다. 즉, 펑터는 대상 뿐 아니라 사상 또한 매핑하며, 이런 경우에는 사상에 대한 함수라고 볼 수도 있다. 그렇다고 펑터가 마음대로 사상을 매핑하는 것은 아니고, 반드시 사상으로 연결된 대상들의 구조를 그대로 보존해야 한다.
만약 카테고리 에 있는 사상 가 대상 와 를 연결하고 있다면,
f :: a -> b펑터를 통해 매핑된 카테고리 에 있는 사상 인 또한 와 동일한 구조로 대상 와 를 연결해야 한다.
F f :: F a -> F b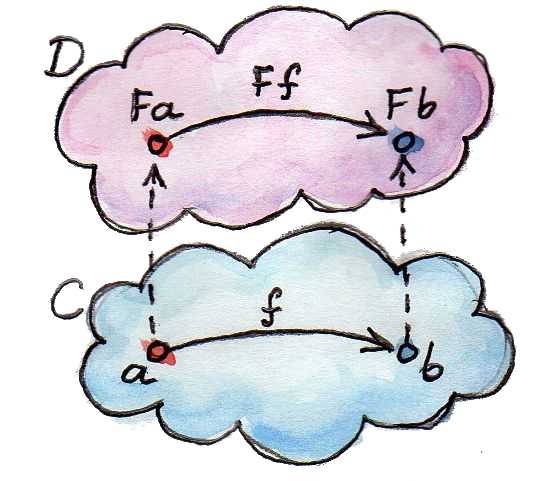
여기서 알 수 있듯이 펑터는 카테고리의 구조를 그대로 보존한다. 한 카테고리 내에서 연결되어있는 것들은 펑터를 통해 매핑된 카테고리에서도 그대로 연결되어 있는 것이다. 이에 더해 카테고리에는 단순히 대상을 사상으로 연결하는 것 뿐 아니라 사상 간의 합성이라는 개념 또한 존재한다.
사상 가 와 의 합성사상인 상황을 생각해보자.
h = g . f그렇다면 펑터 를 통해 만들어진 카테고리의 사상들의 합성 관계도 이와 동일하게 유지된다.
F h = F g . F f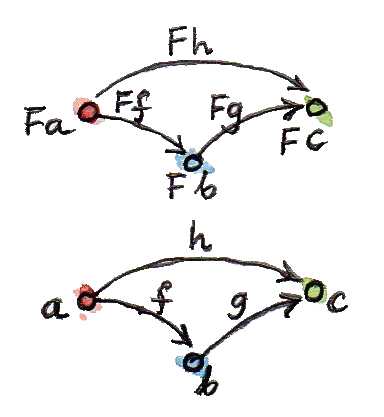
마지막으로 우리는 카테고리 안의 모든 항등사상들이 카테고리 의 항등사상들로 매핑되는 상황 또한 생각해볼 수 있다.
F id_a = id_Fa여기서 는 대상 의 항등사상이며, 는 대상 의 항등사상이다. 이처럼 항상 카테고리의 구조를 보존해야한다는 조건들로 인해 펑터는 일반적인 함수보다 더 제한적인 개념이 된다.

만약 어떤 카테고리를 각 대상들이 사상으로 연결되어있는 일종의 네트워크라고 상상해보자. 펑터는 각 대상과 사상을 그저 매핑하는 개념일뿐이므로 네트워크의 요소들을 서로 분리해내는 것은 절대 불가능하다. 펑터로 대상들을 합칠 수도 있고 여러 사상들을 하나로 붙혀놓을 수도 있겠지만 분해하는 것은 불가능한 것이다.
이와 같이 분해가 불가능하다는 제약은 미적분에서 볼 수 있는 연속성의 조건과 유사하다. 이런 의미에서 펑터는 “연속적”이라고 볼 수도 있다. 또한 마치 정의역과 공역의 관계를 축소나 포함이라는 시각으로 바라보는 것과 유사하게 펑터 또한 동일한 시각으로 바라볼 수 있다. 예를 들면 펑터의 소스가 되는 카테고리가 대상 카테고리보다 더 작을 때는 포함과 같은 개념으로 볼 수 있는 것이다.
한번 극단적인 예시를 생각해보자. 펑터의 소스가 되는 카테고리는 단 하나의 대상과 하나의 항등사상만으로 이루어진 단일대상 카테고리가 될 수도 있다. 이처럼 단일대상 카테고리를 다른 카테고리로 매핑하는 펑터는 단순히 해당 카테고리에서 하나의 대상을 선택하는 것과 다를 게 없다. 이는 단일원소집합에서 하나의 원소를 선택하는 사상의 특성과 완전히 유사하다.
소스 카테고리를 최대한 축소하는 펑터는 상수 펑터(Constant Functor), 로 불린다. 이 펑터는 소스 카테고리의 모든 대상을 대상 카테고리에서 선택된 하나의 대상인 로, 그리고 소스 카테고리의 모든 사상을 항등사상인 로 매핑한다. 이 펑터는 마치 블랙홀처럼 작동하여 모든 것을 하나의 특이점으로 압축해버린다. 우리가 추후 한계(Limits)와 공한계(Colimits)에 대해 이야기할 때 이러한 펑터를 더 자세히 살펴볼 것이다.
💡 역주
작가의 설명만 보면 마치 상수 펑터()가 어떤 카테고리를 다른 카테고리로 매핑하며 압축하는 녀석으로 보일 수 있지만, 사실 상수 펑터는 특정 카테고리를 자기 자신으로 매핑하는 엔도펑터(EndoFunctor)이다. (엔도펑터에 대한 설명은 바로 다음 섹션에 나온다.)
즉, 상수 펑터는 어떤 카테고리의 모든 대상을 그 카테고리 내의 대상 하나로 매핑(압축)하는 개념이라고 보면 된다. 이 과정에서 카테고리의 대상들을 연결하던 임의의 사상들은 모두 선택된 대상의 항등 사상으로 매핑된다.
7.1 프로그래밍에서의 펑터
이제부터는 실질적인 프로그래밍에 대해서 이야기해보자. 이미 우리는 프로그래밍의 세계에서 타입과 함수로 이루어진 카테고리를 다루고 있다. 이번에는 이 카테고리를 자기 자신으로 매핑하는 펑터, 엔도펑터(EndoFunctor)에 대해서 생각해보려고 한다.
자, 타입으로 이루어진 카테고리에서의 엔도펑터는 무엇일까? 이 펑터는 타입을 타입으로 매핑하는 펑터일 것이다. 사실 여러분은 이미 이러한 매핑의 예시를 숱하게 봐왔을테지만 단지 그것이 엔도펑터라는 것을 깨닿지 못 했을 뿐이다. 아래 몇 가지 예시를 한번 살펴보자.
7.1.1 Maybe 펑터
Maybe의 정의는 어떠한 타입 a를 Maybe a라는 타입으로 매핑하는 것이다.
data Maybe a = Nothing | Just a여기서 중요한 포인트가 하나 있다. Maybe 자체는 타입이 아니라 타입 생성자(Type Constructor)라는 것이다. 타입 생성자를 타입으로 변환하기 위해서는 Int나 Bool과 같은 타입 인자를 생성자에게 제공해야 한다. 즉, 아무 인자로 받지 않는 Maybe는 타입에 대한 함수를 나타내는 것이다.
그렇다면 Maybe를 펑터로 변환해볼 수 있을까? (프로그래밍 맥락에서 펑터에 대해 이야기할 때는 거의 항상 엔도펑터를 이야기한다는 사실을 유념하자.) 펑터는 대상(타입)의 매핑 뿐만 아니라 사상(함수)의 매핑도 모두 포함하는 개념이다. 한번 a에서 b로 나아가는 임의의 함수 f가 있다고 생각해보자.
f :: a -> b우리는 Maybe a에서 Maybe b로 나아가는 함수를 생성하고 싶다. 이러한 함수를 제대로 정의하기 위해서는 Maybe를 구성하는 두 생성자인 Nothing과 Just에 대해 고려해야한다.
Nothing의 경우에는 그저 Nothing을 반환해주기만 하면 되니 간단하다. 그리고 인자가 Just인 경우에는 함수 f를 Just가 가지고 있는 값에 적용해주면 될 것이다.
즉, Maybe라는 펑터를 거친 f의 모습은 아래와 같은 함수가 된다. (Haskell에서는 변수명에 아포스트로피(’)를 사용할 수 있으며, 이 기능은 아래와 같은 경우에 매우 편리하다.)
f' :: Maybe a -> Maybe b
f' Nothing = Nothing
f' (Just x) = Just (f x)Haskell에서는 펑터가 사상을 매핑하는 행위를 fmap이라는 고차함수로 구현하며, Maybe의 경우에는 아래와 같은 정의가 될 것이다.
fmap :: (a -> b) -> (Maybe a -> Maybe b)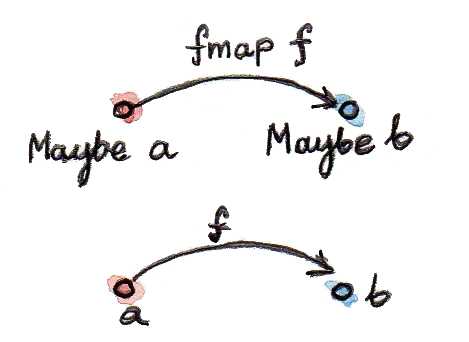
우리는 종종 fmap이 함수를 리프트(lift)한다고 말한다. 이렇게 리프팅된 함수는 이제 Maybe 타입의 값에 작용하는 함수가 되었다.
또한 커링(Currting)으로 인해 위 정의는 하나의 함수 a → b를 받아서 다른 함수 Maybe a → Maybe b를 반환하는 함수, 그리고 a → b와 Maybe a라는 두 개의 인자를 받아 Maybe b를 반환하는 함수, 총 두 가지 방식으로 해석될 수 있다.
fmap :: (a -> b) -> Maybe a -> Maybe b이러한 특성들을 기반으로 Maybe에 대한 fmap을 구현해보면 아래와 같다.
fmap _ Nothing = Nothing
fmap f (Just x) = Just (f x)
-- 적용할 함수 f와 Just x를 인자로 받아,
-- Just가 가진 값에 함수 f가 적용된 꼴인 Just (f x)를 반환한다.우리가 Maybe 타입 생성자와 fmap 함수가 펑터를 형성한다는 것을 보이기 위해서는 fmap 함수가 항등과 합성의 개념을 보존한다는 것을 증명해야한다. 이러한 것들을 “펑터 법칙(The Functor Laws)”이라는 거창한 이름으로 부르긴 하지만 사실은 그저 펑터가 카테고리의 구조를 보존한다는 것을 보장해야한다는 의미이다.
7.1.2 방정식 추론(Equational Reasoning)
펑터 법칙을 증명하기 위해 방정식 추론(Equational Reasoning)을 사용해보려고 한다. 이는 Haskell에서 흔하게 사용되는 증명 기법인데, Haskell 함수가 좌변이 우변과 같다는 동등성(Equality)으로 정의된다는 사실을 이용하는 기법이다. 어떤 코드를 동작이 동일한 다른 코드로 대체할 수도 있고 변수명의 충돌을 피하기 위해 변수명을 변경할 수도 있는데, 이는 함수를 인라인화하는 행위나 반대로 표현식을 함수로 리팩토링하는 행위로 생각할 수도 있다. 한번 항등함수를 예시로 살펴보자.
id x = x이러한 함수가 존재한다면 이제 우리는 어떤 표현식에서 id y를 보았을 때, 이 코드를 y로 바꿔볼 수 있다(인라인화). 더 나아가서 id (y + 2)와 같이 id가 표현식에 적용되어있다면 이를 표현식 그 자체인 (y + 2)로 바꿀 수도 있다. 또한 이 치환은 양방향으로 적용되기 때문에 표현식 e를 id e로 치환할 수도 있다.(리팩토링)
함수가 패턴 매칭에 의해 정의된 경우, 각각의 하위 정의를 독립적으로 사용할 수도 있다. 예를 들어 위의 fmap 정의에서 fmap f Nothing을 Nothing으로 바꿀 수 있으며, 반대로도 가능하다. 이제 이 개념이 실제로 어떻게 작동하는지를 살펴보자. 먼저 항등 보존을 살펴보겠다.
fmap id = id우리는 Nothing과 Just라는 두 가지 케이스를 고려해야한다. 먼저 첫 번째 경우를 살펴보겠다. 왼쪽의 항을 오른쪽 항으로 변환하기 위해 Haskell 문법의 Pseudo Code를 사용하겠다.
fmap id Nothing
= { fmap의 정의에 의하면 }
Nothing
= { id의 정의에 의하면 }
id Nothing가장 마지막 단계에서는 id의 정의를 활용하여 표현식 Nothing을 id Nothing으로 대체했다. 실제로는 양 끝에서 촛불을 태우는 방식과 유사하게 이러한 증명을 수행해나가며, 중간에서 동일한 표현식을 만날 때까지 진행하게 된다. 위 케이스에서는 세 번째 라인의 Nothing이 이에 해당한다.
두 번째 경우도 어렵지 않다.
fmap id (Just x)
= { fmap의 정의에 의하면 }
Just (id x)
= { id의 정의에 의하면 }
Just x
= { id의 정의에 의하면 }
id (Just x)이제 항등 보존에 대한 증명이 끝났으니, fmap이 합성을 보존한다는 것도 표현해보자.
fmap (g . f) = fmap g . fmap f첫 번째 Nothing의 케이스이다.
fmap (g . f) Nothing
= { fmap의 정의에 의하면 }
Nothing
= { fmap의 정의에 의하면 }
fmap g Nothing
= { fmap의 정의에 의하면 }
fmap g (fmap f Nothing)그리고 두 번째 케이스인 Just에 대해서는 이렇게 표현한다.
fmap (g . f) (Just x)
= { fmap의 정의에 의하면 }
Just ((g . f) x)
= { 합성의 결합법칙에 의하면 }
Just (g (f x))
= { fmap의 정의에 의하면 }
fmap g (Just (f x))
= { fmap의 정의에 의하면 }
fmap g (fmap f (Just x))
= { 합성의 결합법칙에 의하면 }
(fmap g . fmap f) (Just x)💡 역주
이러한 추론 방식이 조금 어색하게 느껴지는 독자 분들도 계실텐데, 사실 위 예시에 작성된 모든 코드들은 모두 같은 동작을 하는 코드이다.
방정식 추론이라는 말이 어려워보여서 그렇지 결국은
x,x + 0이 동형(Isomorphic)임을 밝혀나가는 노가다와 유사하다.const addZero = (x: number) => x + 0; const identify = <T>(v: T) => v;identify(addZero(x)); = { identify의 정의에 의하면 } addZero(x) = { addZero의 정의에 의하면 } x = { identify의 정의에 의하면 } identify(x)함수가 참조 투명성을 보장하는 이상 함수를 함수의 본문으로 치환이 가능하기 때문에 이렇게 노가다로 정합성을 확인해나가는 행위가 가능한 것이다.
이와 같은 방정식 추론을 사용할 때는 이 추론 방법이 사이드 이펙트를 가진 C++ 스타일의 함수에 대해서는 동작하지 않는다는 점을 잘 알아야 한다. 아래 코드를 살펴보자.
int square(int x) {
return x * x;
}
int counter() {
static int c = 0;
return c++;
}
double y = square(counter());방정식 추론을 사용하면 square를 인라인화하여 아래와 같은 정의를 얻을 수 있다.
double y = counter() * counter();이는 확실히 유효한 변환이 아니며 매번 동일한 결과를 생성하지도 않을 것이다. 그럼에도 불구하고 매크로를 통해 square를 구현한 경우 C++ 컴파일러는 방정식 추론을 시도할 것이고, 그 결과는 참혹할 것이다.
7.1.3 Optional
물론 Haskell을 사용하여 펑터를 쉽게 정의할 수 있기는 하지만, 사실 꼭 Haskell이 아니더라도 제네릭 프로그래밍과 고차함수를 지원하는 어떤 언어든 펑터를 정의할 수 있다. C++의 Maybe에 해당하는 템플릿 타입 optional을 생각해보자. 아래는 optional 구현에 대한 스케치이다. (실제 구현은 인수가 전달될 수 있는 여러가지 방법, Deep Copy/Shallow Copy와 같은 Copy Semantics, C++ 특유의 자원 관리 문제 등 을 고려해야하기 때문에 훨씬 더 복잡하다.)
template<class T>
class optional {
bool _isValid; // the tag
T _v;
public:
optional() : _isValid(false) {} // Nothing
optional(T x) : _isValid(true) , _v(x) {} // Just
bool isValid() const { return _isValid; }
T val() const { return _v; } };이 템플릿은 타입 T를 새로운 타입 optional<T>로 매핑하여 펑터의 정의 중 하나인 타입에 대한 매핑을 제공한다. 이제 함수에 대한 동작을 정의해보자.
template<class A, class B>
std::function<optional<B>(optional<A>)>
fmap(std::function<B(A)> f) {
return [f](optional<A> opt) {
if (!opt.isValid())
return optional<B>{};
else
return optional<B>{ f(opt.val()) };
};
}이것은 함수를 인자로 받고 다시 함수를 반환하는 고차함수이다. 커링되지 않는 버전은 다음과 같다.
template<class A, class B>
optional<B> fmap(std::function<B(A)> f, optional<A> opt) {
if (!opt.isValid())
return optional<B>{};
else
return optional<B>{ f(opt.val()) };
}이외에 fmap을 optional의 템플릿 메서드로 만드는 선택지도 있다. 이처럼 다양한 선택지들은 C++에서 펑터 패턴을 추상화하는 난이도를 더 높히는 주범이다. 펑터를 상속할 수 있는 인터페이스로 정의해야할까? 펑터는 커링된 함수인가 아니면 커링되지 않은 프리 템플릿 함수인가? C++ 컴퍼일러는 누락된 타입을 올바르게 추론할 수 있을까, 아니면 우리가 직접 명시적으로 지정해줘야 하는걸까?
한번 입력 함수 f가 int를 받아 bool을 반환한다고 생각해보자. 이 경우에 컴파일러는 g의 타입을 어떻게 결정할까?
auto g = fmap(f);특히 fmap을 오버로딩하는 여러 가지 펑터가 있는 경우에는 어떻게 될까? (곧 우리는 더 많은 펑터들을 만나게 될 것이다)
7.1.4 타입 클래스(Typeclasses)
그렇다면 Haskell이 펑터를 추상화하는 방법은 무엇일까? 이를 위해서 Haskell은 타입 클래스 매커니즘을 사용한다. 타입 클래스는 공통 인터페이스를 지원하는 타입의 집합을 정의한다. 예를 들어, 동등성을 지원하는 객체들의 클래스는 아래와 같이 정의된다.
class Eq a where
(==) :: a -> a -> Bool이 정의는 타입 a가 Eq 클래스의 멤버인 경우, 타입 a가 두 인자를 받아 Bool을 반환하는 == 연산자를 지원한다는 것을 나타낸다.
만약 Haskell에게 특정 타입이 Eq 타입 클래스의 인스턴스라는 것을 알려주고 싶다면, 먼저 이 클래스의 인스턴스로 선언하고 ==의 구현을 제공해줘야 한다. 예를 들어 두 개의 Float로 이루어진 곱 타입인 2D Point 타입의 정의가 주어졌다고 생각해보자.
data Point = Pt Float Float우리는 각 점의 동등성을 이렇게 정의해볼 수 있다.
instance Eq Point where
(Pt x y) == (Pt x' y') = x == x' && y == y'여기서는 두 개의 패턴 (Pt x y)와 (Pt x’ y’)에게 중위 연산자 ==를 사용해보았다. 함수의 본문은 단일 등호를 보면 이해가 쉽다. 이처럼 Point가 Eq의 인스턴스로 선언된다면 이제 직접적으로 연산자를 통해 각 점의 동등성을 비교할 수 있다.
Haskell에서는 C++이나 Java와는 다르게 Point를 정의할 때, 이 타입이 직접 Eq클래스의 멤버라는 것을 명시할 필요는 없으며, 이는 추후 사용자가 직접 작성하는 클라이언트 코드에서 작성할 수 있다. 이러한 타입 클래스는 Haskell에서 함수나 연산자를 오버로딩할 수 있는 유일한 방법이다.
다양한 펑터들에서 fmap의 동작을 오버로딩하여 활용하기 위해서는 이와 같은 타입 클래스 기법이 필요하다. 그러나 한 가지 복잡한 점이 있다. 펑터는 타입으로 정의되는 것이 아니라 타입들의 매핑인 타입 생성자로 정의된다. 즉, 펑터를 제대로 정의하기 위해서는 Eq의 경우처럼 타입들의 집합이 아닌 타입 생성자들의 집합으로 정의된 타입 클래스가 필요하다는 것이다. 다행히도 Haskell의 타입 클래스는 타입 뿐만 아니라 타입 생성자 또한 잘 지원해준다. 그럼 이제 Functor 클래스를 한번 정의해보자.
class Functor f where
fmap :: (a -> b) -> f a -> f b이 코드는 f가 Functor인 경우, 지정된 타입 시그니처를 가진 함수 fmap을 가지고 있다는 사실을 명시하고 있다. 여기서 소문자 f는 타입 변수이며, 타입 변수 fmap이 받고 있는 a나 b와 동일한 개념이다.
컴파일러는 f a나 f b와 같이 이 타입 변수가 다른 타입을 처리하고 있다는 사실을 참고하여 f가 타입이 아닌 타입 생성자라는 사실을 추론할 수 있다. 따라서 Functor의 인스턴스를 선언할 때는 Maybe와 같은 타입 생성자를 지정해줘야 한다.
instance Functor Maybe where
fmap _ Nothing = Nothing
fmap f (Just x) = Just (f x)사실 우리가 정의한 Functor 클래스, 그리고 Maybe와 같이 간단한 데이터 타입에 대한 인스턴스 정의들은 이미 표준 Prelude에 포함되어있다.
7.1.5 C++에서의 펑터(Functor in C++)
그렇다면 C++에서도 이와 동일한 접근 방식을 시도해볼 수 있을까? 타입 생성자는 optional과 같은 템플릿 클래스에 해당하므로, fmap을 템플릿 템플릿 매개변수 F로 매개화해볼 수 있을 것이다.
template<template<class> F, class A, class B>
F<B> fmap(std::function<B(A)>, F<A>);이제 이 템플릿을 다른 펑터들에 대해서 특수화(Specialize)하면 좋을 것 같다. 하지만 슬프게도 C++에서는 템플릿 함수의 부분 특수화를 금지하고 있기 때문에 아래처럼 작성할 수가 없다.
template<class A, class B>
optional<B> fmap<optional>(std::function<B(A)> f, optional<A> opt)대신 우리는 함수 오버로딩을 사용할 것이다. 이렇게 되면 우리는 다시 커링되지 않은 펑터의 원래 정의로 돌아가게 된다.
template<class A, class B>
optional<B> fmap(std::function<B(A)> f, optional<A> opt) {
if (!opt.isValid())
return optional<B>{};
else
return optional<B>{ f(opt.val()) };
}이제 fmap의 두 번째 인자가 오버로드를 선택하기 때문에 이 정의 자체가 작동하기는 하지만, 이러한 방법은 fmap의 일반적인 정의에서는 많이 벗어나있다.
7.1.6 List 펑터
프로그래밍에서 펑터가 어떤 역할을 하는지에 대해 감을 잡기 위해서는 조금 더 많은 예제를 살펴봐야할 것 같다. 다른 타입으로 매개화된 어떤 타입이든 모두 펑터의 후보라고 볼 수 있다. 제네릭 컨테니어는 저장된 요소의 타입에 의해 매개화되므로, 매우 간단한 컨테이너인 List를 한번 살펴보자.
💡 역주
제네릭 컨테이너는 여러 타입의 데이터를 저장할 수 있는 데이터 컨테이너이다. 즉, 타입 파라미터를 받음으로써 동일한 구조를 유지하면서도 서로 다른 유형의 데이터를 저장할 수 있는 것이다. TypeScript에서는
Array<T>와 같은 타입이 일종의 제네릭 컨테이너라고 볼 수 있다.
data List a = Nil | Cons a (List a)여기 List라는 타입 생성자가 있다. 이 타입 생성자는 임의의 타입 a를 타입 List a로 매핑한다. 이때 List가 펑터라는 것을 보이기 위해서는 함수 a → b가 주어졌을 때 함수 List a → List b로 나아가는 리프팅 함수를 정의해야 한다.
fmap :: (a -> b) -> (List a -> List b)List a에 작용하는 함수는 두 리스트 생성자인 Nil과 Cons 두 가지 경우를 고려해야한다. Nil의 경우에는 어차피 빈 리스트에 대해서 할 수 있는게 없으니, 그냥 Nil을 반환해주면 되므로 간단하게 처리가 가능하다.
그러나 Cons 케이스의 경우에는 약간 까다롭다. 왜냐하면 재귀를 포함해야하기 때문이다. 일단 잠시 생각을 멈추고 우리가 정확히 어떤 것을 하려고 하는 것인지 다시 살펴보자. fmap의 인자로 a의 리스트, 그리고 a를 b로 변환하는 함수 f가 주어졌고, 이제 이것들을 가지고 b의 리스트를 생성해야한다.
리스트의 각 요소를 a에서 b로 변환하는 것은 당연하게도 f를 사용하면 된다. 다만 비어있지 않은 리스트는 하나의 원소가 아닌 Cons로 표현되는 헤드(Head)와 나머지 꼬리(Tail)로 구성될텐데, 어떻게 모든 원소에 f를 적용해야 하는걸까?
우리는 f를 헤드에 먼저 적용하고, 리프팅한(fmap한) f를 나머지 꼬리에 적용할 것이다. 이는 리프팅된 f를 또 다시 리프팅한 f로 정의하고 있기 때문에 재귀적인 정의가 된다.
fmap f (Cons x t) = Cons (f x) (fmap f t)💡 역주
Haksell에 익숙하지 않은 독자들을 위해 조금 더 읽기 쉬운 변수명으로 바꿔보면 다음과 같다.
fmap 원소에적용할fn (Cons 헤드원소 나머지테일) = Cons (원소에적용할fn 헤드원소) (fmap 원소에적용할fn 나머지테일)이를 TypeScript로 다시 작성해보자면 대략 이런 느낌이다.
// List 펑터 인터페이스 interface List<T> { fmap<U>(fn: (value: T) => U): List<U>; } class Cons<T> implements List<T> { constructor(public head: T, public tail: List<T>) {} fmap<U>(fn: (value: T) => U): List<U> { // 헤드에 fn를 적용해서 T를 U로 변경 // 이후 꼬리(List)가 가진 fmap을 호출하여 같은 행위를 재귀적으로 반복한다. return new Cons<U>(fn(this.head), this.tail.fmap(fn)); } }Haksell은
Cons (f x)나(fmap f t)와 같은 패턴매칭을 통해 헤드에 적용할 동작과 꼬리에 적용할 동작을 구분하지만, TypeScript는 그런 패러다임을 가진 언어가 아니기 때문에 직접this를 통해 원하는 동작을 호출하고 있다.
우항의 fmap f 구문은 정의하려는 리스트보다 더 짧은 리스트, 즉, 꼬리에 적용된다. 결국 점점 더 짧은 리스트로 재귀하다가 결국 최종적으로는 빈 리스트인 Nil에 도달하게 될 것이다.
앞서 정의한대로 fmap f가 Nil에 적용되면 재귀가 종료된다. 최종 결과를 얻으려면 새로운 헤드 (f x)와 새로운 꼬리 (fmap f t)를 Cons 생성자를 통해 결합한다. 지금까지 이야기한 모든 내용을 하나로 합쳐보면 아래와 같이 List 펑터의 인스턴스 선언이 된다.
instance Functor List where
fmap _ Nil = Nil
fmap f (Cons x t) = Cons (f x) (fmap f t)만약 여러분이 C++에 익숙하다면, 일반적인 C++ 컨테이너인 std::vector를 한번 생각해보면 된다. std::vector에 대한 fmap의 구현은 단순히 std::transform의 얇은 캡슐화에 불과하다.
template<class A, class B>
std::vector<B> fmap(std::function<B(A)> f, std::vector<A> v) {
std::vector<B> w;
std::transform( std::begin(v)
, std::end(v)
, std::back_inserter(w)
, f);
return w;
}이를 사용하면 숫자 시퀀스인 원소를 제곱하는 등의 행위가 가능하다.
std::vector<int> v{ 1, 2, 3, 4 };
auto w = fmap([](int i) { return i*i; }, v);
std::copy( std::begin(w)
, std::end(w)
, std::ostream_iterator(std::cout, ", "));대부분의 C++ 컨테이너는 std::transform에 전달할 수 있는 이터레이터를 구현함으로써 펑터가 되며, 이는 fmap의 원시적인 버전과도 같다. 그러나 안타깝게도 이터레이터와 임시 개체(Temporaries)의 혼란스러움으로 인해 펑터의 단순함이 상당 부분 사라져버린다(위의 fmap 구현을 참조해보자). 하지만 새롭게 제안된 range 라이브러리는 특정한 범위 내에서 펑터적인 성질을 더 명확하게 표현해주고 있다.
7.1.7 Reader 펑터
여기까지 봤다면 이제 펑터가 어떤 컨테이너의 한 종류인 것 같다는 생각을 가지게 되었을 것이라 생각한다. 그렇다면 이제는 그 생각을 깨버리기 위해 지금까지와 매우 다른 것처럼 보이는 예제를 보여주려고 한다. 타입 a를 a를 반환하는 함수로 매핑하는 상황을 생각해보자.
아직 함수 타입에 대한 깊이 있는 이야기를 나누지는 않았지만, 사실 프로그래머라면 함수에 대한 기본적인 이해 정도는 가지고 있다. Haskell에서 함수 타입은 두 개의 타입과 화살표 타입 생성자(->)를 사용하여 구성된다. 이 생성자는 인수 타입, 그리고 결과 타입이라는 두 가지 타입 사이의 중위 표현으로 등장한다. 기본적으로는 a -> b의 형태이지만 괄호를 사용하면 전위 표현으로도 사용이 가능하다.
(->) a b정규 함수와 마찬가지로 하나 이상의 인수를 가진 타입 함수는 부분적용이 가능하다. 따라서 아래 예시와 같이 화살표에 하나의 타입 인수만 제공한다면 결과 타입을 의미하는 다른 인수가 들어오는 것을 기다릴 수 있다는 것이다.
(->) a이것이 바로 위 표현이 타입 생성자인 이유이다. a -> b 를 완전한 타입으로 만들기 위해서는 타입 b까지 제공되어야 하기 때문이다. 즉, 위 예시는 타입 a를 매개변수로 사용하는 타입 생성자 집합을 정의하고 있다고 볼 수 있다.
그렇다면 이제 이 케이스가 펑터가 맞는지 살펴보도록 하자. 두 개의 타입 매개변수를 다루는 것은 어려울 수 있으니 이름을 조금 변경해보겠다. 이전에 정의했던 펑터의 정의와 일치하도록 인수의 타입을 r로, 결과 타입을 a로 지정해보겠다.
즉, 이 타입 생성자는 임의의 타입 a를 r -> a 타입으로 매핑하는 녀석이다. 이것이 펑터가 되려면 함수 a -> b, 함수 r -> a를 인자로 받고 함수 r -> b를 반환하는 함수로 리프팅해야 한다. 이들은 각각 타입 생성자(->) r이 작용하는 타입 a와 b를 사용하여 형성된 타입이다.
이제 이 케이스를 표현할 수 있는 fmap의 정의를 살펴보자.
fmap :: (a -> b) -> (r -> a) -> (r -> b)우리는 함수 f::a -> b와 함수 g::r -> a가 주어졌을 때 함수 r -> b를 생성해야하는 퍼즐을 풀어야 한다. 두 함수를 합성할 수 있는 방법은 오직 하나 뿐이며, 결과 또한 우리가 원하는 방향과 정확히 일치한다. 따라서 fmap의 구현은 아래와 같을 것이다.
instance Functor ((->) r) where
fmap f g = f . g💡 역주
g::r → a,f::a → b가 합성됨으로써r → a → b, 즉r → b가 성립된다.
굉장히 간결하지만 우리가 원하는 동작은 정확히 구현되었다. 만약 더 간결한 표기를 선호한다면, 함수 합성에 대한 표현을 전위 표기법으로 바꿔볼 수도 있다.
fmap f g = (.) f g그리고 인수를 생략해서 fmap과 함수 합성을 의미하는 . 연산자, 두 함수의 직접적인 동등성을 표현할 수도 있다.
fmap = (.)이처럼 (->) r 타입 생성자와 fmap 구현의 결합을 Reader 펑터라고 한다.
7.2 컨테이너로써의 펑터
지금까지 프로그래밍 언어에서 일반적인 용도의 컨테이너를 정의하는 펑터의 몇 가지 예시를 살펴보았다.
우리는 보통 함수를 일종의 데이터라고 생각하지않기 때문에 Reader 펑터같은 녀석들이 조금 어색해보이기도 한다. 그러나 순수함수는 메모이제이션될 수 있으며 함수의 실행은 일종의 테이블 조회 행위로 변환될 수도 있다. 그리고 테이블은 데이터이다.
💡 역주
함수의 실행을 일종의 테이블 조회 행위로 변환할 수 있다는 말은 어떤 함수가 순수하고 불변적이며 입력에 따라 항상 같은 출력을 반환한다는 가정을 전제로 하는 설명이다.
위와 같은 전제가 지켜진다면 함수의 실행 결과를 테이블에 저장하고 함수의 입력 값을 키로 사용하여 함수의 실행 결과를 “검색”할 수 있다.
이러한 메모이제이션에 사용되는 자료구조가 꼭 테이블이어야만 하는 것은 아니지만, 작가는 순수한 함수의 이러한 특성으로 인해 순수함수의 실행이 일종의 데이터 조회 행위가 될 수 있다는 사실을 강조하고 있는 것이다.
반대로 Haskell의 게으른 평가(지연평가) 때문에 전통적인 컨테이너인 리스트는 함수로 구현될 수도 있다. 예를 들어 자연수의 무한한 리스트는 아래와 같이 간결하게 정의할 수 있다.
nats :: [Integer]
nats = [1..]첫 번째 라인의 대괄호 쌍은 Haskell의 리스트에 대한 내장 타입 생성자이다. 두 번째 라인의 대괄호는 리스트 리터럴을 만드는 데 사용된다.
당연하겠지만 이런 방식의 무한 리스트는 메모리에 저장할 수 없다. 그래서 필요할 때마다 Integer를 생성하는 함수로 이러한 동작을 구현하는 것이다. Haskell은 사실상 데이터와 코드 사이의 구분을 명확하게 하지 않는다. 리스트는 함수로 간주될 수도 있고, 함수는 인수를 결과에 매핑하는 테이블로 간주될 수도 있다. 특히 후자는 함수의 정의역이 유한하고 크기가 크지 않은 경우에는 꽤나 실용적인 개념이다.
그러나 strlen을 테이블 조회로 구현하는 것은 현실적이지 않다. 왜냐하면 무한히 많은 서로 다른 문자열들이 존재하기 때문이다. 프로그래머로써 우리는 무한을 좋아하지 않겠지만, 카테고리 이론에서는 무한을 아침식사처럼 즐기는 방법을 배워볼 수 있다. 모든 문자열의 집합이나 우주의 과거, 현재, 미래의 상태 같이 무한한 것들도 다뤄볼 수 있다는 말이다.
그래서 필자는 펑터 객체(엔도펑터에 의해 생성된 타입의 객체)를 어떤 타입을 가진 값 또는 값들을 추상적으로 가지고 있는 무언가로 생각하는 것을 추천한다. 물리적으로 그 값을 가지고 있지는 않지만 말이다.
💡 역주
여기서 작가가 펑터가 특정 타입의 값을 직접 가지고 있는 것이 아니라 추상적으로 가지고 있다고 표현하는 의미는 다음과 같다. TypeScript의 Array를 예로 들어보자.
const numbers: number[] = [1, 2, 3]; // 숫자 타입의 배열 const doubledNumbers = numbers.map(x => x * 2); // [2, 4, 6]여기서
number[]타입의 배열은 사실 “모든 숫자를 가진 배열”으로 정의되었다고 봐야 한다. 하지만 현재 이 배열이 실제로 모든 숫자를 가지고 있는 것은 아니며, 단지map과 같은 메소드를 사용하여 배열 내부의 값들을 간접적으로 다룰 수 있는 방법만을 제공하고 있다.이러한 방법들을 통해 이 배열은 이론상 모든 숫자를 가질 수 있겠지만, 실제로 이 배열이 모든 숫자를 가지고 있는 것은 아니기에 “추상적으로 가지고 있다”라는 표현을 사용한 것이다.
C++에서의 예시를 보자면 std::future가 있다. 언젠가는 값을 가지게 될테지만 반드시 그렇다는 보장은 없으며, Future 내부의 값에 접근하려면 다른 스레드의 실행이 완료될 때까지 기다려야할 수도 있다.
또 다른 예시로는 Haskell의 IO 객체가 있다. 이 객체는 사용자의 입력을 받거나 “Hello World!”가 모니터에 표시된 우주의 상태를 포함할 수도 있다.
이러한 해석들에 따르면 펑터 객체는 매개변수화된 타입의 값을 포함하거나 그런 값을 생성하는 방법을 포함하고 있는 무언가로 바라볼 수 있다. 펑터 내부의 값에 접근하는 동작은 완전히 선택사항이며 펑터의 범위에 꼭 포함되어야 하는 동작도 아니다. 우리가 관심을 가져야하는 부분은 함수를 사용해서 그 값을 조작할 수 있다는 것 뿐이다.
만약 그 값에 접근할 수 있다면 그 조작에 대한 결과를 볼 수 있어야 한다. 그러나 접근할 수 없다면 우리가 오직 신경써야하는 것은 그 조작들이 올바르게 합성되었는지, 그리고 항등 함수를 통한 조작은 아무것도 바꾸지 않는다는 사실 뿐이다. 펑터 객체 내부의 값에 접근하는 것이 그렇게 중요한 일이 아니라는 것을 보여주기 위해 한 가지 예시를 보여주겠다. 여기 인자 a를 완전히 무시하는 타입 생성자가 있다.
data Const c a = Const cConst 타입 생성자는 c와 a 두 개의 타입을 받는다. 화살표 생성자 때와 마찬가지로 이를 부분적으로 적용해서 펑터를 만들어볼 것이다. Const라고 하는 데이터 생성자는 c 타입의 값 하나만을 취하며, 이는 a에 대한 의존성이 없다는 것을 의미한다. 이 타입 생성자에 대한 fmap의 타입 정의는 아래와 같다.
fmap :: (a -> b) -> Const c a -> Const c b펑터가 타입 인수를 무시하고 있기 때문에, fmap의 구현에서도 함수 인수를 무시할 수 있다. 함수에 적용할 대상 자체가 없기 때문이다.
instance Functor (Const c) where
fmap _ (Const v) = Const v오히려 이런 부분은 컴파일 시간에 발생하는 타입 인자와 런타임에 발생하는 값 사이의 더 강한 구분이 있는 C++에서 더 명확하게 나타날 수 있다.
template<class C, class A>
struct Const {
Const(C v) : _v(v) {}
C _v;
};C++으로 구현된 fmap 또한 함수의 인자를 무시하고 Const 인자를 본래 값과 함께 다시 캐스팅하는 역할을 수행한다.
template<class C, class A, class B>
Const<C, B> fmap(std::function<B(A)> f, Const<C, A> c) {
return Const<C, B>{c._v};
}당장 이해하기는 어려울 수 있지만 사실 Const 펑터는 많은 구조들에서 굉장히 중요한 역할을 담당한다. 카테고리 이론에서 Const 펑터는 앞서 언급했던 블랙홀의 엔도펑터, 즉, 펑터의 특수한 경우이다. 추후 이러한 개념에 대해서도 더 자세히 다뤄보도록 하겠다.
7.3 펑터 합성(Functor Composition)
펑터가 마치 함수와 같이 합성될 수 있다라는 것은 꽤 직관적인 이해가 가능한 사실이다. 결국 두 펑터의 합성이라는 것은 펑터가 특정 카테고리 내의 객체나 사상에 매핑되는 행위들의 합성이라고 볼 수 있다.
합성된 두 개의 펑터를 거치더라도 항등 사상은 그대로 항등 사상으로 남게 되며, 사상들의 합성 규칙은 여전히 동일한 규칙을 가지게 된다. 이는 굉장히 단순하고 간단한 규칙이며, 특히 엔도펑터를 합성하는 것은 더더욱 쉽다. 혹시 maybeTail 함수를 기억하는가?
이 함수를 Haskell의 내장 리스트 구현을 사용해서 다시 작성해보겠다.
maybeTail :: [a] -> Maybe [a]
maybeTail [] = Nothing
maybeTail (x:xs) = Just xs지금까지 Nil로 호출하던 빈 리스트 생성자는 빈 대괄호 쌍인 []으로 대체되었고, Cons 생성자는 중위 연산자 :으로 대체되었다.
maybeTail의 결과는 두 펑터 Maybe, []가 a에 작용하는 형태를 지니고 있다. 만약 여기서 합성된 Maybe 리스트의 원소에 어떤 함수 f를 적용하려고 한다면 어떻게 접근해야할까?
함수가 Maybe 리스트의 원소에 도달하기 위해서는 Maybe와 []라는 두 겹의 펑터를 뚫어야 한다. 가장 먼저 외부의 Maybe를 뚫기 위해 fmap을 사용할 수 있다. 그러나 함수 f는 리스트에 대해서는 작동하지 않기 때문에 이대로 이 함수를 Maybe의 안쪽으로 보낼 수는 없다. 우리는 내부 리스트에서 작동할 (fmap f)를 보내야 한다. 한번 Maybe 리스트의 정수 원소들을 제곱하는 예시를 보도록 하자.
square x = x * x
mis :: Maybe [Int]
mis = Just [1, 2, 3]
mis2 = fmap (fmap square) mis먼저 컴파일러는 타입을 분석한 후, 외부의 fmap에 대해서는 Maybe 인스턴스의 구현을 사용하고, 내부의 fmap에 대해서는 리스트 펑터의 구현을 사용해야한다는 것을 추론해낼 것이다. 물론 지금 시점에서 위 코드가 아래와 같은 코드로 다시 작성될 수 있다는 사실이 바로 이해가 되지는 않을 수도 있다.
mis2 = (fmap . fmap) square mis그러나 fmap은 하나의 인수에 대한 함수로 간주될 수 있다는 것을 기억해야한다.
fmap :: (a -> b) -> (f a -> f b)이 경우 (fmap . fmap)안의 두 번째 fmap은 다음과 같은 타입의 인수를 취한다.
square :: Int -> Int그리고 다음과 같은 타입의 함수를 반환할 것이다.
[Int] -> [Int]이후 첫 번째 fmap은 이 함수를 취하고 다음과 같은 타입의 함수를 반환한다.
Maybe [Int] -> Maybe [Int]그리고 비로소 이 함수가 mis에 적용된다. 따라서 두 펑터의 합성은 해당 fmap들의 합성인 펑터라고 볼 수 있다.
다시 카테고리 이론으로 돌아가보자. 대상들의 매핑이 결합법칙을 만족하며, 사상들의 매핑도 결합법칙을 만족하니 펑터의 합성 또한 결합법칙을 만족한다는 사실은 명확하다. 그리고 모든 카테고리에는 당연히 항등 펑터 또한 존재한다. 항등 펑터는 모든 대상과 사상이 자기자신에게 매핑되는 펑터이다.
즉, 펑터는 마치 어떠한 카테고리의 사상들과 동일한 특성을 가지게 된다. 그렇다면 그 카테고리란 무엇일까?
바로 대상이 카테고리이고, 사상이 펑터인 카테고리이다. 즉, 카테고리들의 카테고리라고 할 수 있다. 그러나 모든 카테고리들의 카테고리 또한 카테고리이니, 자기 자신을 자기 자신 안에 포함해야하는 모순에 빠지게 된다.
모든 “작은” 카테고리의 카테고리인 Cat이라는 개념이 있다. 작은 카테고리는 대상들이 집합을 형성하는 카테고리를 가리키며, 심지어 무한하여 셀 수 없는 집합도 “작은” 카테고리로 간주된다. 필자는 이런 개념들이 다양한 추상화 수준에서 동일한 구조가 반복되는 것을 표현할 수 있다는 것에 매우 놀라웠다. 심지어 나중에는 펑터들이 카테고리를 형성하는 케이스도 보게 될 것이다.