정규식은 어떻게 사용되는 것일까?
자주 쓰는 정규식 패턴 몇 가지

필자는 지난 불규칙 속에서 규칙을 찾아내는 정규표현식 포스팅에서 정규식의 기본적인 사용 방법을 한 차례 설명한 바 있다.
그러나 아무리 정규식의 기본적인 사용 방법을 알고 있다고 해도 실제로 정규식을 사용해야하는 상황이 되면 눈 앞이 깜깜해지기 마련이다.
그래서 이번 포스팅에서는 실제로 필자가 지금까지 일을 하며 경험했던 여러가지 상황을 토대로 정규식을 어떻게 사용했는지에 대한 몇 가지 예시와 설명을 조금 곁들여 볼까 한다.
정규식을 가장 많이 사용하는 상황인 “유저의 입력 검증”, “원하는 정보 찾기”, “문자열을 원하는 포맷으로 변경하기”를 예시로, 문제를 정의하고 정규식을 사용하여 문제를 해결해보도록 하자.
유저의 입력 검증하기
사실 개발을 진행하며 정규식이 가장 쉽게 접하는 상황은 유저의 입력을 검증할 때이다.
개발이나 디자인을 하다보면 자연스럽게 알게 되는 것이기는 하지만, 유저는 절대 내가 설계한 대로 제품을 사용하지 않기 때문에 유저가 입력하는 데이터를 곧이 곧대로 신뢰하고 서버로 전송하는 행위는 꽤나 위험한 짓이다.
분명히 이메일을 입력하라고 했는데 전화번호를 입력할 수도 있고, 최악의 경우에는 악의를 가지고 이상한 스크립트나 쿼리를 입력하여 서버로 전송할 수도 있다.
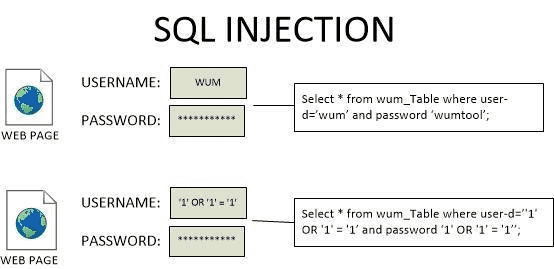 물론 최근에는 백엔드 프레임워크에서 사용하는 ORM이 자체적으로 이런 인젝션 어택을 방어해주기는 하지만
물론 최근에는 백엔드 프레임워크에서 사용하는 ORM이 자체적으로 이런 인젝션 어택을 방어해주기는 하지만퍼포먼스를 위해 로우 쿼리를 사용하는 경우도 여전히 존재하기 때문에 방심해서는 안 된다
그렇기 때문에 클라이언트 개발자는 1차적으로 사용자의 입력이 올바른 입력인지를 검증하는 밸리데이션 로직을 작성하게 되는데, 이 과정에서 정규식이 매우 유용하게 사용된다.
이메일 주소 검증하기
이메일은 사용자에게 받는 입력 데이터 중 굉장히 흔한 포맷이다. 게다가 이메일 주소라는 것은 각 필드의 역할도 명확하고 규칙도 제한적이라, 사용자가 입력한 데이터가 올바른 이메일 주소인지 검증하는 것도 크게 어렵지 않다.
MBP(Mailbox Provider)마다 조금씩 다를 수는 있지만, 인터넷 메세지 프로토콜을 정의하고 있는 RFC 2822#Addr-spec specification에서 정의된 바에 따르면 이메일 주소를 다음과 같은 패턴을 가진 문자열로 정의할 수 있다.
이메일 주소는 계정, @, 도메인으로 이루어진 문자열이다.
계정은 영어와 숫자, 그리고
!#$%&'*+-/=?^_{|}~등의 특수문자를 사용할 수 있다..도 사용할 수 있지만, 계정이.으로 시작하거나 끝나서는 안 된다.도메인은 영어로 된 호스트와 도메인 식별자가
.으로 연결된 형태이다 (ex. google.com)계정과 도메인은
@으로 연결되어있다.
이처럼 이메일 주소는 한정적인 패턴을 가진 정보이기 때문에 정규식으로 간단하게 패턴 매칭을 통해 검증할 수 있다.
이메일 계정
이메일의 계정에는 영어와 숫자를 사용할 수 있기 때문에 \w을 사용하여 영어와 숫자를 모두 포함한 워드 그룹을 사용하면 간단하게 이 패턴을 매칭할 수 있다. 또한 !#$%&'*+-/=?^_{|}~ 등의 특수 문자도 사용할 수 있기 때문에 [\w!#$%&'*+-/=?^_{|}~]과 같이 커스텀 그룹을 사용하면 이메일 계정에 사용할 수 있는 영어와 숫자, 특수문자를 모두 매칭할 수 있다.
또한 이 패턴은 무조건 1번 이상 등장해야한다. 만약 이 패턴이 0번 등장한다면 계정에 위 패턴이 존재하지 않는다는 것이니 올바른 이메일 주소라고 취급할 수 없기 때문이다. 그래서 표현식의 끝에는 패턴이 1번 이상 등장했음을 의미하는 + 수량자를 붙혀줘야한다.
^[\w!#$%&'*+/=?^_{|}~-]+이 패턴이 기본적인 이메일 계정의 패턴이다. 하지만 RFC 2822에는 까다로운 규칙이 하나 더 있는데, 바로 ”.도 사용할 수 있지만, 계정이 .으로 시작하거나 끝나서는 안 된다.” 라는 규칙이다.
물론 문자열이 .으로 시작하거나 끝나지 않는 지를 검사하는 문제는 ^과 $ 앵커를 사용하면 간단하게 해결할 수 있지만, 중간에 .이 등장하는 경우는 어떻게 처리해야할 지 애매하다.
사실 이렇게 어떤 문자가 중간에 등장할 수도 있고 아닐 수도 있다는 패턴을 가장 간단하게 정의하는 방법은 별 게 없다.
.은 무조건 계정의 중간에 등장한다. 즉,.뒤에는 반드시[\w!#$%&'*+-/=?^_{|}~]패턴이 다시 등장해야한다.
조금 더 정리해보자면, .어쩌고저쩌고 라는 패턴은 계정 문자열 내에 등장할 수도 있고 등장하지 않을 수도 있으며, 만약 등장했다고 하면 반드시 . 뒤에는 다른 문자들이 있어야한다는 것이다.
이 패턴만 따로 떼어내서 정규식으로 표현해보자면 다음과 같다.
(?:\.[\w!#$%&'*+/=?^_{|}~-]+)*먼저 (?:과 )로 묶어준 부분부터 살펴보자. 이 표현은 이전 포스팅에서 설명한 캡쳐링 기능과 동일한 역할을 한다.
사실 캡쳐링은 캡쳐 외에도 여러 개의 표현을 그룹핑하는 기능 또한 가지고 있는데, 이때 그룹핑을 하는 ()의 앞 쪽에 ?:라는 표현을 포함시켜주면 캡쳐링 기능은 사용하지 않고 그룹핑 기능만 사용하겠다는 것을 의미하는 것이다.
그래서 이 기능을 캡쳐링을 하지 않는 그룹을 만든다고 해서 “Non-Capturing Group”라고 한다.
그리고 그룹 안쪽의 표현 중 \.은 .이라는 문자 그 자체를 의미한다. 만약 이스케이핑 처리 없이 .만 적었다면 정규식 엔진은 해당 문자를 .이 아닌 모든 문자를 의미하는 캐릭터 클래스로 해석할 것이기 때문에, .이라는 문자 그대로 해석할 수 있도록 이스케이핑 처리를 해준 것이다.
그 뒤로는 앞서 계정 패턴에 사용했던 [\w!#$%&'*+/=?^_{|}~-]+ 패턴을 그대로 적어주었다. 즉, . 뒤에는 저 패턴이 반드시 1개 이상 따라온다는 것을 표현한 것이다.
그리고 마지막으로 이 전체 패턴은 나타날 수도 있고 나타나지 않을 수도 있다는 것을 표현해주기 위해 그룹이 끝나는 ) 부분 뒤 쪽에 0번 또는 그 이상의 패턴이 출몰할 수 있다는 * 수량자를 붙혀주었다.
이제 이 패턴을 앞서 정의한 [\w!#$%&'*+/=?^_{|}~-]+ 패턴과 합쳐주면 올바른 이메일 계정을 잡아낼 수 있는 패턴이 완성된다.
const regex = /^[\w!#$%&'*+/=?^_{|}~-]+(?:\.[\w!#$%&'*+/=?^_{|}~-]+)*$/g;// 영어 + 숫자
regex.test('bboydart91'); // true
// 계정 중간이 .으로 나누어짐
regex.test('bboydart91.test'); // true
// .으로 끝나거나 시작함
regex.test('.bboydart91'); // false
regex.test('bboydart91.'); // false도메인
이제 정규식을 사용하여 올바른 이메일 계정을 구분할 수 있는 패턴을 정의했으니, 남은 것은 올바른 도메인을 구분할 수 있는 패턴을 정의하는 것 뿐이다.
RFC 2822에 따르면 도메인은 “영어로 된 호스트와 도메인 식별자가 .으로 연결된 형태”라고 했으니, 패턴 매칭의 조건이 크게 어려운 것은 아니다.
그러나 조건을 잘 살펴보면 호스트와 도메인 식별자가 .으로 연결된 형태라고만 하고 있을 뿐이지 .이 단 한번만 등장한다는 이야기가 없기 때문에 이 부분을 신경써줘야한다. 즉, google.com과 같은 패턴 뿐만 아니라 google.co.kr 처럼 .이 여러 번 등장하는 녀석들도 다 잡아줘야 한다는 것이다.
이런 애매한 패턴들도 방금 전 계정 패턴을 정의할 때 사용했던 Non-Capturing Group을 사용하면 간단하게 정의할 수 있다.
const regex = /^(?:\w+\.)+\w+$/g;(?:\w+\.)+은 google.과 같이 워드 그룹과 .이 합쳐진 패턴이 반드시 한 번 이상 나타나야 한다는 것을 표현하고, 이어지는 \w+는 . 뒤에도 워드 그룹으로 이루어진 문자열이 반드시 한 번 이상 나타나야 한다는 것을 표현한 것이다.
// 호스트와 도메인 식별자가 모두 존재
regex.test('google.com'); // true
regex.test('google.co.kr'); //true
// 도메인 식별자가 없음
regex.test('google.'); // false
regex.test('google'); // false
// 호스트가 없음
regex.test('.com'); // false
regex.test('.co.kr'); // false계정 패턴 표현식과 도메인 패턴 표현식을 합치자
이제 올바른 이메일 계정과 도메인을 잡아낼 수 있는 정규식을 정의했으니 마지막 조건인 “계정과 도메인은 @으로 연결되어있다”를 만족시키기 위해, 이 두 표현을 @로 합쳐주기만 하면 된다.
// 계정 패턴: ^[\w!#$%&'*+/=?^_{|}~-]+(?:\.[\w!#$%&'*+/=?^_{|}~-]+)*
// 도메인 패턴 (?:\w+\.)+\w+$
const regex = /^[\w!#$%&'*+/=?^_{|}~-]+(?:\.[\w!#$%&'*+/=?^_{|}~-]+)*@(?:\w+\.)+\w+$/g;regex.test('bboydart91@gmail.com'); // true
regex.test('bboydart.evan@gmail.com'); // true
regex.test('bboydart@naver.co.kr'); // true
regex.test('.bboydart91@gmail.com'); // false
regex.test('bboydart91@gmail'); // false
regex.test('bboydart91.@gmail.com'); // false전화번호
전화번호 같은 경우는 지난 포스팅인 불규칙 속에서 규칙을 찾아내는 정규표현식에서 한 차례 언급한 바가 있지만, 이전 포스팅을 읽지 못하신 독자분들을 위해 한번 더 언급하려고 한다.
전화번호 또한 이메일과 마찬가지로 유저에게 입력받는 경우가 많은 정보이기 때문에 전화번호를 잡아낼 수 있는 패턴을 숙지하고 있으면 좋기 때문이다.
대한민국의 전화번호는 총 3가지 패턴을 가지고 있는데, 휴대폰 번호같은 경우 반드시 맨 앞에는 3자리의 통신사 식별번호가 위치하고 그 뒤에는 4자리의 전화번호 필드가 두 번 반복되는 형태를 가지며, 그 외 유선전화는 2-3자리의 지역번호 뒤로 3-4 자리의 필드와 4자리의 필드가 반복되는 형태를 가진다.
'010-0101-0101'
'02-0101-0101'
'031-010-0101'이렇듯 전화번호라는 정보는 그저 숫자들이 일정 횟수만큼 반복적으로 나타나는 패턴 뿐이기 때문에 이 패턴을 잡아내기 위한 정규식 또한 간단하게 작성할 수 있다.
const regex = /^\d{2,3}-?\d{3,4}-?\d{4}$/g;regex.test('01012341234'); // true
regex.test('010-1234-1234'); // true
regex.test('0212341234'); // true
regex.test('02-1234-1234'); // true
regex.test('031-123-1234'); // true전화번호는 각 필드의 자릿수가 명확하게 정해져있기 때문에 단순한 수량자 표현만으로도 패턴을 잡아낼 수 있다. 또한 전화번호 중간의 하이픈(-)은 등장할 수도 있고 아닐 수도 있으므로 0 또는 1회를 의미하는 수량자인 ? 를 사용하여 패턴을 처리해주었다.
이렇게 전화번호 패턴을 잡아내는 표현식 자체는 간단하지만, 의외로 신경쓰고 있지 않던 부분에서 실수를 하는 경우가 생기는데, 바로 이런 패턴을 사용하는 상황 때문이다.
// 휴대폰 번호를 잡아내는 패턴
/010-\d{3,4}-\d{4}/;이 패턴의 문제는 010이라는 통신사 식별번호를 가지고 있는 휴대폰 번호만 잡아낼 수 있다는 것이다.
필자같은 아재들이야 011, 017, 018 등의 번호가 있던 시절을 아직 기억하고 있기 때문에 이런 실수를 할 확률이 낮지만, 간혹 2000년대에 출생하신 분들 중에서 이 부분을 놓치는 경우를 간혹 보았었다.
 1996년 신상 "걸면 걸리는 걸리버 폰"...필자의 아버지도 이 폰을 쓰셨던 기억이 있다
1996년 신상 "걸면 걸리는 걸리버 폰"...필자의 아버지도 이 폰을 쓰셨던 기억이 있다
물론 정부와 통신사들이 01x 번호를 010으로 통합하려고 노력하고 있지만 아직까지 추억의 번호를 버리지 못하시는 분들도 꽤나 있기 때문에, 우리는 01[0|1|6|7|8|9]처럼 011이나 016, 018 등의 통신사 식별번호도 잡아낼 수 있는 패턴을 사용해야한다.
비밀번호
비밀번호는 사용자의 인증, 보안과 직결된 정보이기 때문에 유효성을 검사해야하는 정보들 중에서도 꽤 까다로운 검사 조건을 자랑하는 녀석이다.
지금 바로 생각나는 조건은 대략 세 가지 정도인데, 이 조건들은 기본적인 보안 수준을 지키기 위함이기 때문에 서비스 종류를 망라하고 대부분의 서비스에서 지켜지는 녀석들이다.
- 반드시 소문자, 대문자, 숫자, 특수 문자가 하나씩 포함되어야한다.
- 같은 문자가 3번 이상 반복되면 안된다.
- 8글자 이상이어야 한다.
이때 사용자가 비밀번호를 틀렸을 때 얼마나 상세한 에러메세지를 보여줄 계획이냐에 따라서 이 조건들을 한 번에 검사하기도 하고 따로 검사하기도 한다.
가장 첫 번째 조건은 비밀번호 안에 반드시 영어 소문자, 대문자, 숫자, 특수문자가 하나씩은 포함되어있어야 한다는 조건이다. 물론 이 조건을 하나씩 따로 따로 검사한다면 간단하게 /[a-z]/g이나 /\d/g와 같은 표현식으로 간단하게 검사할 수 있다.
const password = 'test1234!';
// 따로 검사
const hasNumberPattern = /\d/g;
const hasLowerCasePattern = /[a-z]/g;
const hasUpperCasePattern = /[A-Z]/g;
const hasSpecialCharPattern = /\W/g;
if (!hasNumberPattern.test(password)) {
console.error('비밀번호에는 숫자가 하나 이상 어쩌고...');
} else if (!hasLowerCasePattern.test(password)) {
console.error('비밀번호에는 영어 소문자가 하나 이상 어쩌고...');
} else if (...) {}하지만 문제는 이 조건들을 한 번에 검사하고 싶을 때 발생한다. 단순하게 [a-zA-Z\d] 등의 커스텀 그룹으로 검사하려고 한다면 이 중 단 하나의 패턴만 비밀번호에 포함되어 있어도 조건이 통과되어 버릴테고, [a-z]+[A-Z]+등의 패턴으로 검사하려고 하면 반드시 “소문자 다음에는 대문자가 와야함”과 같은 순서가 생겨버리기 때문이다.
이런 상황에서 우리는 약간 트리키(Tricky)한 방법을 사용하여 이 문제를 해결할 수 있다.
Lookaround를 사용하여 유효성 검사하기
그 방법은 바로 특정 패턴 앞에 나타나는 패턴을 표현하는 방법인 Positive Lookahead((?=))를 사용하는 것이다.
// ://이라는 문자 앞에 등장하는 https를 잡아줘!
const regex = /https(?=:\/\/)/g;regex.exec('https'); // null
regex.exec('https://'); // ['https']이렇게 특정 표현의 앞이나 뒤에 나타나는 패턴을 잡아내는 표현을 “Lookaround”라고 하며, Lookaround는 총 4가지 패턴으로 다시 분류된다.
| 이름 | 패턴 | 의미 |
|---|---|---|
| Positive Lookahead | abc(?=123) |
123 앞에 오는 abc를 잡아라 |
| Negative Lookahead | abc(?!123) |
123 앞에 오지 않는 abc를 잡아라 |
| Positive Lookbehind | (?<=123)abc |
123 뒤에 오는 abc를 잡아라 |
| Negative Lookbehind | (?<!123)abc |
123 뒤에 오지 않는 abc를 잡아라 |
주위를 둘러보라는 “Look around”라는 단어의 의미처럼, Lookaround 표현은 말 그대로 특정 패턴의 앞뒤로 나타나는 패턴이 있는지를 검사하는 용도로 사용되는 표현이지만, 이 표현을 해석하는 정규식 엔진의 작동 원리를 잘 이용하면 문자열 내에 특정한 패턴의 글자가 1번 이상 나타났는지를 잡아내야하는 경우에도 유용하게 사용할 수 있다.
일단 Lookaround 표현 자체는 특정 문자를 잡아내기 위한 표현이 아니기 때문에 마치 \b 앵커처럼 일종의 경계로 인식된다. 또한 한 가지 중요한 특징은 정규식 엔진이 Lookaround를 사용하여 특정 문자와 매칭에 성공하더라도 마치 해당 매칭이 없었던 것처럼 작동한다는 것이다.
무슨 이야기인지 잘 이해가 안 가시는 분들을 위해 조금 더 자세한 예시를 들어보도록 하겠다. 만약 quit라는 문자열에 q(?=u)i와 같은 표현식을 적용해보면 정규식 엔진은 다음과 같이 작동한다.
- 엔진은 문자열의
q를 매칭하려 함. 정규식의q리터럴과 매칭 성공- 엔진은 문자열의
u를 매칭하려 함. 정규식의(?=u)내부의u가 있기에 매칭 성공. 그리고 엔진은 이 패턴과u문자가 Lookaround로 매칭 성공되었다는 사실을 잊어버린다.- 이제 엔진은 Lookaround 패턴 뒤에 위치한 패턴을 사용하여 다시 문자열의
u를 매칭해보려고 시도함.- 근데 표현식의 다음 표현은
i임.u와 매칭 실패하고 종료.
/q(?=u)i/g.exec('quit');null이건 어찌보면 당연한 수순인데, (?=u)와 같은 Lookaround 표현은 단지 해당 표현 앞에 오는 패턴을 잡아내기 위한 재료일 뿐이지, 실제로 u라는 글자를 잡아내기 위한 표현이 아니기 때문이다. 그래서 정규식 엔진은 Lookaround를 사용하여 u라는 문자를 매칭했음에도 매칭 성공 후에 u라는 문자에 다시 매칭을 시도하는 것이다.
만약 (?=u) 패턴 뒤의 리터럴 표현을 i가 아니라 u로 바꾸어주면 4번 조건을 통과하면서 매칭을 성공하게 된다.
/q(?=u)u/g.exec('quit');["qu"]이때 가장 중요한 포인트는 정규식 엔진이 Lookaround로 한번 매칭되었던 문자는 재료로써의 매칭만 성공했기 때문에 정식 매칭 성공이 아니라고 판단하여, Lookaround 표현의 뒤에 위치한 표현을 사용하여 다시 해당 문자에 매칭을 시도한다는 것이다.
정규식 엔진의 이런 특성을 잘 사용하면 Lookaround 표현을 마치 if문 처럼 사용할 수도 있다. 그렇다면 이 방법을 사용하여 아까 필자가 정의했던 비밀번호의 조건 중 하나를 검사해보자.
반드시 소문자, 대문자, 숫자, 특수 문자가 하나씩 포함되어야한다.
하지만 이 조건을 한 번에 모두 검사하면 표현식이 길어질 것 같으니, 우선은 비밀번호 안에 반드시 숫자가 포함되어 있는지만 한번 검사를 해보면 좋을 것 같다. 이때 방금 학습한 Positive Lookahead 표현을 사용하여 해당 조건 여부를 검사해볼 수 있다.
/(?=\d)./.exec('abc123');["1"]여기서 정규식이 1이라는 문자를 잡아낸 이유는 위에서 이야기했던 것처럼 (?=\d)라는 표현이 1과 매칭이 되었고, 이후 정규식 엔진이 해당 표현 바로 뒤에 오는 .으로 다시 한번 동일한 문자에 매칭을 시도했기 때문이다.
이 과정을 조금 더 쉽게 의사코드로 다시 풀어보자면 이런 느낌이다.
if (match(/(?=\d)/, '1')) {
delete(/(?=\d)/); // 매칭에 성공했으니 이 패턴은 제거
match(/./, '1'); // 그 뒤에 오는 패턴으로 동일한 문자에 다시 매칭 시도
}즉, 정규식 엔진이 .이라는 리터럴 표현을 가지고 매칭을 시도했다는 것은 그 앞에 있던 (?=\d)라는 표현으로 이미 해당 문자에 매칭을 성공했다는 의미인 것이다.
이제 숫자를 검사했으니 나머지 조건인 영어 소문자와 대문자, 그리고 특수문자도 동일한 방식을 사용하여 앞 쪽에 줄줄이 붙혀주기만 하면 된다.
// \d = 숫자
// [a-z] = 영어 소문자
// [A-Z] = 영어 대문자
// [\W] = Word 그룹(숫자, 영어)가 아닌 문자
/(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*[\W])./g여기서 \W 캐릭터 클래스는 사실 영어, 숫자가 아닌 문자를 의미하는 클래스라서 특수문자 뿐 아니라 한글이나 키릴문자 같은 문자도 전부 포함되기는 하는데, 일일히 특수문자를 나열하기는 가독성이 너무 떨어지니귀찮으니 대충 썼다. (실제로 사용할 때는 !@#$%^...처럼 일일히 나열해주는 방식으로 변경해줘야한다.)
이런 식으로 비밀번호의 나머지 조건인 “같은 문자가 3번 이상 반복되면 안 된다”와 “8자리 이상이어야 한다”라는 조건도 동일한 방법으로 검사해볼 수 있다.
/(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*[\W])(?!.*(.)\1{2}).{8,}/| 표현 | 의미 |
|---|---|
(?=.*\d) |
연속 또는 하나만 나타날 수 있는 \d |
(?=.*[a-z]) |
연속 또는 하나만 나타날 수 있는 [a-z] |
(?=.*[A-Z]) |
연속 또는 하나만 나타날 수 있는 [A-Z] |
(?=.*[\W]) |
연속 또는 하나만 나타날 수 있는 [\W] |
(?!.*(.)\1{2}) |
연속적으로 3번 나타나지 않는 모든 문자 |
.{8,} |
위 조건을 모두 통과한 8자리 문자열 패턴 |
이 표현은 앞 쪽의 Positive Lookahead와 Negative Lookahead의 조건을 모두 통과해야 비로소 맨 마지막의 .{8,} 표현과 매칭을 시도할 것이기 때문에, 이 조건을 통과한 문자열은 우리가 정의했던 비밀번호의 모든 조건을 통과했다는 의미가 된다.
물론 비밀번호를 이렇게 하나의 정규식 표현으로 검사해버리면 사용자에게 “비밀번호가 올바르지 않습니다” 정도의 에러 메세지 밖에 보여줄 수 없기 때문에 이렇게 한번에 처리하는 경우가 오히려 드물기는 하지만, Lookaround를 사용한 조건 처리 방법은 꽤나 유용한 편이라고 생각이 들어서 이렇게 설명하게 되었다.
불규칙한 문자열에서 원하는 정보만 골라내기
대부분의 경우 정규식은 유저의 입력을 검증하는 일에 많이 사용되고는 하지만, 사실 정규식의 존재 의의는 단지 정보를 검증하는 것이라기보다 불규칙한 정보 속에서 특정한 패턴을 찾아내어 추출하는 것에 가깝다.
이번에는 일상 속에서 필자가 경험했던 사례들과 함께 정규식을 사용하여 어떻게 문제를 해결했었는지에 대한 이야기를 해보려고 한다.
주어진 문자열 내에서 숫자만 골라내기
주어진 문자열 내에서 숫자만 골라내야하는 상황은 생각보다 현업에서 많이 마주치는 문제 중 하나이다. 필자의 경우에는 원본 데이터를 직접 수정할 수 없는 상황에서 금액이나 나이를 의미하는 숫자만 걸러내어 데이터를 정규화하거나 다른 포맷으로 보여줘야하는 상황을 많이 겪었던 것 같다.
예를 들어 어떤 API를 사용했는데, 이 API에서는 금액 정보를 1000과 같은 Number 자료형이 아닌 1,000원과 같은 포맷팅된 문자열로 내려준다고 생각해보자. 그리고 이 데이터를 사용하는 클라이언트에서는 이런 비즈니스 로직을 작성해야하는 상황이다.
“1,000원”과 “2,000원” 중 어떤 것이 큰 금액일까?
물론 가장 좋은 상황은 원본 데이터가 1000과 같은 Number 자료형으로 내려오고 데이터를 사용하는 쪽에서 적절한 후처리를 통해 가공하는 것이지만, 그렇게 API를 수정해버리면 이 API가 전체 서비스 중 어느 부분에서 사용되고 있는지 전부 파악하고 이 API를 사용하는 클라이언트의 소스를 모두 수정해줘야 하기 때문에 리스크 관리 차원에서 그냥 넘어가는 경우도 꽤나 있다.
이런 상황 속에서 개발자는 1,000원이라는 문자열에서 콤마와 “원”이라는 글자를 제외하고 1000이라는 숫자만 뽑아온 후 두 개의 금액을 비교하는 과정을 거쳐야 할 것이다.
만약 정규식이 없다면 이 문자열을 split 메소드를 통해 분해하고 이렇게 만들어진 배열을 순회하면서 이 문자가 숫자인지 아닌지 구분해야하거나 String.prototype.replace를 2번씩 해줘야하는 번거로운 과정을 거쳐야한다.
const NUMBERS = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
const amount = '1,000원'
.split('')
.filter(v => NUMBERS.includes(v))
.join('');
// 또는
const amount = '1,000원'.replace(',', '').replace('원', '');
console.log(Number(amount));1000String.prototype.replace 메소드를 사용하는 방법도 꽤나 간단해보이기는 하지만, 이 방법의 한계는 ,나 원 이외에 다른 문자가 섞여버리면 그 문자의 경우의 수만큼 replace를 반복해야하거나 코드를 수정해줘야 한다는 것이다. (1,000원...일까요? 같은 문자열이 들어오는 순간 망한다)
물론 똑같이 문자열 내에서 숫자만 발라내는 코드지만, 정규식을 사용하면 상대적으로 간편하고 유연하게 문제를 해결할 수 있다.
const amount = '1,000원'.replace(/[^0-9]/g, '');
// 또는
const amount = '1,000원'.replace(/[^\d]/g, '');
// or
const amount = '1,000원'.replace(/\D/g, '');
console.log(Number(amount));1000자바스크립트의 String.prototype.replace 메소드는 특정 문자열을 검색한 후에 두 번째 인자로 주어진 문자열로 모두 치환해주는 메소드이다. replace 메소드는 정규식을 사용하여 원하는 문자 패턴을 찾는 기능을 지원하고 있기 때문에, 정규식을 사용하여 “숫자가 아닌 것”을 잡아서 모두 빈 문자열로 치환해버린다면 우리가 원하는 바인 “숫자만 골라내기”라는 문제를 해결할 수 있는 것이다.
즉, 필자가 사용했던 [^0-9], [^\d], \D 라는 키워드들은 모두 숫자가 아닌 문자들을 잡아내는 키워드를 의미하기 때문에 “숫자가 아닌 것”을 저 정규식들로 한 방에 잡아내어 없애버릴 수 있었던 것이다.
물론 처음 필자가 작성했던 예시처럼 정규식을 사용하지 않고도 split, filter, join, replace 메소드를 조합하더라도 당장 문제를 해결하는데는 아무 어려움이 없지만, 현실에는 문자열 속에서 숫자만 찾아내는 수준의 간단한 문제보다 복잡한 수준의 문제들이 즐비해 있다는 사실을 잊어서는 안된다.
그럼 현실 속에서 만날 수 있는 문제들 중 조금 더 어려운 문제를 하나만 더 보도록 하자.
문장 속에서 금액만 추출하기
이번에는 방금 전 봤던 문제와 같은 맥락이지만 조금 더 복잡한 문제를 한번 해결해보려고 한다. 방금 우리가 경험했던 문제는 1,000원이라는 누가 봐도 명확히 금액을 의미하는 작은 단어에서 숫자를 의미하는 부분만 뽑아내는 것이었다면, 이번에는 자연어로 이루어진 긴 문장 속에서 금액을 의미하는 부분만 찾아내어 금액 데이터를 추출해야한다.
예시 문장은 부자가 되고 싶다는 필자의 염원을 담아 적당한 기사에서 발췌해왔다.
현재까지 로또 복권의 판매금액은 38조40230억2565만7000원. 2014년 기준 회당 평균 580억원 가량의 로또가 팔린다. 조사에 따르면 1인당 평균 구매액은 9400원으로 19세 이상 성인 인구 기준 매주 약 512만 명이 로또를 구입한다.
이렇게 긴 자연어 문장 속에서 금액을 의미하는 데이터만 추출해야하는 상황이라면 우리가 풀어야 할 문제는 총 두 가지의 작은 문제로 나눠볼 수 있다.
- 많은 숫자들 중에서 금액을 의미하는 단어만 뽑아내기
580억원과 같은 단어를 Number형인5800000000으로 변환하기
이 중 두 번째 문제는 정규식만으로 해결하기에는 약간 무리가 있으니, 우리는 첫 번째 문제인 “많은 숫자들 중에서 금액을 의미하는 단어만 뽑아내기”에만 집중해보도록 하자.
만약 이 문제를 해결할 때 필자가 위에서 사용했던 \d나 [0-9]와 같은 키워드를 사용하게 되면 금액을 의미하는 숫자가 아닌 2014년, 1인당, 19세, 512만명에 포함된 숫자도 함께 뽑혀나올 것이므로 우리는 방금과 같이 간단한 방법으로는 이 문제를 해결할 수가 없다.
하지만 정규식이 강력한 진짜 이유는 이런 난해한 상황 속에서도 원하는 데이터를 뽑아낼 수 있는 패턴만 파악한다면 간단하게 문제를 해결할 수 있다는 점이다. 사실 일반적인 한글 문장 속에서 금액을 의미하는 단어가 불규칙하게 튀어나오는 것 같지만, 자세히 들여다보면 금액을 의미하는 단어는 특정한 패턴을 가지고 출몰한다.
먼저, 금액을 의미하는 단어는 “철수는 영희에게 1,000원을 갚아야한다”, “철수의 이번 달 월급은 30원이다”와 같이 반드시 단어 앞에 띄어쓰기가 들어간다. 하지만 이 규칙은 금액 뿐 아니라 다른 숫자 데이터에도 동일하게 적용되는 한글의 문법이라 이것만으로는 이 숫자가 금액을 의미하는 숫자인지 파악하기가 어렵기 때문에 필자는 한 가지 패턴을 더 적용하려고 한다.
사실 두 번째 패턴도 누구나 다 알 수 있는 패턴인데, 금액을 의미하는 데이터는 반드시 단위를 표현하는 무언가와 함께 출몰한다는 점이다. $1,000, 1,000원, ₩1,000 처럼 말이다. 위 문장에서의 금액 데이터는 반드시 숫자 뒤에 KRW를 의미하는 “원”이라는 글자 앞 쪽에 출몰하는 것을 알 수 있다.
이렇게 패턴을 찾아내고 나면 그 다음부터는 정규식을 사용하여 이 패턴을 가진 단어를 찾아내기만 하면 되는 것이다.
const string = '현재까지 로또 복권의 총 판매금액은 38조40230억2565만7000원. 2014년 기준 회당 평균 580억원 가량의 로또가 팔린다. 조사에 따르면 1인당 평균 구매액은 9400원으로 19세 이상 성인 인구 기준 매주 약 512만 명이 로또를 구입한다.';
string.match(/(?<=\s)\S*?\d+(?=원)/g);["38조40230억2565만7000", "9400"]String.prototype.match 메소드는 문자열 내에서 인자로 주어진 문자열이나 정규식과 매칭되는 부분을 찾아낼 수 있는 메소드이다. 이번에는 앞선 문제와 다르게 문장 내에서 금액을 표현하는 단어가 여러 개 출몰하기 때문에 match 메소드를 사용하여 정규식과 매칭된 모든 부분을 찾아낸 것이다.
위 문제에서 사용했던 [^\d]와 같은 단순한 표현과 다르게 이번에는 조금 더 복잡해보이는 표현을 사용했는데, 사실 이 정규식도 막상 뜯어보면 의미 자체는 크게 복잡하지 않다. (다시 말하지만 정규식은 그냥 가독성이 떨어질 뿐 의미 자체는 어렵지않다)
필자가 사용한 (?<=\s)\S*?\d+(?=원)라는 정규식의 의미는 대략 다음과 같다.
(?<=\s): 공백(\s) 뒤에 있고(?<=)
\S*?: 공백이 아닌 문자(\S)가 있을 수도 있고 없을 수도 있으며(*?)
\d+: 숫자(\d)가 한 개 이상(+) 조합되어있고
(?=원): “원”이라는 글자 앞에 있는(?=원) 녀석들
이번 예시 문장 속에서 필자가 찾고자 한 패턴은 단순히 하나의 조건으로 이루어진 것이 아니라 여러 개의 조건으로 이루어진 꽤나 복잡한 패턴이기 때문에, \S, \d와 같은 단순한 키워드만 사용한 것이 아니라 정규식에서 제공하는 기능을 충분히 활용해야했다.
그리고 특정 패턴 앞이나 뒤에 오는 패턴을 잡아내기 위해 위에서 설명했던 Lookahead와 Lookbehind 기능도 활용했으며, 이전 포스팅에서 설명했던 Greedy도 사용했다.
이렇듯 정규식은 단지 문자열 속에서 특정한 패턴을 잡아낼 수 있는 도구이기 때문에 이렇게 원하는 데이터를 뽑아내는 것 뿐 아니라, 사용자의 입력을 검증하거나 HTML, 자바스크립트와 같은 코드를 파싱하거나 JPG, OBJ와 같은 파일을 파싱하는 등 다양한 부분에서 활용될 수 있으니 한번 알아두면 여기저기에 써먹을 수 있는 꿀 지식이라고 할 수 있다.
문자열을 내가 원하는 포맷으로 변환하기
앞선 예시에 몇 차례 언급된 바가 있지만 정규식은 문자열을 치환하여 내가 원하는 포맷으로 변경할 때도 꽤나 요긴하게 사용될 수 있다.
가령 사용자의 중요한 정보를 *과 같은 문자로 일부 마스킹 처리를 해준다던가, 사용자가 입력한 전화번호나 카드번호 사이 사이에 -를 삽입하여 가독성을 높혀주는 경우처럼 말이다.
이런 문제를 해결할 때 정규식의 캡쳐링 기능을 사용하면 생각보다 쉽게 풀리는 경우가 많다. 물론 캡쳐링 기능 자체는 굉장히 많은 상황에서 사용될 수 있지만, 특히 원하는 부분만 정확히 잡아내어 내가 원하는 문자로 치환해야하는 상황에서 빛을 발한다.
사용자의 정보 마스킹하기
간혹 서비스를 만들다보면 불특정한 사용자들의 리스트를 보여줘야하는 화면 내에서 각 사용자들의 민감정보를 마스킹해줘야 하는 경우가 왕왕 발생하는데, 이때 이 사용자들이 봇이 아닌 실제 사용자라는 인식을 주기 위해 전체 정보를 마스킹하는 것이 아닌 일부만 마스킹하는 경우가 많다.
보통 이름같은 경우에는 성, 혹은 이름의 맨 앞 한 글자를 제외한 나머지를 마스킹하거나 전화번호의 경우에는 010과 같은 통신사 식별번호와 다음 필드의 한 두 글자를 제외한 나머지를 마스킹하게 된다.
function mask (str, headCount = 1) {
// 문자열 맨 앞의 n 글자를 가져온다
const head = new RegExp(`^.{${headCount}}`, 'g').exec(str);
// head를 제외한 나머지를 마스킹한다
const tails = str.replace(head, '').replace(/./g, '*');
// head와 tails를 합친다
return head + tails;
}mask('문동욱', 2);
mask('01012345678', 5);'문동*'
'01012******'mask 함수는 마스킹할 글자 수를 인자로 받아서 처리하는 동작을 수행하기 때문에 정규표현식 또한 변수를 사용하여 생성해줘야하며, 이렇게 동적인 값을 사용하여 정규표현식을 생성할 때는 /을 사용한 리터럴 표현이 아닌 RegExp 객체를 직접 생성하여 표현식을 인자로 넘겨줘야한다.
하지만 이렇게 단순히 글자 수만 세어서 마스킹 처리를 하게 되면 문제가 발생할 수 있는데, 바로 이런 케이스 때문이다.
// 응 외국인이야~
mask('E Van Moon', 2);
// 전화번호 구분 필드도 있어~
mask('010-1234-5678', 5);// 두 글자를 건너뛰고 마스킹하려 했지만...
// 실제로 보이는 건 한 글자
'E ********'
// 다섯 글자를 건너뛰고 마스킹하려 했지만...
// 실제로 보이는 건 네 글자
'010-1********'사실 이런 경우는 그냥 무시하고 넘어가도 UX에 큰 지장은 없지만, E V** ****이나 ***-****-****처럼 특정 문자는 마스킹이 되지 않도록 처리하는 것이 아무래도 완성도도 높고 가독성도 좋아지기 때문에 해둬서 나쁠 건 없다고 생각한다.
이런 문제를 해결할 때 어려운 부분은 아무래도 맨 앞 글자 중 공백이나 -를 제외하고 글자 수를 세야한다는 점인데, 조금만 생각해보면 꽤나 간단하게 이 패턴을 만들어 낼 수 있다. 정규식의 수량자는 각각의 문자가 아니라 내가 정해준 패턴을 카운팅하는 것이기 때문이다.
// (?:)로 그룹핑된 패턴이 2번 나왔음?
/(?:\S[\s-]*){2}/이 표현은 공백이 아닌 문자(\S) 뒤 쪽으로 공백이나 -가 있거나 없을 수 있다는 패턴이 2번 나타난 경우를 의미한다. 즉, E E-와 같은 문자열이 있는 경우 E\s나 E- 패턴을 하나로 묶어서 카운팅한다는 것이다.
이렇게 복잡한 패턴 전체를 수량자로 카운팅하기 위해서는 해당 패턴을 (?:)(Non Capturing Group)이나 ()(Capturing Group)으로 그룹핑 해줘야 한다는 점도 잊지말자.
이러한 정규식 수량자의 특성을 이용하면 앞의 n글자를 카운팅하여 마스킹하지 않는 조건과 공백이나 -는 이 카운팅에 포함하지 않는다는 조건을 간단하게 만족시킬 수 있다.
function enhancedMask (str, headCount = 1) {
// \S[\s-]* 패턴이 n번 나오는 경우를 모두 묶어서 head로 할당한다
const head = new RegExp(`^(?:\\S[\\s-]*){${headCount}}`, 'g').exec(str);
// head를 제외한 나머지 부분 중 공백과 -를 제외한 부분을 마스킹한다
const tails = str.replace(head, '').replace(/[^\s-]/g, '*');
// head와 tails를 합친다
return head + tails;
}mask('E Van Moon', 2);
mask('010-1234-5678', 5);'E V** ****'
'010-12**-****'IDE 내에서 원하는 부분만 Replace하기
우리가 사용하는 대부분의 IDE나 코드 에디터들은 Find나 Replace 기능에 정규식을 사용할 수 있는 기능을 제공한다. 아무래도 코드라는 것은 특정한 패턴을 가지고 있는 문자열의 집합이다보니 단순한 문자열 검색보다는 정규식이 더 효율적일 수 있기 때문이다.
정규식을 사용하여 원하는 코드를 찾아내거나 변경하는 예시는 여러가지가 있겠지만, 그 중에서도 필자가 평소에 자주 실수하는 상황을 한번 예시로 가져와봤다.
자바스크립트의 모듈은 default 키워드를 사용하지 않고 상수나 함수 등을 그대로 export하는 경우에 모듈 자체를 하나의 객체로 평가하여 반환하게 된다.
export const Test = () => {
return <div>Test</div>;
};import { Test } from 'components/Test';이때 이 모듈을 사용하는 쪽에서는 일반적으로 위의 예시처럼 구조 분해 할당(Destructuring assignment)을 사용하여 원하는 값에 접근하게 되는데, 문제는 이 모듈의 export 방식이 중간에 변경되는 경우이다.
const Test = () => {
return <div>Test</div>;
};
// export 구문이 변경됨
export default Test;import { Test } from 'components/Test';
// Module not found: Error: Cannot resolve 'file' or 'directory'바쁘게 작업하다보면 모듈을 불러오는 부분을 크게 생각하지 않고 모듈의 export 방식을 바꾸는 실수를 하는데, 이런 경우 모듈의 export 방식을 원래대로 되돌리는 방법도 있지만, 개발자의 원래 의도가 export default로 객체 자체를 모듈로 사용하는 것일 경우에는 해당 모듈을 import하는 부분을 전부 찾아서 변경해주어야 한다.
앞서 이야기했듯이 대부분의 IDE나 에디터들은 Find와 Replace 기능에 정규식을 사용할 수 있는 기능을 제공해주고 있기 때문에, 이런 상황에서 정규식을 사용하면 간단하게 원하는 부분을 변경할 수 있다.
 정규식을 사용하면 원하는 부분만 잡아낼 수 있다
정규식을 사용하면 원하는 부분만 잡아낼 수 있다
하지만 문제는 import { Test } from 'components/Test'라는 부분 중에서 import나 from 'components/Test';처럼 Replace 후에도 유지되어야하는 부분이 있다는 것이다.
또한 모듈을 가져오는 방식이 바뀐다 뿐이지 모듈을 할당하는 변수명까지 바꿔버리면 일이 더 많아지기 때문에 왠만하면 Test라는 변수명 자체는 그대로 두는 것이 좋다.
// 요것을
import { Test } from 'components/Test';
// 요렇게 바꾸고 싶다!
import Test from 'components/Test';이런 경우에도 정규식의 캡쳐링 기능을 사용하면 정확히 원하는 부분만 캡쳐하여 유지하고 나머지는 변경할 수 있다.
자바스크립트 코드라고 해도 결국 IDE 입장에서는 단순한 문자열이기 때문에 IDE의 Replace를 사용할 때도 그냥 일반적으로 정규식을 사용하는 경우와 동일하다고 생각하면된다.
const targetCode = `import { Component } from 'components/Test';`;
targetCode.replace(/\{\s(Component)\s\}/, '$1');`import Component from 'components/Test';`;이렇게 IDE 상에서 정규식을 사용하여 코드 상의 원하는 패턴을 잡아내어 한번에 치환하는 작업은 필자가 예시로 든 저런 상황보다는 라이브러리를 업데이트했는데 브레이킹 체인지가 있다던가 전체적으로 리팩토링을 한다던가 하는 마이그레이션 작업에서 훨씬 빛을 발한다. (사실 그냥 필자가 자주 하는 실수라서 예시로 가져와봤다)
마치며
정규표현식은 단지 문자열 내에서 원하는 패턴을 매칭하여 가져오는 추상적인 도구이기 때문에 그 활용도가 어마무시한 녀석이다.
정규식은 필자가 포스팅에 적은 예시들 외에도 파일을 파싱한다던가, 크롤링으로 긁어온 데이터를 정규화한다던가, 로그 파일 내에서 원하는 정보를 빠르게 찾는다던가 하는 많은 상황 속에서 사용될 수 있는데다가 프로그래밍 언어 별로 정규표현식이 그렇게 다르지도 않으므로 한번 익혀두면 두고두고 요긴하게 써먹을 수 있는 도구라고 생각한다.
이상으로 “정규식은 어떻게 사용되는 것일까?” 포스팅을 마친다.