불규칙 속에서 규칙을 찾아내는 정규 표현식
정규식이 패턴을 인식하는 방식

개발자들은 자연어로 주어지는 문제 상황을 파악하고 프로그램을 설계하고 작성하는 사람들이다. 이런 업무를 수행하기 위해 개발자들은 불규칙하게 쏟아지는 정보들 속에서 필요한 부분들을 걸러내거나 무분별하게 선언된 클래스나 변수들을 추상화하는 등의 업무를 수행하게 된다.
이러한 일들을 해내기 위해 필요한 역량은 여러가지가 있겠지만 그 중에서도 특히 중요한 한 가지 역량은 바로 불규칙해 보이는 정보들 속에서 규칙성, 즉 패턴을 찾아내는 능력이다.
그 중에서도 일반적인 비즈니스 상황에서 접할 수 있는 가장 흔한 문제는 파일을 파싱하거나 사용자의 입력을 검증하거나 하는 경우처럼 불규칙한 문자열 속에서 패턴을 찾아내어 원하는 정보를 취득하는 경우가 많다. 그러나 이런 문제는 경우의 수가 워낙 많기 때문에 일반적인 프로그래밍만으로 문제를 해결하려고 하면 화려한 if 문이 나를 감싸는 상황을 만날 수도 있다.
바로 이런 문제를 쉽게 해결할 수 있도록 도와주는 도구가 정규식이다.
규식이형, 넌 누구냐?
정규식의 정식 풀네임은 정규 표현식(Regular Expression)이지만, 사실 정규 표현식이라는 풀네임보다는 정규식, Regex, 규식이형 등으로 더 자주 불리고는 한다.
정규식은 패턴을 표현할 수 있는 일종의 표현식이고 이 표현식을 문자열에 적용하여 원하는 부분을 쏙쏙 끄집어 낼 수 있는 굉장히 편리한 도구이지만, 그 특유의 악랄한 가독성 덕분에 왠지 모를 기피의 대상이 되고는 한다.
사실 필자도 정규식을 꽤나 자주 사용하는 편이지만, 왠만큼 자주 사용하는 표현이 아니라면 무조건 구글링을 해서 표현을 찾아보고 RegExr 사이트에서 검수를 돌려보고는 한다.
 이런 짤이 있을 정도로 정규식을 처음 보면 이게 뭔가 싶다
이런 짤이 있을 정도로 정규식을 처음 보면 이게 뭔가 싶다
하지만 정규식의 주 사용처가 문자열 내에서 패턴을 찾아내는 것이고, 이런 상황은 개발자로 일을 하다보면 자주 마주치는 상황 중 하나이기 때문에 언젠가는 반드시 정규식과 마주하게 될 일이 생기게 된다. 즉, 정규식을 무작정 피할 수도 없다는 뜻이다. (그냥 도망치는 걸 포기하면 편하다)
물론 아무 생각없이 정규식을 보았을 때는 “이게 뭔 말이야…?” 싶겠지만, 결국 아무리 긴 정규 표현식도 작은 표현들이 합쳐져서 만들어진 것이므로 막상 뜯어보면 생각보다 간단한 표현인 경우가 많다.
기본적인 정규식의 기능들
정규식에는 굉장히 다양한 키워드들이 있으며, 결국 이런 키워드들을 잘 조합하여 원하는 패턴을 잡아낼 수 있는 표현식을 만드는 것이 정규식 사용법의 전부이다. 한 마디로 이야기하자면 정규식을 시작하는 가장 기본적인 방법은 이 키워드들을 암기하는 것이다.
물론 구글에 “정규식”이라고만 검색해도 방대한 양의 자료들이 쏟아져나오기 때문에 굳이 수 많은 키워드들을 다 알아야할 필요는 없지만, 기본적인 것들이라도 암기하고 있다면 간단한 패턴 매칭 문제 정도는 딱히 구글신께 물어보지 않아도 해결할 수 있기 때문에 생산성 측면에서 이득이다. (어차피 다 외우는 건 불가능하다)
결국 이 기능을 상황에 따라 적절하게 조합하며 사용하는 것이 결국 정규식을 얼마나 잘 사용하냐는 것의 척도이므로 이번 포스팅에서는 정규식이 제공하는 기능을 간단하게 핥아만 보고, 다음 포스팅에서 실무에서 발생할 법한 예제들을 통해 설명을 더 자세히 풀어가고자 한다.
특정 문자의 그룹을 잡아내는 캐릭터 클래스
정규식에는 특정한 문자 혹은 특정한 문자들의 그룹을 의미하는 다양한 키워드들이 있다. 이렇게 특정한 문자를 찾는 녀석들을 “캐릭터 클래스(Character Class)“라고 부른다.
정규식의 핵심 기능이 내가 원하는 문자를 찾는 것이니 만큼, 캐릭터 클래스의 종류와 역할을 어느 정도 알고 있다면 간단한 정규식 정도는 구글링 없이도 대충 파악할 수 있다.
특정한 문자부터 찾아내보자
정규식에는 \d, \w 등 한 눈에 봐서는 의미를 알기 힘든 캐릭터 클래스들이 수두룩하게 포함되어 있지만, 사실 이런 요상한 키워드들만 사용되는 것은 아니다. 예를 들면 엄청 긴 문장 속에서 특정한 단어만 뽑아내고 싶다면 그냥 이렇게 작성해도 된다.
'hello, world'.match(/hello/);["hello", index: 0, input: "hello, world", groups: undefined]이처럼 정규식에는 일반 문자도 자유롭게 사용할 수 있기 때문에 특정 문자의 그룹을 의미하는 키워드인 \w, \s 등을 사용할 때 반드시 키워드의 앞에 \를 사용하여 이스케이핑을 해주는 것이다. 즉, \s는 키워드 문자이지만 s는 그냥 s다.
이러한 이스케이핑 처리 때문에 정규식에 익숙하지 않은 사람은 이게 s인지, 공백을 의미하는 \s 키워드인지 헷갈리는 경우가 많은데, 이건 사실 팁이라고 할만한 게 없다. 그냥 /\/s\.s.{1,2}/ 이런 모양을 보면 앞에서부터 하나씩 잘라가면서 읽어보도록 하자.
그리고 이렇게 정규식에 hello와 같이 특정한 문자를 사용하여 문자열 속에서 자신이 원하는 정확한 패턴을 찾아낼 수는 있지만, 이런 방식으로 특정 패턴을 찾는 것 뿐이라면 굳이 정규식을 사용하지 않더라도 include나 indexOf, search 같은 String.prototype 메소드들에 일반 문자열을 인자로 사용하는 것만으로도 충분하기 때문에 큰 의미가 없다.
정규식의 진짜 힘은 이런 특정 문자열을 찾는 것이 아니라 내가 원하는 문자열의 그룹을 찾아내는 것에 있다.
원하는 문자의 그룹을 만들어보자
만약 우리가 유저의 입력이 오직 영어로만 이루어져있는지 검증을 해야하는 상황이라고 생각해보자. 물론 영어는 대소문자를 모두 합쳐 총 48개의 문자로 이루어져 있기 때문에 알파벳으로 이루어진 맵이나 배열을 만들어서 일일히 검증하거나, 최악의 경우에는 논리 조건 48개를 || 연산자로 묶어서 써도 된다. (예외 처리까지 합치면 논리 조건 49개…)
하지만 이 방법이 그다지 쿨한 방법이 아니라는 것에는 다들 어느 정도 동의할 것이라고 생각한다. 게다가 영어만 검사하는 것이 아니라 숫자까지 포함되었는지를 검사한다던가, 영어가 n번 반복하는 것을 검사한다던가 하는 식으로 조건이 추가되면 추가될수록 필요한 논리도 늘어나기 때문에 코드는 점점 더 복잡해진다.
const alphabet = ['a', 'A', 'b', 'B', 'c', 'C', 'd', ..., 'Z'];
const isAlphabet = (string: string) => {
return string
.split('')
.every(char => alphabet.includes(char));
}그래서 정규식은 사용자가 커스텀한 그룹을 만들어서 원하는 문자를 잡아낼 수 있는 기능 또한 제공해준다. 사용하는 방법 또한 심플한데, 단순히 대괄호([]) 안에 그룹핑하고 싶은 문자들을 넣어주면 된다.
// x 또는 y 또는 z를 잡아내라!
/[xyz]/
// x 또는 y 또는 z가 아닌 것을 잡아내라!
/[^xyz]/
// a~z까지 잡아내라!
/[a-z]/
// a~z, A~Z까지 잡아내라!
/[a-zA-Z]/물론 대괄호 안에는 일반 문자만 들어갈 수 있는 것은 아니고, - 키워드를 사용하여 문자의 범위를 표현할 수도 있고, 맨 앞에 ^ 문자를 붙힘으로써 “Not” 또한 표현할 수 있다.
그리고 위 표현 중 a-z와 같이 문자의 범위로 그룹을 설정하는 문법도 등장하는데, 이 범위는 Ascii Table에서의 범위를 의미한다.

위 테이블을 보면 영어 대문자 그룹(65 ~ 90)과 소문자 그룹(97 ~ 122) 사이에 [나 ^과 같은 특수 문자들이 포함되어 있는 것을 볼 수 있는데, 정규식은 이 아스키 코드를 기반으로 작동하기 때문에 영어만 잡아내고 싶다고 a-Z와 같은 범위로 문자열 그룹을 잡아버리면 저 사이에 있는 특수문자들까지도 그룹에 포함되어버린다.
그래서 필자는 영어만 따로 걸러내기 위해 a-z와 A-Z 범위를 구분해서 정규식에 표현해준 것이다.
이런 식으로 아스키 코드에 대한 지식이 있다면 - 문자 범위 키워드를 사용하여 손 쉽게 원하는 문자열의 그룹을 만들어 낼 수 있고, 사실 아스키 코드에 대해 잘 모르더라도 구글에 “Ascii Table”이라고 검색하면 저런 코드표가 쏟아져 나오기 때문에 그냥 저 테이블을 보면서 정의해도 된다.
하지만 매번 이렇게 그룹을 직접 설정하는 것 또한 어찌보면 귀찮은 일이다. (개발자는 게으를수록 일을 잘 하…) 그래서 정규식은 친절하게도 사용자가 매번 이렇게 직접 그룹을 정의하지 않아도 되도록 미리 정의된 몇 가지 그룹을 지원한다.
.
새로운 라인을 의미하는 \n 이스케이프를 제외한 모든 문자 하나를 의미한다. 즉, 그 문자가 무엇이든 상관없이 그냥 문자라면 모두 매칭한다. 당연히 이 문자라는 것의 정의에는 공백도 포함하기 때문에 I am Evan과 같이 공백을 포함한 문자열에 . 캐릭터 클래스를 사용한다면 공백도 포함하여 검색된다.
// 문자열의 시작부터 4글자 매칭해!
'I am Evan'.match(/^..../g);["I am"]만약 이 캐릭터 클래스를 앞서 말한 커스텀 그룹으로 표현하려면 아스키 코드에서 \n를 제외한 모든 문자를 대괄호 안에 넣어야한다는 이야기인데, 이건 당연히 불가능하다. 그래서 이런 캐릭터 클래스를 잘 사용하는 것이 정규식을 편하게 작성할 수 있는 첫 걸음이라고 하는 것이다.
\d, \D 클래스
d 키워드는 Digit, 즉 숫자를 표현하는 문자를 의미한다. 이 숫자 또한 아스키 코드 상으로는 0 ~ 9(33 ~ 52)인 문자를 의미하기 때문에, II나 五와 같은 문자는 숫자로 판단되지 않는다.
소문자인 \d 키워드는 숫자에 해당하는 문자를, 대문자인 \D는 숫자가 아닌 문자를 의미한다.
'010-1111-1111'.match(/\d/g);// -를 제외한 0-9까지의 문자가 매칭된다
["0", "1", "0", "1", "1", "1", "1", "1", "1", "1", "1"]\w, \W 클래스
w 캐릭터 클래스는 Word를 의미한다. 이때 정규식에서 정의하는 Word라는 녀석들은 아스키 코드 상으로 A ~ Z(65 ~ 90), a ~ z(97 ~ 122), 그리고 앞서 설명한 \d(숫자) 그룹에 해당하는 녀석들이다.
즉, 저 아스키 코드 범위에 포함되지 않는 한글, 키릴 문자 등은 Word가 아니므로 \w 키워드로는 잡아낼 수 없다는 점을 주의해야한다. 이 녀석도 d 클래스와 마찬가지로 소문자인 \w는 Word인 문자를 의미하고, 대문자인 \W는 Word가 아닌 문자를 의미한다.
'Phone(전화): 010-0000-1111'.match(/\w/g);// :과 -, 그리고 한글은 Word에 포함되지 않으므로 영어와 숫자만 매칭된다
["P", "h", "o", "n", "e", "0", "1", "0", "0", "0", "0", "0", "1", "1", "1", "1"]\s, \S 클래스
s 키워드는 Space라는 의미이며, 말 그대로 공백 문자를 의미한다. s 키워드도 다른 녀석들과 마찬가지로 소문자인 \s는 공백인 문자, 대문자인 \S는 공백이 아닌 문자를 의미한다.
'Hi, my name is Evan'.match(/\s/g);// 위 문자열에 존재하는 4개의 공백이 매칭된다
[" ", " ", " ", " "]문자가 아닌 경계를 잡아내는 앵커
앞서 우리가 살펴보았던 키워드들은 모두 하나의 문자를 의미하는 키워드들이었지만, 정규식은 특정 문자가 아닌, 문자와 문자 간의 경계를 매칭할 수 있는 기능 또한 제공한다.
이렇게 경계를 잡아내는 키워드들을 “앵커”라고 부른다. 앵커는 단지 경계만을 의미하기 때문에 보통 단독으로 쓰이기 보다는 캐릭터 클래스와 함께 조합하여 특정 경계 뒤나 앞에 위치하는 문자를 잡아내는 방식으로 사용된다.
앵커는 말 그대로 “경계” 그 자체를 잡아내는 것이기 때문에 앵커만 단독으로 사용하게 된다면 매칭 결과로 길이가 0인 문자열이 반환된다.
^, $ 앵커
^ 앵커는 문자열이 시작하는 경계, $는 문자열이 끝나는 경계를 의미한다.
// ^(문자열 시작 경계) 바로 뒤에 위치한 문자만 매칭해라
`Evans Library`.match(/^./);
> ["E", index: 0, input: "Evans Library", groups: undefined]// $(문자열 끝 경계) 바로 앞에 위치한 문자만 매칭해라
`Evans Library`.match(/.$/);
> ["y", index: 12, input: "Evans Library", groups: undefined]당연한 이야기겠지만 문자열의 시작 경계인 ^ 앞에 위치하는 문자나, 문자열의 끝 경계인 $ 뒤에 위치하는 문자라는 것은 존재할 수 없기 때문에 .^이나 $.과 같은 표현식은 아무것도 매칭할 수가 없다.
\b, \B 앵커
b 키워드는 Boundary를 의미하며, 이 바운더리라는 녀석은 Word 그룹으로 이루어진 단어 간의 모든 경계를 의미한다. 즉, 쉽게 말하자면 문자열의 시작과 끝 경계를 의미하는 ^이나 $ 앵커의 상위호환이라고 볼 수 있다.
이 앵커를 사용할 때 주의해야할 점은 “Word 그룹으로 이루어진 단어”이기 때문에 \w 그룹에 포함되는 영어나 숫자에만 한정되는 이야기라는 것이다.
문자열의 시작과 끝이라는 명확한 정의와는 다르게 막연하게 단어 간의 경계라고만 이야기하면 조금 이해가 안될 수도 있는데, 직접 예시를 보면 생각보다 그렇게 어렵지 않다.
'abc def'.match(/\b/g);["", "", "", ""]이 예시에서 필자는 \b 키워드를 사용하여 abc def라는 문자열 내의 모든 단어 경계를 잡아냈다. 그리고 그 결과물을 보면 모두 길이가 0인 문자열이 나온 것을 알 수 있다. 앞서 이야기했듯이 경계라는 것은 어떤 문자가 아니기 때문에 길이가 없다고 보는 것이다.
방금 필자가 예시로 사용한 abc def라는 문자열 내의 단어들 간의 경계는 다음과 같다.
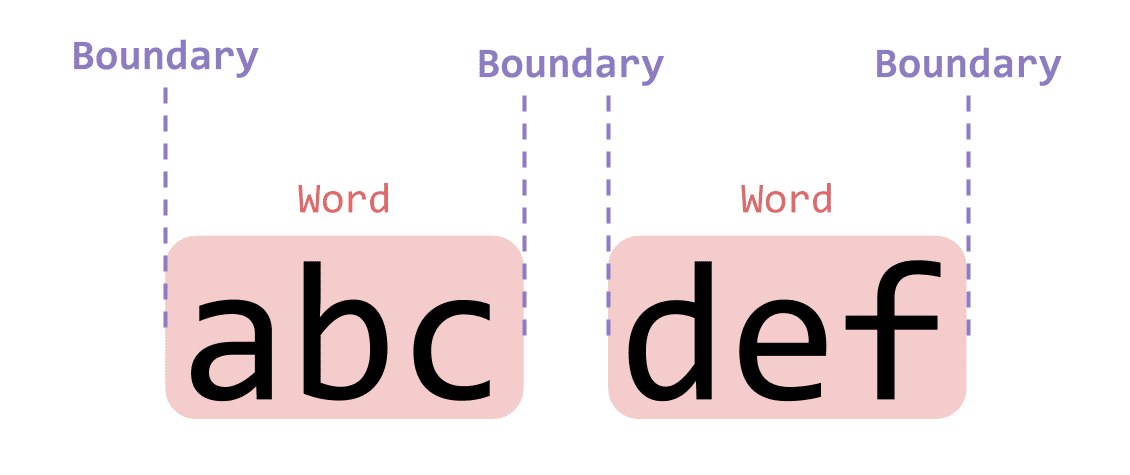 복잡하게 생각할 것 없이 각 단어의 경계가 어디인지 생각해보면 된다
복잡하게 생각할 것 없이 각 단어의 경계가 어디인지 생각해보면 된다
이에 반해 대문자인 \B 키워드는 단어 간의 경계가 아닌 부분을 잡아낸다. 쉽게 이야기하면 단어가 끝나지 않는 경계 부분을 잡아낸다는 것이다.
'abc def'.match(/\B/g);["", "", "", ""]이번에도 이전과 같이 4개의 경계가 뽑혀져 나왔지만 이번에는 이 경계들의 의미하는 바가 전혀 다르다. 이번에 뽑혀져 나온 경계는 “단어가 끝나지 않은 부분의 경계”이기 때문이다.
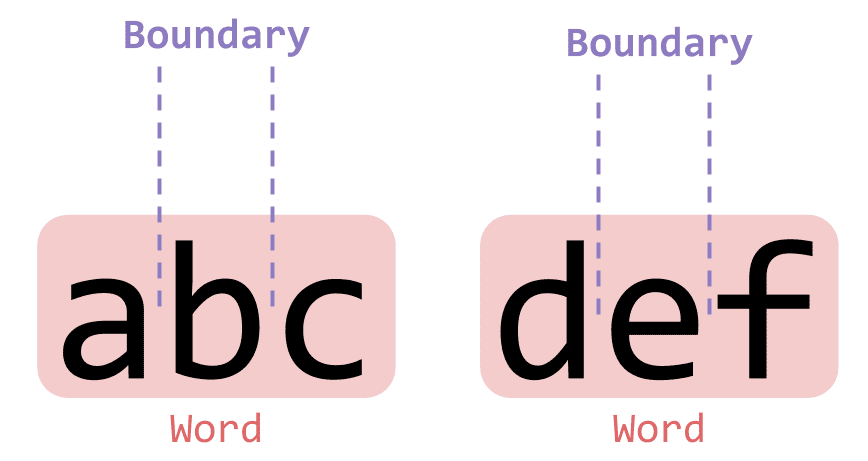 단어가 끝나지 않은 부분의 경계
단어가 끝나지 않은 부분의 경계
즉, b 키워드는 다른 키워드들과 다르게 어떤 하나의 문자를 매칭하는 것이 아니라 경계를 잡아내는 것이기 때문에, 이 특징만 잘 기억하고 있으면 은근히 여기저기 잘 써먹을 수 있다.
정규식의 옵션 기능, 플래그
정규식을 보다보면 종종 정규식의 맨 뒤에 /정규식/g와 같이 g, i, m 등의 문자가 추가로 붙는 것을 발견할 수 있는데, 이 친구들은 일종의 옵션 기능 역할을 가지고 있는 “플래그”이다.
/를 사용하여 정규식을 리터럴 선언하는 하는 경우가 아니라 new RegExp() 생성자를 호출하여 정규식을 사용하는 경우에는 생성자 함수의 두번째 인자로 플래그를 살포시 넣어주면 된다.
const regex = /정규식/gi;
const regex2 = new RegExp(/정규식/, 'gi');
// 이 두 개는 같은 패턴을 가진 정규식이다
console.log(regex.flags === regex2.flags);true정규식은 g, i, m, s, u, y 총 6개의 플래그를 제공하고 있지만, 이 포스팅에서는 이 중 가장 많이 사용되는 g와 i, 그리고 m 플래그에 대해서만 간단하게 설명할 예정이니, 나머지 플래그가 궁금하다면 구글링을 해보도록 하자.
g 플래그
g 플래그는 global의 약자로, 이 플래그를 가지고 있는 정규식은 주어진 문자열 내에서 패턴과 매칭되는 모든 부분을 찾아낸다. 만약 g 플래그가 없다면 정규식은 문자열 내에서 가장 처음 매칭되는 한 부분만을 찾아낼 것이다.
const regex = /./;
'hello, world'.match(/./);
'hello, world'.match(/./g);["h", index: 0, input: "hello, world", groups: undefined]
["h", "e", "l", "l", "o", ",", " ", "w", "o", "r", "l", "d"]기본적으로 글로벌 매칭을 의미하는 플래그인 g 플래그가 없다면 정규식은 단 하나의 문자만을 매칭하지만, g 플래그를 사용하면 문자열 내에서 해당 정규식에 매칭되는 모든 문자를 찾아낸다. 글로벌 플래그에 관한 것은 필자가 굳이 설명하지 않아도 콘솔에서 몇 번 해보다보면 감이 올테니 자세히 설명하지는 않겠다.
i 플래그
i 플래그는 ignoreCase의 약자로, 정규식 내에 사용된 문자열의 대소문자를 구분하지 않고 모두 매칭하겠다는 의미를 가진다.
const regex = /abcd/i;
regex.test('abcd'); // true
regex.test('ABCD'); // true일반적으로 유저의 입력을 통해 생성된 문자열은 My name is Evan, my name is evan 등과 같이 사람에 따라 대소문자의 사용 방법이 조금씩 다를 수 있지만, i 플래그를 사용하면 이런 걱정없이 맘 편하게 원하는 문자열을 찾아낼 수 있다.
m 플래그
m 플래그는 multiline의 약자로, 말 그대로 여러 라인으로 구성된 문자열을 검사하겠다는 것을 의미한다. 하지만 한 가지 이상한 점은 딱히 이 플래그가 없어도 정규식은 여러 줄로 된 문자열을 잘 매칭한다는 것이다.
한번 템플릿 스트링을 사용하여 여러 라인으로 구성된 문자열을 만들어보고 정규식을 사용하여 간단한 패턴을 잡아내보도록 하겠다.
const string = `abcd\nefgh\nijkl`;
string.match(/\w{2}/g);["ab", "cd", "ef", "gh", "ij", "kl"]사실 정규식은 그냥 주어진 문자열 중에서 매칭되는 패턴을 찾아내는 녀석이기 때문에 굳이 m 플래그를 사용하지 않아도 여러 줄의 문자열도 잘 매칭한다.
그렇다면 굳이 m 플래그가 필요한 이유가 무엇일까? 그 이유는 정규식이 바로 새로운 라인을 표현하는 \n 이스케이프를 어떻게 바라보게 할 지 정할 수 있기 때문이다.
이번에는 방금 작성했던 정규식에 문자열의 시작을 의미하는 ^ 앵커를 추가해서 단순히 \w 그룹의 두 글자가 아닌 문자열의 시작 부분의 두 글자를 잡아보도록 하겠다.
string.match(/^\w{2}/g);["ab"]단순히 \w 그룹의 두 글자를 잡아낼 때와는 다르게 이번에는 ab만 뽑혀나오는 것을 확인할 수 있는데, 이는 문자열 내에서 \n 이스케이프로 라인이 나누어져있더라도 정규식에게는 그저 하나의 문자열이라고 인식되기 때문이다.
기본적으로 정규식은 하나의 문자열 객체를 기준으로 패턴을 매칭하기 때문에 전체 문자열의 첫 글자인 a 앞에 있는 경계만 문자열의 시작(^)이라고 판단한 것이다.
바로 이런 상황일 때 m 플래그를 사용하면 이전과는 다른 결과를 만들어낼 수 있다.
string.match(/^\w{2}/gm);["ab", "ef", "ij"]쨘, 이번에는 하나의 문자열이 아니라 \n 이스케이프를 기준으로 각각 별도의 문자열로 평가되어 정규식이 적용되는 것을 볼 수 있다. 즉, m 플래그는 단순히 여러 줄의 문자열을 검사한다는 의미가 아니라 \n 이스케이프 문자를 기준으로 라인을 나누어 각각의 문자열을 하나의 검사 대상으로 보겠다는 의미인 것이다.
 m 플래그가 있냐 없냐에 따라 각각의 라인을 통합하여
m 플래그가 있냐 없냐에 따라 각각의 라인을 통합하여하나의 문자열로 볼 것인지, 각각의 문자열로 볼 것인지가 결정된다.
m 플래그 같은 경우는 짧은 문자열을 다루는 상황보다는 개행이 포함된 긴 문자열을 다루는 상황일 때 사용하게 되는데, 필자 또한 비즈니스 내에서 유저의 간단한 입력을 검사하는 경우보다는 행이 변경될 때마다 가장 첫 글자를 대문자로 적어야하는 영문법을 검사한다던가, 비압축 파일을 파싱한다던가 하는 경우에 주로 사용했었던 것 같다.
패턴이 몇 번이나 나왔는지 찾아주는 수량자
방금 전 예시에서 필자는 \w 그룹의 두 글자를 찾아내기 위해 {2}라는 표현을 사용했었다. 이 표현은 바로 앞에 오는 표현의 반복 횟수를 의미하는데, {0,2}처럼 최소, 최대 반복 횟수를 사용하여 반복되는 범위를 표현해줄 수도 있다.
이렇게 앞에 위치한 패턴이 몇 번이나 일치하는지를 잡아낼 수 있는 표현을 수량자라고 한다.
반복되는 횟수를 명시해보자
'aaaabbbcc'.match(/\w{3}/g);["aaa", "abb", "bcc"]필자가 사용한 \w{3}이라는 표현은 단순히 Word 그룹이 3번 반복되는 패턴을 찾으라는 표현이기 때문에, 정규식은 문자열 전체에서 Word 그룹이 3번 반복되고 있는 케이스를 뽑아내고 있는 것을 볼 수 있다.
사실 반복이라는 패턴은 굉장히 여러 곳에 응용될 수 있는데, 그 중 대표적인 예가 바로 전화번호나 주민등록번호처럼 같은 그룹의 문자가 일정 횟수 이상 반복되는 것이 정해져있는 정보이다.
'010-0101-0101'
'02-0101-0101'
'031-010-0101'대한민국의 전화번호는 대부분 이 3가지 패턴 안에서 결정되는데, 휴대폰 번호같은 경우 반드시 맨 앞에는 3자리의 통신사 식별번호가 위치하고 그 뒤에는 4자리의 전화번호 필드가 두 번 반복되는 형태를 가지며, 그 외 유선전화는 2-3자리의 지역번호 뒤로 3-4 자리의 필드와 4자리의 필드가 반복되는 형태를 가진다.
이런 경우 수량자를 사용하면 간단하게 원하는 패턴을 잡아낼 수 있다.
// 휴대폰 번호를 잡아내는 패턴
/01[0|1|6|8|9]-\d{3,4}-\d{4}/;이 패턴을 보고 나이가 어리신 분들은 “왜 010으로 안 잡고 굳이 저런 숫자들을 넣어주는거지?”라는 의문을 가지실 수도 있는데…
 한국인의 통신채널, 스피드 011...
한국인의 통신채널, 스피드 011...
사실 휴대폰 통신사 식별번호는 010만 있는 것이 아니다. 예전에는 011, 016, 018 등 다양한 통신사 식별번호가 있었다가 나중에 010으로 통합된 것이라 아직도 이런 구 식별번호를 사용하시는 분들이 있을 수도 있기 때문에 이런 로직을 작성할 때는 주의하도록 하자. (이제 이거 알면 빼박 늙었다는 증거…)
원하는 패턴이 한번 이상 출현했는지 알아보자
이렇게 정규식은 간단하게 반복되는 횟수를 명시하여 수량자 앞에 위치한 패턴이 얼마나 반복되었는지를 표현할 수 있지만, 이 수량자는 너무 명확한 표현이라서 “있거나 없을 수도 있다”라던가 “n개 이상 등장”과 같은 추상적인 패턴을 표현하기에는 적합하지않다.
그렇기 때문에 정규식은 n개 이상과 같이 조금 더 추상적인 패턴의 등장 횟수를 매칭할 수 있는 수량자들 또한 제공해주고 있다.
* 수량자
* 수량자는 이전에 등장한 패턴이 0회 이상 등장하는지 여부를 나타내는 수량자이다. 0회 이상이란 표현이 조금 애매할 수 있는데, 조금 더 풀어서 이야기하면 이 수량자 앞에 위치한 패턴은 등장하지 않을 수도 있고 여러 번 반복될 수도 있다는 뜻이다.
// b 앞에 위치한 a는
// 없어도 되고 여러 번 나와도 다 잡아라!
const regex = /a*b/g;
'b'.match(regex);
'ab'.match(regex);
'aab'.match(regex);['b']
['ab']
['aab']* 수량자 앞에 위치한 패턴은 아무리 많이 등장해도 전부 잡히기 때문에 a의 갯수가 아무리 늘어난다하더라도 모두 잡아낼 수 있게된다.
? 수량자
? 수량자는 이전에 등장한 패턴이 0 또는 1회 등장하는지 여부를 나타내는 수량자이다. * 수량자와는 다르게, ? 수량자 앞에 위치한 패턴은 아무리 많이 등장하더라도 단 한 개만 잡아낼 수 있다.
// b 앞에 위치한 a는
// 없어도 되고 여러 번 나와도 1개만 잡아라!
const regex = /a?b/g;
'b'.match(regex);
'ab'.match(regex);
'aab'.match(regex);['b']
['ab']
['ab']+ 수량자
+ 수량자는 이전에 등장한 패턴이 반드시 한 번 이상 등장해야한다는 것을 의미한다. 즉 + 수량자 앞에 위치한 패턴이 등장하지 않는다면 매칭에 실패하게 된다.
// b앞에 위치한 a는
// 반드시 존재해야하고 여러 번 나와도 다 잡아라!
const regex = /a+b/g;
'b'.match(regex);
'ab'.match(regex);
'aab'.match(regex);null
['ab']
['aab']+ 수량자의 의미를 조금 더 쉽게 설명해보자면 “몇 번이든 좋으니까 있기만 하면 된다”라는 의미이기 때문에 문자열 중에서 반드시 존재해야하는 문자를 잡아낼 때 유용하게 사용할 수 있다.
알면 더 효율적인 기능들
지금까지 정규식이 제공하는 기본적인 기능인 캐릭터 클래스, 앵커, 플래그 그리고 수량자에 대해 알아보았다. 사실 이 정도만 알고 있어도 일반적인 비즈니스 상황에서 정규식을 사용하는데에는 큰 무리가 없지만, 간혹 이 기능만으로는 처리가 귀찮은 상황들이 터지게 된다.
지금부터는 조금 더 편하게 정규식을 사용하기 위해서 알고 있으면 좋은 기능들에 대한 이야기를 해보도록 하겠다.
패턴을 기억하는 캡처링
정규식은 단순히 문자열 내에서 패턴을 매칭하기만 하는 것이 아니라, 매칭된 패턴을 기억하고 있을 수 있는 기능도 제공한다. 이렇게 패턴을 기억할 수 있는 기능은 문자열을 치환하는 작업을 진행할 때 변경되면 안 되는 부분과 변경되어야 하는 부분을 구분하여 원하는 부분만 바꿔치거나, 중복 입력된 부분을 찾는 등의 작업에서 꽤나 유용하게 사용된다.
예를 들어 $10000과 같이 달러 단위를 의미하는 문자열이 있다고 생각해보자. 이 문자열을 잡아낼 수 있는 패턴은 무엇일까?
길게 생각할 것도 없이 달러 단위를 의미하는 문자열은 $ 뒤에 반드시 한 개 이상의 숫자가 위치하여야 정보성이 있다고 판단할 수 있기 때문에 간단하게 $문자와 그 뒤에 오는 1개 이상의 숫자를 잡아낼 수 있는 표현을 사용하면 우리는 원하는 패턴을 잡아낼 수 있다. (그냥 $는 문자열의 끝을 나타내는 앵커이기 때문에 반드시 앞에 \를 붙혀 이스케이핑해주는 것을 잊지말자)
'$10000'.match(/\$\d+/g);["$10000"]자, 이렇게 정규식을 통해 잡아낸 $10000라는 문자열을 10000 달러라는 문자열로 변경하고 싶다면 어떻게 할 수 있을까?
간단하게 생각하면 String.prototype.replace 메소드를 사용하면 될 것 같지만, 위 정규식을 사용하여 잡아낸 패턴은 $10000 전체이기 때문에 10000이라는 문자만 그대로 유지하며 $ 부분만 치환하는 것은 불가능하다.
즉, 이 문제를 해결하기 위해서는 패턴을 매칭된 부분 중 특정 부분을 기억하는 기능이 필요한 것이다. 바로 이런 상황일 때 캡쳐링을 사용하면 문제를 쉽게 해결할 수 있다.
// 기억하고자 하는 부분을 괄호로 감싸자!
/\$(\d+)/이 표현이 이전 표현과 다른 점은 단지 \d+ 부분을 괄호로 감싼 것 뿐이지만, 이렇게 특정 표현을 괄호로 감싸게 되면 정규식은 이 부분을 캡쳐링하게 된다.
String.prototype.replace 메소드의 두 번째 인자는 치환될 문자열을 의미하는데, 이렇게 캡쳐링된 패턴은 치환될 문자열 내에서 $n이라는 특수한 표현으로 다시 불러올 수 있다.
'$10000'.replace(/\$(\d+)/, '$1 달러');"10000 달러"$1은 단지 정규식 패턴 내에서 캡처링된 첫 번째 그룹을 의미하는 것이기 때문에 캡처링된 패턴이 늘어나면 $2나 $3처럼 두 번째, 세 번째 패턴을 계속 불러올 수도 있다.
그리고 이렇게 특정한 패턴을 캡처하여 기억할 수 있는 기능은 반복되는 문자를 찾아내는 데에도 유용하게 사용될 수 있는데, 반복되는 문자라는 것 자체가 이전에 나타난 문자가 그 다음에 연속해서 다시 나타나는 것을 의미하기 때문이다.
/(\w)\1/이 정규식에서 필자는 (\w) 표현을 사용하여 문자열 내의 Word 그룹에 속한 글자를 캡처링하였고, 이후 \1이라는 표현을 사용하여 캡처링한 패턴을 다시 불러왔다.
즉, \w에 매칭된 패턴을 \1을 통해 불러옴으로써 반복이라는 패턴을 표현할 수 있는 것이다.
'aabccdeef'.match(/(\w)\1/g);["aa", "cc", "ee"]이렇게 문자열 내에 동일한 문자가 반복되는 패턴을 찾아내는 표현은 (.)\1{2}와 같이 수량자와 조합되어 “동일한 글자가 3번 이상 반복되면 안 됨”과 같은 비밀번호 검증 로직에 유용하게 사용되기도 한다.
Greedy vs Lazy
앞서 우리는 1개 이상 존재하는 패턴을 매칭하는 + 수량자와 0개 이상 존재하는 패턴을 매칭하는 * 수량자에 대해 알아보았었다. 이렇게 n개 이상이라는 수량자를 사용하게 되면 패턴을 매칭할 때 약간은 애매한 부분이 생기게 되는데, 바로 이런 케이스이다.
// <, >으로 감싸진 모든 문자열을 찾아라!
const regex = /<.*>/g;
"<p>This is p tag</p>".match(regex);["<p>This is p tag</p>"]필자가 사용한 정규식은 단지 <, >으로 감싸진 모든 문자열을 찾으라는 표현이기 때문에 <과 >으로 감싸진 <p>This is p tag</p> 전체를 잡아내는 게 당연한 것이 아닌가하고 생각할 수도 있지만, 사실 <과 >으로 감싸진 패턴은 저 하나만 존재하는 것이 아니다.
바로 <p>와 </p>도 위 정규식이 잡아낼 수 있는 범주에 들어가는 패턴이기 때문이다. 하지만 정규식은 기본적으로 <p>This is p tag</p>와 같이 최대한 길게 매칭되는 패턴을 잡도록 세팅되어있기 때문에, 결과가 이렇게 나오는 것이다.
이때 이렇게 최대한 길게 매칭되는 패턴을 잡으려는 매칭 방법을 탐욕(Greedy) 매칭이라고 한다. 말 그대로 탐욕스럽게 최대한 길게 매칭되는 부분을 먹어버리는 것이다. (매 순간 항상 최적의 선택을 하는 의미의 Greedy 알고리즘이랑은 용어만 같고, 사실 상 다른 개념이다)
그렇다면 위 패턴을 사용하여 작은 매칭 단위인 <p>와 </p>를 잡아내고 싶다면 어떻게 하면 될까?
바로 정규식을 게으르게(Lazy) 만들면 된다.
// <, >으로 감싸진 모든 문자열을 게으르게 찾아라!
const regex = /<.*?>/g;
"<p>This is p tag</p>".match(regex);["<p>", "</p>"]이전 표현과 비교했을 때 달라진 부분은 “0개 이상의 패턴”을 의미하는 * 수량자의 뒤 쪽에 ?를 붙혔다는 것이다. 이렇게 게으른 매칭을 사용하게 되면 정규식은 매칭할 수 있는 패턴들 중 가능한 가장 짧은 패턴들을 찾게된다. 같은 표현을 가지고 패턴을 찾으라고 일을 시켰을 때, 최대한 짧은 패턴만 찾고 일을 마치려고 하니 게으르다고 표현하는 것이다.
정리하자면 *나 +과 같이 n개 이상을 나타내는 수량자는 기본적으로 매칭할 수 있는 패턴 중 가장 긴 것을 탐욕(Greedy)스럽게 매칭하고, 이 수량자 뒤 쪽에 ?를 붙히게 되면 게으르게(Lazy) 매칭할 수 있는 패턴 중 가장 짧은 것을 매칭하게 되는 것이다.
// Greedy
/<.*>/
/<.+>/
// Lazy
/<.*?>/
/<.+?>/이렇게 Greedy, Lazy 매칭의 차이를 모르고 있다면 방금 전 예시의 <p>This is p tag</p> 처럼 매칭할 수 있는 패턴의 종류가 여러 개인 경우 원하는 패턴을 잡아낼 수 없으니, 이 차이를 잘 기억해두도록 하자.
마치며
필자는 대학생 때 정규식을 처음 접하게 되었었는데, 당시 OBJ 파일을 ThreeJS 객체로 표현하는 일종의 파서를 만들고 있었기 때문에 정규식을 상당히 하드하게 사용해야 했었던 기억이 난다. (당시 ThreeJS에서 제공하는 OBJ Loader에 버그가 있었다 😢)
OBJ 파일은 각 버텍스의 좌표와 텍스쳐의 UV 매핑 좌표, 그리고 각 버텍스들의 방향을 나타내는 노말 등을 다음과 같이 나타내는 파일이다.
# 버텍스 좌표
v -1.692615 -0.021714 -1.219301
v 7.334266 -0.021714 -1.219302
v 7.334265 0.021714 -1.219302
v -1.692616 0.021714 -1.219301
v -1.692616 -0.000000 -1.241016
v 7.334265 0.000000 -1.241017
v 7.334266 0.000000 -1.197588
v -1.692615 -0.000000 -1.197587
# 텍스처 UV 값
vt 0.0000 0.0000
vt 1.0000 0.0000
vt 1.0000 1.0000
vt 0.0000 1.0000
vt 0.0000 0.0000
vt 1.0000 0.0000
vt 1.0000 1.0000
vt 0.0000 1.0000
# 버텍스의 노말 값
vn -0.0000 -0.0000 -1.0000
vn 0.0000 -1.0000 -0.0000
usemtl Material.001
# 각 페이스를 구성하는 버텍스의 인덱스들
f 1/1/1 4/2/1 3/3/1 2/4/1
f 8/5/2 5/6/2 6/7/2 7/8/2이때 필자는 이 파일을 읽어와 앞서 설명한 정규식의 m 플래그를 사용하여 각각의 라인 별로 나눈 후, v로 시작하면 버텍스 좌표, vt로 시작하면 텍스쳐의 uv, vn으로 시작하면 버텍스의 노말값 등으로 파싱을 해야했었는데, 물론 어렵고 복잡한 과정이기는 했지만 재미있기도 했던 기억이 있다.
컴퓨터가 만든 파일이라는 것이 사실은 어떤 의미를 가진 문자열의 연속이라는 사실도 새로웠지만, 정규식을 사용하여 이 문자열을 의미있는 정보로 가공할 수 있다는 게 더 재밌었다.
하지만 앞서 이야기했듯이 정규식은 이런 파서를 만들 때보다 일반적인 비즈니스 로직 상에서 더 자주 사용된다. 비밀번호나 이메일 주소 등 사용자가 틀릴 가능성이 높은 입력을 검사할 때 정규식은 말 그대로 치트키처럼 사용될 수 있다.
 물론 기본적으로 제공되는 메소드들을 잘 사용해도 검사는 할 수 있지만, 정규식으로 훨씬 간단하게 해결할 수 있다
물론 기본적으로 제공되는 메소드들을 잘 사용해도 검사는 할 수 있지만, 정규식으로 훨씬 간단하게 해결할 수 있다
만약 정규식을 모른다면 이메일 주소와 같은 간단한 문자열의 유효성을 검증하기 위해서 여러 개의 빌트인 메소드들을 조합하여 검사해야하기 때문에 꽤나 비효율적이다. 게다가 개인적으로는 아무리 정규식이 읽기가 어렵다지만 이렇게 복잡한 메소드들의 조합보다는 차라리 정규식이 가독성이 더 좋은 것이 아닌가하는 생각도 있다.
물론 정규식은 코드처럼 라인이나 인덴트가 나누어져 있지도 않기 때문에 마치 무의미한 문자들의 나열처럼 보인다. 하지만 어차피 정규식이 제공하는 표현은 그렇게 많은 편이 아니기 때문에 조금만 사용하다보면 짧은 정규식 정도는 누구나 금방 이해할 수 있을 정도라고 생각한다.
이상으로 불규칙 속에서 규칙을 찾아내자 포스팅을 마치며, 다음 포스팅에서는 필자가 지금까지 개발자로 일을 하면서 정규식을 실제로 사용했던 사례들을 토대로 정규식을 설명하는 내용을 풀어볼 예정이다.