어떻게 하면 안전하게 함수를 합성할 수 있을까?
펑터와 모나드로 함수 합성의 실패를 다루는 법

함수형 프로그래밍에서 코드를 작성한다는 것은 프로그램에서 수행해야하는 여러가지 행위들을 함수로 표현하고, 또 그 함수들을 요리조리 잘 합성해가며 거대한 프로그램을 만들어나가는 패러다임이다.
결국 함수형 프로그래밍에서 함수를 합성하는 행위라는 것은 이 패러다임의 근간이 되는 개념이기 때문에 굉장히 큰 의미를 가질 수 밖에 없는데, 문제는 이렇게 함수를 합성하는 과정에서 크고 작은 현실적인 문제들이 빵빵 터진다는 것이다.
이런 문제가 빵빵 터지는 가장 큰 이유는 간단하다. 아무리 우리가 순수 함수를 사용한다고 해도 수학의 함수와 완벽하게 똑같을 수는 없기 때문이다. 애초에 프로그래밍과 수학은 비슷하지만 엄연히 다른 학문이다.
그래서 전 세계의 똑똑이들은 이런 문제들을 해결하기 위해 펑터(Functor)나 모나드(Monad)와 같은 수학의 개념들을 끌고 와서 사용하기 시작했는데, 문제는 이 개념들이 직관적으로 이해하기에는 너무나도 추상적이고 난해한 녀석들이라는 것이다.
 보기만 해도 눈물이 절로 나오는 펑터 설명 다이어그램...
보기만 해도 눈물이 절로 나오는 펑터 설명 다이어그램...
필자가 펑터나 모나드에 대한 공부를 하면서 구글링을 하면서 찾아본 많은 자료들은 대략 두 가지 정도로 나누어졌는데, 바로 “겁나 어려운 수학적인 설명”과 “코드로 된 예시”였다.
문제는 이 수학적인 설명과 코드로 된 예시 사이를 이어주는 자료가 별로 없었다는 것이다. 즉, 펑터나 모나드가 정확히 프로그래밍의 어떤 문제를 해결하기 위해 도입된 것인지 쉽게 풀어서 설명해놓은 자료가 별로 없었다. (남들은 다 이해하는데 필자가 멍청해서 이해를 못한 것일수도 있다)
하지만 그렇다고해서 제대로 된 이유도 모르고 펑터나 모나드를 사용하고 싶지는 않았기에 직접 조사해보고 조져보기로 했다.
그래서 이번 포스팅에서는 함수형 프로그래밍에서 별 생각없이 함수를 조합하면 어떤 문제들이 발생하는지, 그리고 그 문제들을 어떤 방식으로 해결할 수 있는 지에 대한 이야기를 해보려고 한다.
모든 것은 함수의 합성으로 이루어진다
다시 한번 이야기하지만 함수형 프로그래밍은 프로그램에서 수행해야하는 어떠한 행위들을 함수로 표현하고, 또 그 함수들을 이렇게 저렇게 잘 합성하여 거대한 프로그램을 만들어나가는 패러다임이다.
즉, 이러한 함수형 프로그래밍의 정의에서 가장 중요한 키워드는 역시 “함수의 합성”이라고 말할 수 있다. 함수형 프로그래밍에서 그토록 사이드 이펙트를 경계하는 이유도 결국 함수를 안전하게 합성하기 위해서는 함수의 입력과 출력을 예측할 수 있어야하기 때문이다.
함수형 프로그래밍의 세계에서는 프로그램 내부에서 발생하는 모든 행위들을 함수로 표현하고 있기 때문에 변수에 값을 할당하거나 간단한 사칙연산 조차도 함수로 표현된다.
// 명령형 프로그래밍
const foo: number = 1;
foo + 2;
// 함수형 프로그래밍
const foo = ((): number => 1)();
const add2 = (x: number): number => x + 2;
add2(foo);이 프로그램은 number 타입의 변수를 선언하고, 그 값에 2를 더하는 초 간단한 프로그램이다.
명령형 프로그래밍으로 작성된 코드에서는 단순히 foo = 1과 같이 표현할 수 있었던 변수의 할당은 1을 반환하는 함수로, foo + 2로 표현하던 연산은 add2(foo)와 같은 함수로 표현되었다.
우리가 이 코드에서 주목해야할 부분은 바로 가장 마지막 줄의 add2(foo)이다.
add2(foo)라는 것은 foo 변수에 할당되었던 익명 함수의 출력 값인 1을 add2 함수의 입력 값으로 사용하겠다는 의미이며, 이러한 행위가 바로 함수의 합성이다.
// 조금 더 간단하게 표현한 모습은 이렇다
const add2 = x => x + 2;
add2( (() => 1)() );변수에 값을 할당하고 더하는 간단한 연산 조차도 함수로 표현해야하는 함수형 프로그래밍의 세계에서 거대한 프로그램을 견고하게 만든다는 것은 여러가지 복잡한 함수들을 어떻게 잘 합성해서 사용할 수 있는지에 따라 좌지우지될 수 있다는 뜻이다.
이렇게 보면 굉장히 간단한 개념이지만, 사실 아무 함수끼리나 막 합성할 수 있는 것은 아니다. 함수의 합성에는 아주 중요한 규칙이 한 가지 정해져있는데, 바로 합성하려하는 함수들의 “정의역과 치역이 서로 일치해야한다는 것”이다.
정의역과 치역이 일치해야 함수를 합성할 수 있다
이전에 작성했던 수학에서 기원한 프로그래밍 패러다임, 순수 함수 포스팅에서 한 차례 이야기한 적이 있지만, 함수형 프로그래밍에서는 함수의 사이드 이펙트를 최대한 없애버리기 위해 순수 함수를 사용한다.
대표적인 순수 함수의 특징은 대략 이 두 가지이다.
- 함수 외부의 상태를 변경하거나 참조하지 않는다!
- 동일한 입력을 넣었으면 항상 동일한 출력을 반환해야 한다!
이런 순수 함수를 사용하면 개발자가 함수의 행동을 예측하기 쉬워지기 때문에 디버깅이 편리하다는 장점도 있지만, 사실 애초에 저 규칙들이 지켜지지 않는다면 함수를 합성할 수 없기 때문에 모든 행위를 함수로 표현하고 조합해서 프로그래밍을 만드는 짓을 할 수 조차 없다.
왜 저 규칙들을 준수해야 함수의 합성이 가능하다는 것일까? 일단 순수 함수는 수학의 함수를 프로그래밍으로 구현한 개념이니, 한번 수학의 함수가 어떤 느낌으로 작동하는 녀석인지부터 살펴보도록 하자.
일단 수학의 함수는 함수의 입력으로 사용할 수 있는 값들의 집합인 정의역과, 함수의 출력으로 사용할 수 있는 값들의 집합인 치역을 가지고 있다.
그리고 정의역에 있는 원소 하나와 치역에 있는 원소 하나는 무조건 “1:1”로 매핑되어야한다. 즉, 동일한 입력을 함수에 넣었으면 항상 동일한 출력을 반환해야 한다는 말이다. 만약 이 규칙이 깨져버리면 그건 더 이상 함수라고 부를 수 없는 변태같은 무언가가 되어버린다.
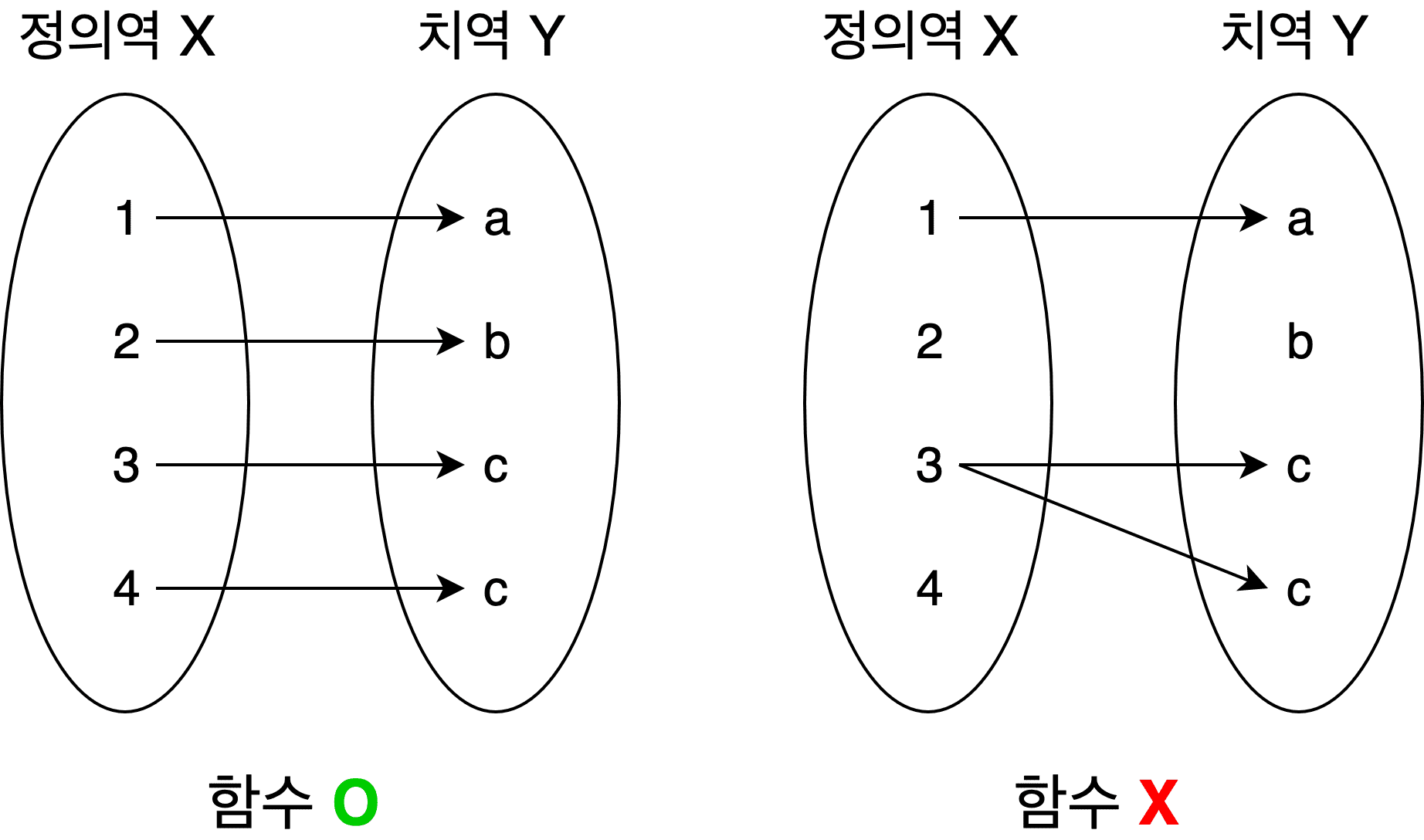
쉽게 말해 함수의 입력으로 사용할 수 있도록 정해져 있는 값들 중에 하나를 뽑아서 함수에 던지면, 반드시 출력으로 사용할 수 있도록 정해져 있는 값들 중에 하나가 튀어나온다는 것이다.
그렇다면 이 개념을 그대로 프로그래밍으로 구현한 순수 함수에게도 정의역과 치역이라고 부를 수 있을만한 무언가가 있다는 말인데, 프로그래밍의 세계에서 살고 있는 순수 함수의 정의역과 치역은 무엇이 될 수 있을까?
.
.
바로 **타입(Type)**이다.
사실 프로그래밍에서 사용하는 타입이라는 녀석도 잘 생각해보면 일종의 집합이라고 볼 수 있다. number라는 집합은 {-1, 0, 0,1, 1, 2, NaN, Infinity...}과 같이 모든 숫자 값을 원소로 가지고 있는 집합이고, boolean이라는 집합은 {true, false}를 원소로 가지는 집합, string이라는 집합은 프로그래밍으로 만들어 낼 수 있는 모든 문자열들을 가지고 있는 집합이라는 이야기이다.
위에서 예시로 들었던 add2 함수를 다시 한번 가져와서 살펴보면, 이 함수는 number 타입을 가진 값을 받아서 다시 number 타입의 값을 반환하고 있다는 것을 알 수 있다.
const add2 = (x: number): number => x + 2;이때 add2 함수는 number 집합을 정의역과 치역으로 가지고 있다고 볼 수 있는 것이다. 여기에 더 나아가서 다른 형태의 함수들의 정의역과 치역도 모두 동일한 규칙으로 정의해볼 수 있다.
type f = (): number => string; // 정의역: number, 치역: string
type g = (): Array<string> => boolean; // 정의역: Array<string>, 치역: boolean
type h = (): string => boolean; // 정의역: string, 치역: boolean이제 슬슬 수학의 함수와 프로그래밍의 순수 함수 간의 공통점이 조금 더 보이기 시작한다.
그럼 이제 원래 본론이었던 함수의 합성에 대해 한번 이야기해보자. 사실 수학의 세계에서 함수를 합성하는 상황은 굉장히 흔한 일이며, 심지어 함수의 합성을 나타내는 전용 기호도 준비되어있다.
함수와 함수를 합성한 합성함수 는 이런 간단한 수식으로 나타낼 수 있다.
갑자기 수식이 나와서 머리가 아프다면 그냥 함수는 밥먹기, 함수는 그릇 치우기, 합성함수 는 밥먹고 그릇 치우기 정도로 이해해도 아무 문제가 없다. 원래 함수란 그렇게 추상적인 느낌이다.
이 식에서 함수의 실행 순서는 오른쪽에서 왼쪽이다. 즉, 합성된 함수인 함수를 와 같이 사용한다는 것은 사실 와 같이 함수를 합성해서 사용하는 것과 동일하다는 것이다.
하지만 이런 식으로 함수를 겹쳐가면서 합성을 표현한다면 많은 함수를 합성하는 공식을 보았을 때 괄호만 보일 게 뻔하므로 저 동그란 연산자를 사용하여 합성된 함수들을 펼쳐서 읽을 수 있도록 해주는 것이다. (콜백과 async/await의 차이를 생각해보자)
// 함수 합성 연산자가 없다면 대충 이런 느낌이 되어 버리지 않을까...?
foo(b(a(h(f(g(x))))));이때 함수를 합성하기 위해서는 첫 번째 함수인 의 치역과 그 다음 함수인 의 정의역이 동일해야 한다는 중요한 원칙이 있다.
방금 위에서 순수 함수의 정의역과 치역은 타입이라고 했으니, 첫 번째 함수의 출력 값의 타입과 그 다음 함수의 입력 값의 타입이 동일해야한다고 말할 수도 있을 것 같다.
// 합성이 가능하다!
f: number => number
g: number => number
// 이건 합성이 불가능...
f: number => string
g: number => number정의역과 치역 어쩌고하면 조금 복잡해보일지 몰라도 타입으로 바꿔보니 굉장히 당연하기 짝이 없는 이야기가 되어버렸다. 그렇다면 순수 함수를 사용하면서 이 규칙만 잘 적용해주면 아무 문제가 없을까?
음, 대부분의 경우에는 가능하겠지만 슬프게도 모든 케이스를 커버할 수는 없다. 프로그래밍의 세계에는 에러라던가 불확실성과 같이 수학의 세계에는 없는 케이스들이 존재하기 때문이다.
수학의 함수를 프로그래밍적으로 구현한 순수 함수라 할 지라도 프로그래밍의 세계에 존재하는 이상 이런 케이스들을 모두 피해갈 수는 없다.
결국 아무리 순수 함수를 사용한다고 해도 이런 문제점들이 여전히 존재하기 때문에 전세계의 똑똑이들이 “도대체 어떻게 하면 안전하게 함수를 합성할 수 있을까?”라는 고민을 하게 된 것이고, 그 고민을 통해 도입된 것이 바로 펑터나 모나드와 같은 수학의 개념들인 것이다.
순수 함수에도 사이드 이펙트는 존재한다
사이드 이펙트(Side-Effect)라는 단어는 한국어로 직역하면 “부수 효과”이다.
즉, 함수에게 기대하고있는 행위 외에 발생하는 모든 부수 효과들을 우리는 사이트 이펙트라고 하는 것이다. 함수가 외부 상태에 영향을 받는 것은 대표적인 사이드 이펙트 중 하나에 불과하다.
사실 순수 함수를 수학의 함수와 비교해보면 “같은 값을 입력받으면 늘 같은 출력을 반환한다”라는 규칙이 보장되는 것 외에는 허술하기 짝이 없는 함수이다. 예를 들어 문자열을 입력받은 후 그 문자열의 가장 첫번째 글자를 반환하는 함수가 있다고 생각해보자.
function getFirstLetter (s: string): string {
return s[0];
}일단 이 함수도 순수 함수는 맞다. 함수의 출력 값은 인자에만 영향을 받고 있고, 늘 같은 입력 값에는 같은 출력을 반환하고, 외부 상태에 전혀 영향도 받고 있지 않기 때문이다.
getFirstLetter 함수는 주어진 문자열의 첫 글자를 반환하는 순수 함수이지만, 만약 빈 문자열이 인자로 주어질 경우 string형이 아닌 undefined를 반환할 것이다.
우리가 과연 이 함수를 사용할 때 “반드시 string 타입이 반환될꺼야”라고 장담할 수 있을까?
만약 이렇게 getFirstLetter 함수가 반드시 string 타입을 반환할 것이라고 장담하고 함수를 합성했다면 아마 이런 타입 에러를 만날 수 있을 것이다.
function getStringLength (s: string): number {
return s.length;
}
getStringLength(getFirstLetter(''));Uncaught TypeError: Cannot read property 'length' of undefined사실 이 에러 조차 사이드 이펙트라고 할 수 있다. 어찌되었든 우리의 순수 함수에게 기대했던 효과가 아니라 부수적으로 발생하고 있는 효과이기 때문이다.
이렇게 여러 개의 함수가 합성되어 있는 상황에서 단 하나의 함수라도 에러가 발생하면 합성 함수로 구성된 연산 전체가 망해버리기 때문에 우리는 이 사이드 이펙트를 반드시 관리해줘야 한다.
사실 getFirstLetter 함수의 치역은 string이 아니라, string 집합과 undefined 집합이 합쳐져 있는 string|undefined 집합이다. 그러니 우리는 이 두 함수의 정의역과 치역을 다시 설정해주고 예외 처리를 추가함으로써 이 문제를 해결할 수 있다.
function getFirstLetter (s: string): string|undefined {
return s[0];
}
function getStringLength (s: string|undefined): number {
if (!s) {
return -1;
}
return s.length;
}하지만 이렇게 어떤 함수가 여러 개의 집합이 합쳐진 치역을 가지기 시작하면 이 함수와 합성하기 위한 모든 함수의 정의역도 여러 개의 집합이 합쳐진 치역을 가져야하기 때문에, 결국 type|undefined처럼 암 걸리는 타입이 모든 함수에 적용되어야 할 것이다.
게다가 이런 상황이 발생할 때마다 함수 내부에서 매번 조건 검사를 통해 값의 유무를 검사하는 것은 너무나도 귀찮은 일이고, 여기저기서 동일한 코드가 계속 발생하기 때문에 이 방법이 근본적인 해결책은 아닌 것 같다.
이렇게 함수에서 어떤 타입이 반환될지 장담할 수 없다는 불확실성 또한 결국 정의역과 치역을 일치시켜야하는 함수의 합성 과정에서 명확한 타입의 사용을 저해하는 요소가 되기 때문에 반드시 믿고 걸러야하는 사이드 이펙트라고 할 수 있다.
그럼 사이드 이펙트를 어떻게 관리해야할까?
이런 상황이 발생하는 이유는 그냥 “컴퓨터는 수학이 아니니까”라고 말할 수 밖에 없다. 어쨌든 프로그램에서 돌아가는 모든 함수는 저런 문제들을 가지고 있다. 심지어 순수 함수라고 할지라도 말이다.
즉, 근본적으로 이 문제는 함수들 간의 합성 과정에서 어쩔 수 없이 발생하는 사이드 이펙트를 어떻게 하면 잘 관리해가면서 합성할 수 있을지에 대한 고민이다.
함수를 합성할 때 중간에 껴있는 함수에서 에러가 발생하더라도 합성된 함수의 연산을 안전하게 끝낼 수 있을 지, 불확실한 함수의 출력을 어떻게 하면 명확하게 만들어서 다음 함수로 전달할 수 있을 지 말이다.
그렇다면 함수를 다른 함수로 한번 감싸서 안전하게 예외처리를 진행하거나, 혹은 중간에 이상한 값이 나오면 그대로 다음 함수를 지나치게 만들면 되지 않을까?
type StringFunction = (s: string) => number;
function safety (x: string|undefined, fn: StringFunction) {
return x ? fn(x) : x;
}
safety(getFirstLetter('Hi'), getStringLength);
safety(getFirstLetter(''), getStringLength);1
undefined하지만 이런 방식은 수많은 타입의 입출력을 가진 함수들에게 모두 적용하기에는 약간 무리가 있어보이니 제네릭 타입을 사용하여 조금 더 유연하게 만들어 보자.
function safety <T, U>(x: T|undefined, fn: (x: T) => U) {
return x ? fn(x) : x;
}
safety<string, number>(getFirstLetter('Hi'), getStringLength);
safety<string, number>(getFirstLetter(''), getStringLength);1
undefined오호 조금 그럴싸해졌다. 결국 safety 함수는 T또는 undefined의 값을 인자로 받은 후 이 인자가 undefined이라면 그대로 undefined을 반환하고, 만약 아니라면 T 타입을 인자로 받아서 U 타입을 반환하는 함수에게 인자를 넘겨주고 그 함수의 실행 결과를 반환한다.
값이 있다: T -> fn<U>
값이 없다: T -> undefined결국 우리는 getFirstLetter 함수의 치역과 getStringLength 함수의 정의역을 바로 연결해버리는 것이 아닌, x ? fn(x) : x라는 로직을 통해 함수의 사이드 이펙트를 한번 감싸준 다음 함수를 안전하게 합성한 것이다.
그렇다면 이 개념을 조금 더 확장해서 함수가 출력한 값을 사용할 때 일종의 안전장치 역할을 하는 함수가 늘 값을 감싸고 있다면 어떨까? 이런 느낌으로 함수의 정상적인 결과와 사이드 이펙트를 감싸줄 수 있는 무언가를 만들 수 있으면 이 문제를 해결할 수 있지 않을까?
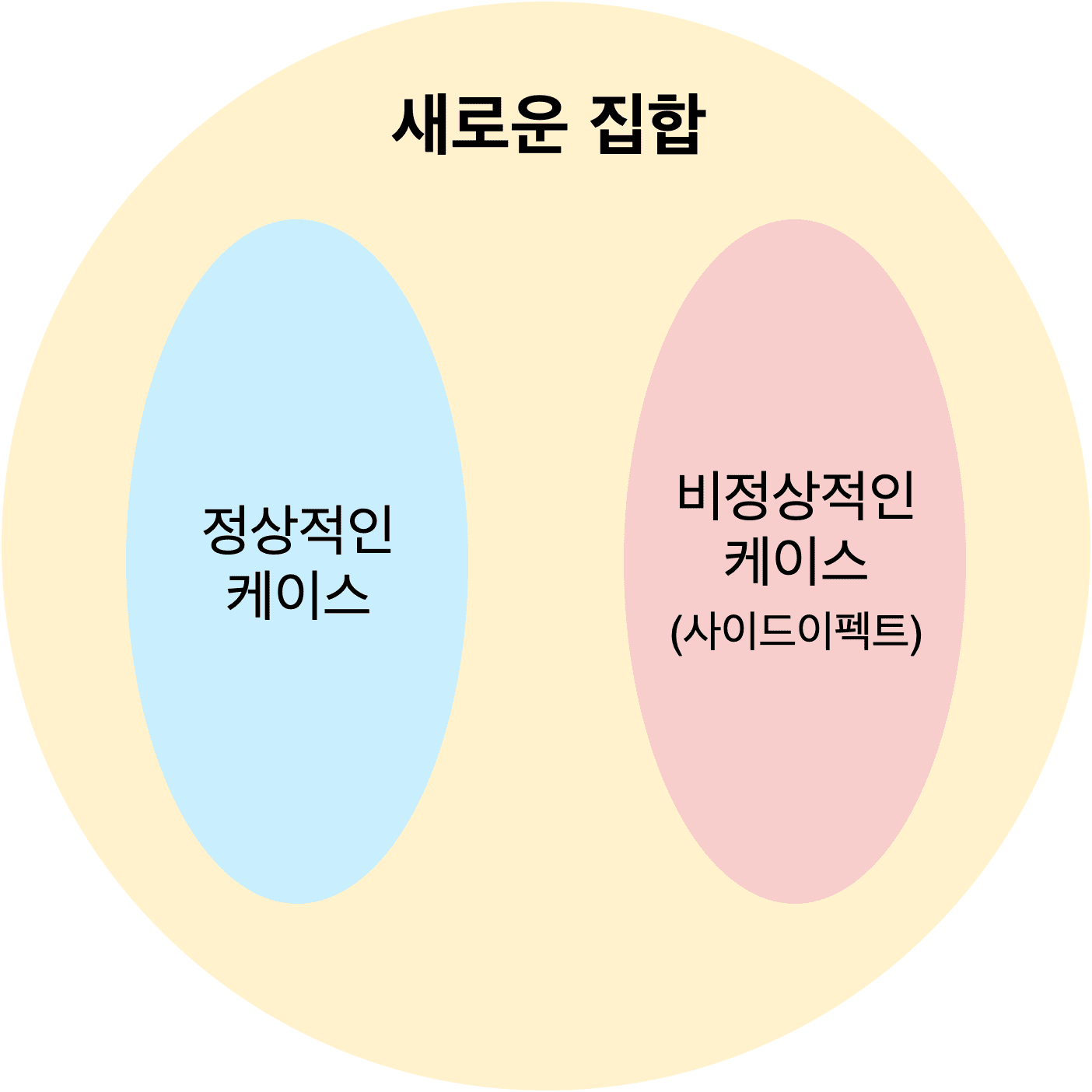
만약 저 추상적인 무언가가 함수의 사이드 이펙트를 관리해주면서 다른 함수와의 합성을 진행할수만 있다면, 함수를 합성하는 과정에서 일일히 저런 예외 처리를 해주지 않아도 되고, 함수들의 입출력에 대한 타입 안정성도 가져가며 마음 놓고 합성을 쭉쭉 해나갈수 있을 것 같다.
// 이런 느낌으로 말이다!
f: Something<number> -> Something<number>
g: Something<number> -> Something<number>함수는 제대로 된 치역에 해당하는 값을 반환할 수도 있고 사이드 이펙트를 일으킬 수 있는 null이나 undefined 같은 값을 반환할 수도 있지만, 뭐가 되었든 저 Something이라는 녀석이 알아서 예외를 핸들링할 수 있도록 만들기만 한다면 우리는 그런 자잘한 건 신경쓰지 않고 함수를 쭉쭉 합성할 수 있기 때문이다.
그리고 이런 느낌이라면 null이나 undefined를 관리하는 것 외에도, 다양한 로직을 값에다가 감싸서 사용하면 되니까 나름 확장성도 좋은 개념인 것 같다. 뭐 대충 이런 느낌으로 말이다.
Maybe<T> = 값이 있을 수도 있고 없을 수도 있다
Promise<T> = 지금은 값이 없는데 나중에 값이 생기면 값을 준다
List<T> = 같은 속성의 값을 여러 개 가지고 있을 수도 있다그리고 이렇게 값을 감싸고 있는 무언가를 효율적으로 사용하려면 내부에 있는 값을 자유롭게 변경할 수 있어야 하므로 Maybe<T> -> Maybe<U>와 같은 동작을 수행할 수 있는 무언가도 필요할 것 같다.
이런 고민 끝에 개발자들은 이런 비슷한 역할을 수행하는 수학의 한 개념을 차용하게 되는데, 그 개념이 바로 펑터(Functor)이다.
펑터란 무엇일까?
펑터는 보통 값을 품고 있는 어떠한 박스의 형태로 설명되고는 한다. 방금 위에서 설명한 것과 같이 함수의 정상적인 결과와 사이드 이펙트를 감싸서 처리할 수 있는 무언가를 설명하기에는 박스가 적절한 예시이기 때문이다.
 [출처] http://adit.io/posts/2013-04-17-functors,_applicatives,_and_monads_in_pictures.html
[출처] http://adit.io/posts/2013-04-17-functors,_applicatives,_and_monads_in_pictures.html
저 박스는 결국 안전하게 값을 사용할 수 있도록 도와주는 로직을 가지고 있거나, 혹은 여러 개의 값을 처리할 수 있는 로직을 가지고 있거나, 아직은 값이 결정되지 않았지만 나중에 값이 결정되고 나면 값을 사용할 수 있는 로직을 가지고 있는 등, 값을 사용할 때 도움을 주는 여러가지 로직을 담고 있는 마법의 박스라고 할 수 있다.
이때 이 박스는 역할이 고정된 것이 아니라 Maybe, Promise 등 다양한 기능을 가질 수도 있기 때문에 문맥(Context)이라는 이름으로 불리기도 한다.
우리가 방금 만들었던 safety 함수도 값을 감싸고 있는 일종의 박스라고 생각해볼 수 있다.
function safety <T, U>(x: T|undefined, fn: (x: T) => U) {
return x ? fn(x) : x;
}
즉, x라는 값을 바로 사용하는 것이 아니라 safety 함수에 x라는 값을 넣어서 사용하고 있으므로 safety 함수를 일종의 박스라고 생각하자는 것이 저 설명의 취지이다.
사실 펑터의 개념적인 내용은 이게 전부라고 할 수 있고, 이후 펑터를 구현하는 방법만 익혀도 펑터를 사용함에 있어서는 아무런 지장이 없다. 그러나 이번 포스팅의 목적은 펑터가 무엇인지 조금 더 깊숙하게 조져보는 것이므로 필자는 조금 더 근본적인 펑터의 개념에 대해서 이야기해볼까한다.
카테고리(Category)
펑터(Functor)는 수학의 카테고리 이론(Category Theory)에 등장하는 개념이며, 동일한 구조를 가지고 있는 카테고리들의 관계를 정의할 수 있는 구조체라고 정의된다.
그렇기 때문에 펑터가 본질적으로 무엇인지, 왜 Something<type>이라는 것을 통해 함수를 안전하게 합성하기위해 펑터가 필요하다는 것인지 알기 위해서는 카테고리라는 개념에 대해 알고 있어야 한다.
사실 수학에서 이야기하는 카테고리라는 개념은 우리가 일상 생활 속에서 사용하는 카테고리의 의미와 크게 다르지 않다. 뭐 비슷한 것들을 묶어놓은 그런 개념이랄까…?
이렇게 마음을 가볍게 먹은 후 카테고리 이론을 위키피디아에 검색해보면 아래와 같은 검색 결과를 만날 수 있게 된다.
범주 는 다음과 같은 데이터로 구성된다.
- 대상(對象, 영어: object)들의 모임 . 이 모임의 원소를 의 “대상”이라고 한다.
- 임의의 두 대상 에 대하여, 를 정의역으로, 를 공역으로 하는 사상(寫像, 영어: morphism)들의 모임 로 쓰고, 를 에서 로 가는 사상’이라고 한다. 의 사상의 모임을 로 나타낸다.
- 임의의 세 대상 에 대하여, 이항 연산 . 이를 사상의 합성(合成, 영어: composition)이라고 한다. 와 의 합성은 또는 등으로 나타낸다.
…
위키피디아 범주(수학)
 읭...?
읭...?
사실 카테고리 이론의 개괄적인 내용은 누구나 다 간단하게 이해할 수 있는 수준의 내용이다. 단지 추상적인 학문인 수학의 특성 상 일상적인 언어로 풀어서 설명하면 너무 길어지고 복잡해지니 간단하게 축약할 수 있는 단어와 기호들로 표현한 것 뿐이다. (사실 이게 수포자가 생기는 원인 중 하나)
일단 위에서 이야기 했듯이 수학에서 이야기하는 카테고리는 쇼핑몰 사이트에 있는 그 카테고리가 맞다. 다만 수학의 카테고리는 조금 더 추상적인 개념이기 때문에 물건으로 구성되는 카테고리일수도 있고 자연수로 구성된 카테고리일수도 있으며, 때로는 함수로 구성된 카테고리가 될 수도 있다는 차이점이 있다.
위의 수학적 정의에서 카테고리는 “대상(Object)“과 “사상(Morphism)“이라는 것으로 구성된다고 이야기하고 있다.
대상이라는 것은 그냥 카테고리 안에 있는 하나의 객체이다. 만약 패션 쇼핑몰의 상품 카테고리라면 대상은 셔츠, 맨투맨, 아우터, 코트가 될 것이고, 자연수로 이루어진 카테고리라면 1, 2, 3과 같은 수가 될 것이다. 여기까지는 우리가 일상적으로 사용하는 카테고리라는 단어와 비슷한 느낌이기 때문에 이해가 그리 어렵지 않다.
그러나 수학에서의 카테고리는 대상 외에도 사상이라는 한 가지 데이터를 더 가지고 있다.
위의 수학적 정의를 다시 보면 사상은 임의의 두 대상 에 대하여, 를 정의역으로, 를 공역으로 하는 무언가라고 한다. 사실 라는 말은 와 라는 대상이 카테고리 안에 있다는 것을 의미하는 것이니 그냥 넘어가도록 하고, 우리가 집중해야할 단어는 “정의역”과 “공역”이다.
정의역과 공역이라는 단어를 듣고 가장 먼저 생각나는 단어가 무엇일까? 바로 “함수”이다. 를 정의역으로, 를 공역으로 한다는 이야기는, 라는 대상에 어떤 사상(함수)를 적용하면 가 된다는 것을 이야기하고 있는 것이다.
const 대상A = 1;
const 사상add1 = x => x + 1;
// 대상 A에게 add1이라는 사상을 적용하면...
사상add1(대상A);2 // 대상 B가 된다즉, 사상이라는 것은 대상과 대상 간의 관계를 나타낼 수 있는 일종의 함수라고 생각하면 된다. 그래서 수학적 표현으로는 라고 표현할 수 있는 것이고 프로그래밍적으로는 그냥 람다 함수로 (a) => b이라고 표현할 수 있는 것이다. (대상의 종류에 따라 사상이 함수가 아닌 경우도 있지만, 거기까진 생각하지 말자)
여기까지 이해했다면 보다 쉬운 설명을 위해 간단한 카테고리를 하나 가져와서 가지고 놀아보도록 하겠다.
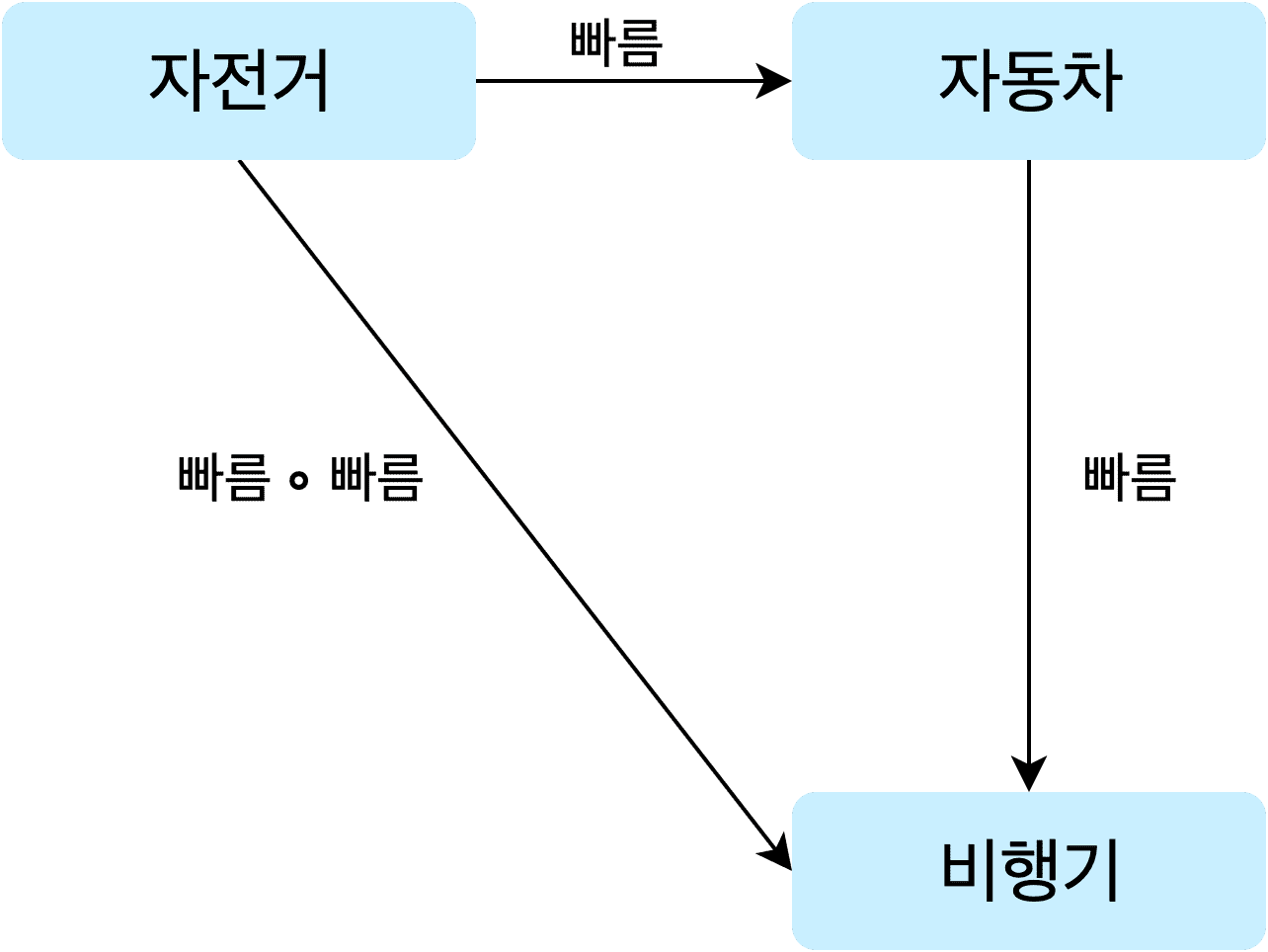
대충 이런 구조를 가진 카테고리 가 있다고 생각해보자. 이 카테고리에서 대상은 자전거, 자동차, 비행기이고 사상은 객체들 사이에 있는 빠름이라는 화살표이다.
즉, 이 카테고리에서 자전거에 빠름이라는 사상을 적용하면 자동차가 되고, 자동차에 다시 빠름라는 사상을 적용하면 비행기가 된다는 뜻이다. 사상으로 객체들 간의 관계를 표현할 수 있다는 말은 이런 의미이다. 자전거가 빨라지면 자동차가 되고, 자동차가 빨라지면 비행기가 되는 것이니 말이다.
그리고 사상을 적용한다는 것은 함수를 적용한다는 말과 같으므로 간단한 코드로 이 카테고리의 구조를 표현해볼 수도 있겠다.
const 카테고리 = ['자전거', '자동차', '비행기'];
function 빠름 (카테고리, 대상) {
const index = 카테고리.findIndex(v => v === 대상);
return 카테고리[index + 1];
}
빠름(카테고리, '자전거');
빠름(카테고리, '자동차');'자동차'
'비행기'그리고 자전거에서 비행기로 바로 그어진 빠름 빠름 사상은 빠름 사상 두 개를 합성한 것을 의미하니까, 코드로는 함수 두 개를 합성한 형태인 빠름(빠름(자전거)) === '비행기'로 표현할 수 있다.
결국 사상의 합성이라는 것을 프로그래밍으로 표현하면 그냥 함수를 합성하는 것 그 이상도 이하도 아니다. 이 간단한 걸 수학적인 정의로 이야기하면 이렇게 복잡해보이는 이야기가 되는 것이다.
임의의 세 대상 에 대하여, 이항 연산 . 이를 사상의 합성(合成, 영어: composition)이라고 한다. 와 의 합성은 또는 등으로 나타낸다.
이 정의에서 이야기하는 임의의 세 대상은 각각 위 카테고리의 자전거, 자동차, 비행기라고 생각하면 된다. 그리고 라는 말에서 나오는 이라는 녀석은 여러 개의 사상을 가지고 있는, 사상의 집합을 의미한다.
이 정의에서 사상이 하나가 아닌 여러 개라고 이야기하는 이유는 간단하다. 위의 카테고리만 보더라도 자전거와 자동차 간의 관계가 단지 빠름이라는 것만 있지는 않을 것이니 말이다.
- 자전거 -빠름-> 자동차
- 자전거 -비쌈-> 자동차
- 자전거 -크기가 큼-> 자동차
- 자전거 -엔진이 달림-> 자동차
뭐 이런 식으로 어떤 대상과 대상 사이에는 여러 개의 사상이 존재할 수 있기 때문에, 이 사상들의 집합을 퉁쳐서 라고 표현한 것이다.
뭐 이딴 것까지 하나하나 다 신경쓰고 있냐고 할 수도 있지만, 수학은 분명히 정답이 존재해야하고, 절대 예외를 허용하지 않는 논리적인 학문이기 때문에 이렇게 모든 케이스를 전부 고려한 정의를 만들어줘야한다.
그리고 라는 표현은 에 있는 여러 개의 사상 중에서, 대상과 대상에 단 하나의 사상만 적용한 경우를 말한다. 저 사상들 중 무슨 사상을 적용할지는 모르겠는데, 어쨌든 적용할 때는 한번에 하나만 적용해야하기 때문이다. (여러 개를 동시에 적용할거야!는 양자 컴퓨터가 아니면 불가능하다)
그리고 마지막으로 우리가 자전거에다 빠름 사상을 두 번 적용한 것과 같이 사상을 합성한 것을 사상과 사상이 합성된 , 사상의 합성이라고 표현하는 것이다.
즉, 자전거라는 대상에 사상 를 적용하고, 다시 사상 를 적용하면 비행기라는 대상이 된다는 것을 이야기 하는 것이며, 이것도 그냥 코드로 표현하면 그냥 g(f(자전거)) === '비행기'라고 할 수 있겠다.
이렇듯이 카테고리 이론은 굉장히 추상적인 이론이라 프로그램 안에서 벌어지는 일을 전부 저런 카테고리 모델로 표현해낼 수 있으며, 마찬가지로 우리가 함수형 프로그래밍을 하면서 어떤 값에 함수를 적용하고 합성하는 과정 또한 일종의 카테고리 모형으로 표현할 수 있는 것이다.
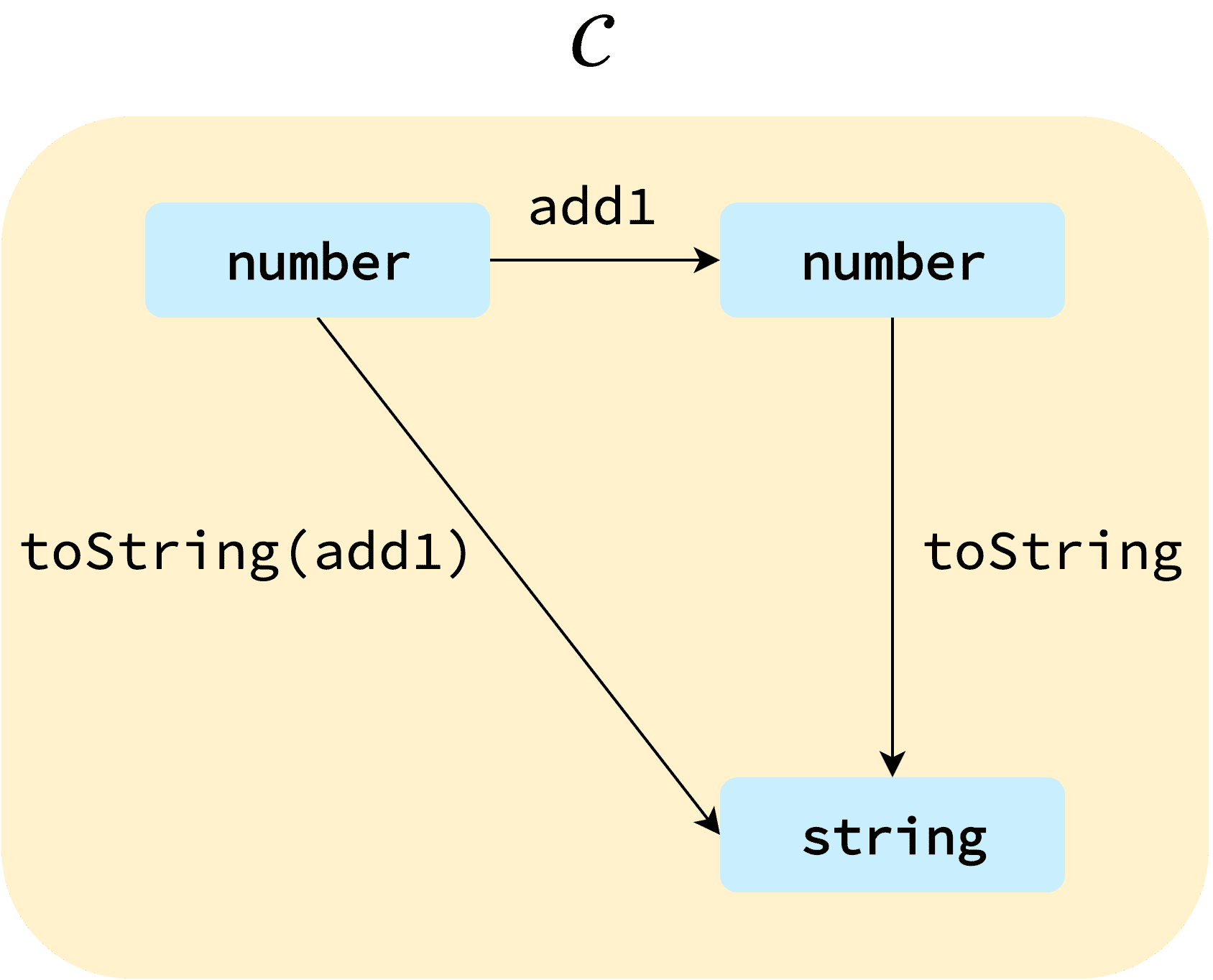
필자는 개인적으로 여기까지가 펑터를 조금 더 쉽게 이해하기위한 카테고리 이론의 전부라고 생각한다. 프로그램에서 발생하는 일들을 일종의 카테고리로 정의할 수 있다는 사실까지 받아들이고 나면 펑터를 이해하는 것이 간단해지기 때문이다.
펑터(Functor)
자, 이제 방금 만들었던 간단한 카테고리를 이제 조금 추상적인 모델로 바꿔보도록 하자. 비행기, 자동차, 자전거와 같은 이름은 변수 x, y, z로 변경하고 사상 빠름 역시 변수인 f와 g로 변경하겠다.
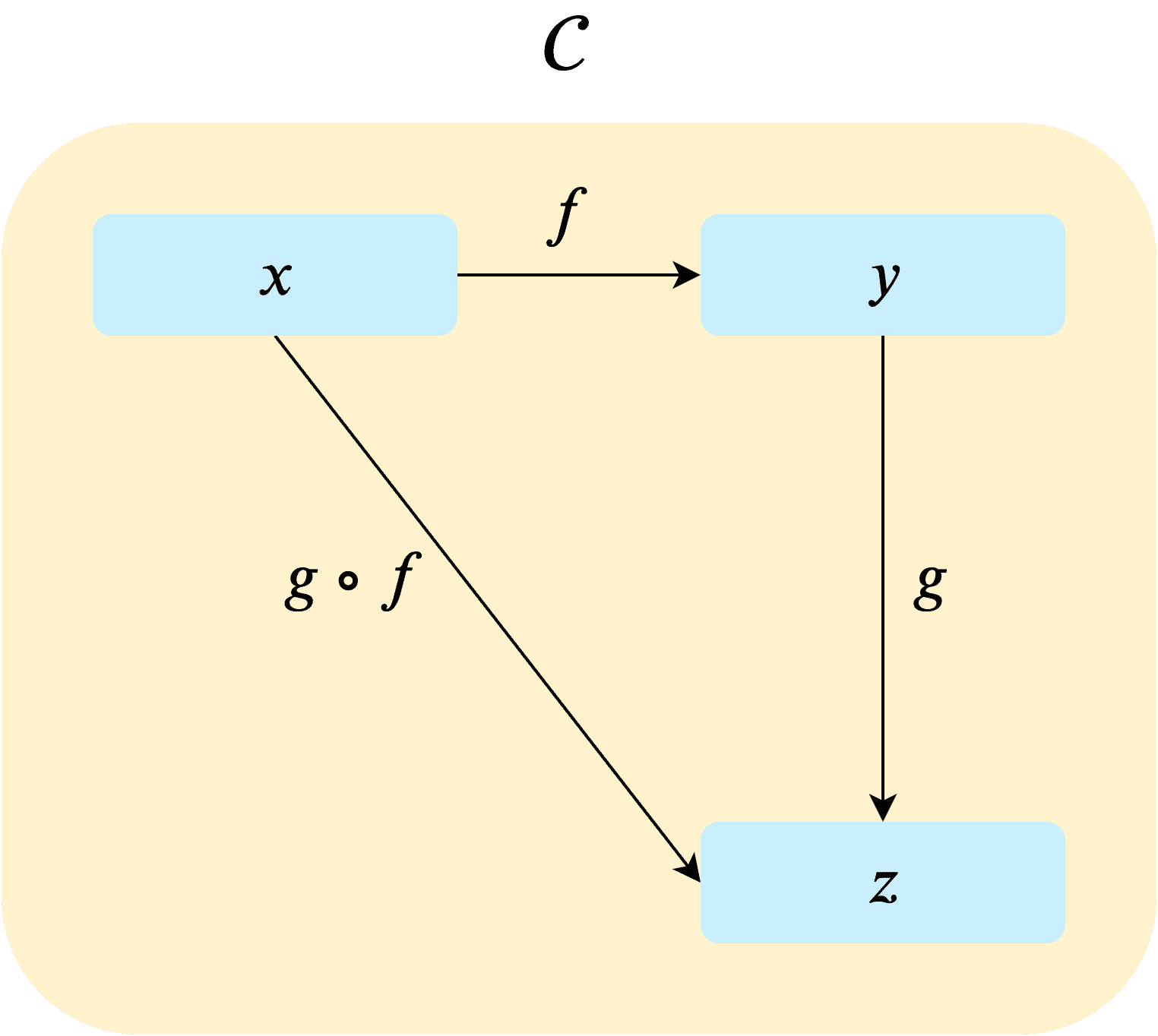
아까 우리가 만든 카테고리를 이렇게 추상적인 구조로 변경하고나니, 이런 구조를 가진 카테고리는 왠지 카테고리 말고도 더 있을 것 같다는 생각이 든다.
그도 그럴것이 저런 구조의 대상과 사상을 가지는 카테고리는 굉장히 흔하고, 솔직히 어디다가 가져다 붙혀도 왠만한 정의에는 껴맞출 수 있는 보편적인 카테고리이기 때문이다.
그렇다면 대상에 사상을 적용하여 다른 대상으로 만들 수 있듯이, 카테고리에도 사상을 적용하여 다른 카테고리로 만들 수 있지 않을까?
이때 등장하는 것이 바로 “펑터(Functor)“이다. 즉, 펑터는 카테고리를 다른 카테고리로 변경할 수 있는 사상(함수)인 것이다.
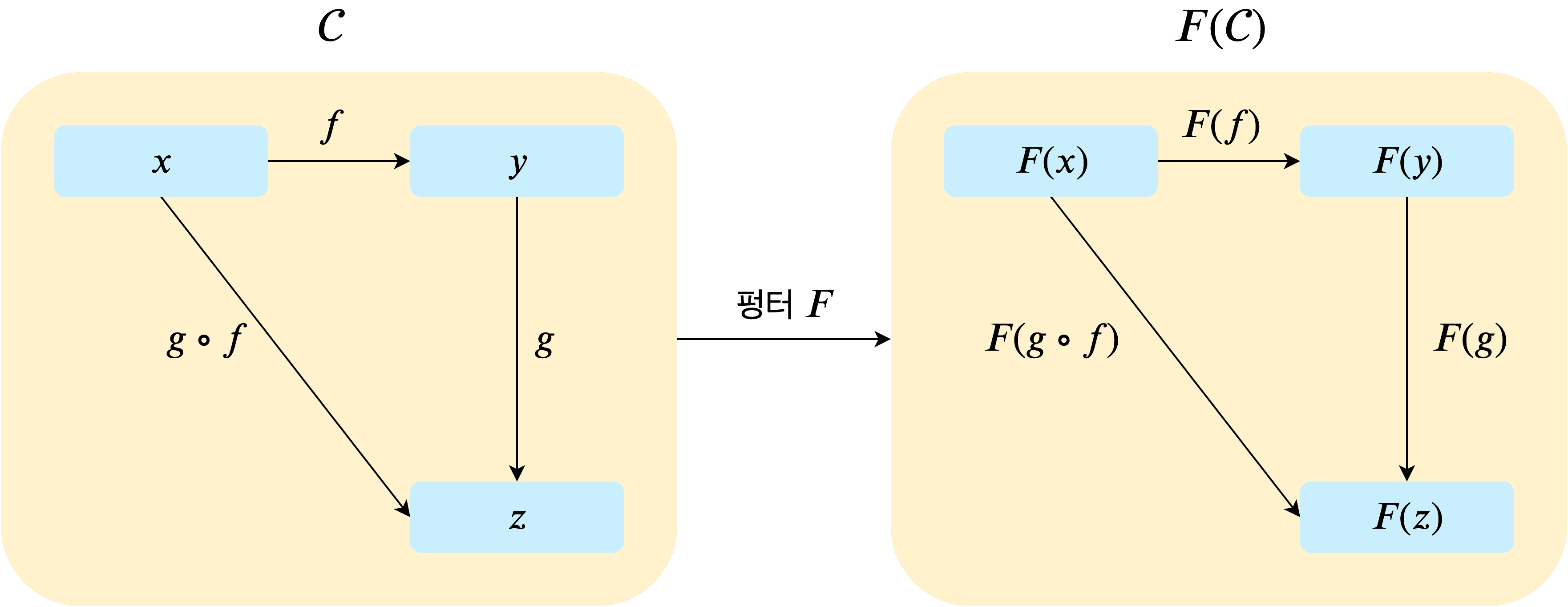
카테고리 가 아무리 복잡하게 구성되어있다고 해도 우리는 와 같이 카테고리에 펑터를 덮어 씌우기만 하면 간단하게 펑터를 사용할 수 있다. 그러면 펑터가 적용된 카테고리 내부에 있는 모든 대상과 사상들 또한 라는 함수로 감싸져 있는 형태로 변경된다.
여기서 가장 중요한 것은 펑터로 감싸도 카테고리 자체의 구조는 절대 변하지 않는다는 점이다. 위 그림에서도 대상과 사상들에게 라는 함수가 적용되었을 뿐 화살표 자체의 모양은 변하지 않은 것을 볼 수 있다.
const 대상x = 1;
const 대상y = 2;
const 사상f = x => x + 1;
사상f(대상x) === 대상y; // trueconst 대상x = 펑터(1);
const 대상y = 펑터(2);
const 사상f = 펑터(x => x + 1);
사상f(대상x) === 대상y; // true즉, 펑터를 사용하더라도 카테고리가 가지고 있는 규칙 자체는 절대 변경되지 않는다. 쉽게 말해 안전하게 대상이나 사상을 감싸기만 할 뿐, 그 외에 아무런 사이드 이펙트를 일으키지 않는다는 것이다.
아까 전에 프로그래밍에서 발생하는 모든 일도 일종의 카테고리로 표현할 수 있다고 했던 것을 기억하는가?
아무리 복잡한 카테고리라고 해도, 단순히 펑터로 감싸기만 하면 기존 카테고리의 구조를 전혀 건드리지 않으면서 다른 카테고리로 변경할 수 있기 때문에 우리가 찾고있던 “값을 감싸서 안전하게 값을 사용하고 싶다”라는 니즈에 부합하는 개념인 것이다.
펑터를 직접 만들어보자!
펑터라는 것은 그렇게 거창한 개념이 아니다. 간단하게 말해서 카테고리를 다른 카테고리로 바꿔주는 행위를 할 수 있으면 펑터인 것이다.
이때 펑터가 카테고리를 변경하는 행위를 “매핑(mapping)“이라고 하며, 조금 더 자세히 말해 카테고리에 함수를 적용하여 다른 카테고리로 변경하는 행위라고 할 수도 있다.
이렇게 추상적인 개념을 가진 펑터이기에, 누구는 펑터를 이래서 쓴다, 누구는 펑터를 저래서 쓴다와 같이 이야기가 전부 다른 것이다. 사실 펑터 자체는 그저 매핑이라는 행위를 할 수 있는 무언가에 불과하기 때문에 펑터를 어떤 방식으로 응용하냐에 따라 그 사용 방법 또한 무궁무진하다.
사실 펑터라는 개념 자체는 특정 메소드를 통해 펑터 내부의 값을 변경할 수 있도록 만들어주기만 하면 되기 때문에 프로그래밍으로 표현하는 것이 그렇게 어렵지는 않다.
interface Functor<T> {
map<U>(f: (x: T) => U): Functor<U>
}
Function<T>: 이 펑터는T타입의 값을 가지고 있다.map<U>: 이 펑터의 사상을 적용하면U타입의 값을 가진 새로운 펑터를 얻는다.f: (x: T) => U: 이 펑터의 사상이 작동하는 방식은T타입의 값을 입력으로 받아U타입의 값을 출력하는 것이다.
map 메소드는 인자로 받은 (x: T) => U 꼴의 함수를 펑터 내부의 값에 적용하고, 변경된 값을 감싸고 있는 새로운 펑터를 반환한다.
결국 map 메소드에 인자로 넘기는 이 함수가 실질적으로 펑터 내부의 값을 변경하는 역할을 하는 것이며, 값을 실질적으로 변경하는 역할을 하는 이 함수를 트랜스폼(Transform) 함수라고 부른다.
매핑을 하고 난 뒤 변경된 값 자체가 아니라 변경된 값을 감싸고 있는 펑터가 반환되는 이유는 펑터라는 것이 본질적으로 어떤 카테고리를 다른 카테고리로 변경하는 구조체일 뿐, 카테고리를 부숴버리고 내부에 있는 대상을 꺼내는 역할을 하는 게 아니기 때문이다.
그리고 펑터는 단지 새로운 카테고리를 표현하는 수단이기 때문에 기존 카테고리의 대상을 변경해서는 안된다. 그렇기 때문에 기존 펑터의 값을 업데이트하는 것이 아니라 변경된 값을 담고 있는 새로운 펑터를 생성해서 반환해야하는 것이다.
이 개념이 약간 혼란스럽게 느껴진다면 Array.prototype.map 메소드를 생각해보자. 잘 생각해보면 배열도 어떠한 박스 안에 값을 담고 있는 일종의 펑터라고 할 수 있다.
// Functor<number>
const array: Array<number> = [1, 2, 3];
// 트랜스폼 함수: (x: number) => string
const toString = v => v.toString();
// 매핑!
array.map(toString);// 새로운 펑터 Functor<string>
['1', '2', '3']우리는 트랜스폼 함수인 toString 함수를 사용하여 배열이라는 펑터 내부의 값을 변경할 수는 있지만, 배열이라는 박스 자체를 없애버리지는 않는다.
일반적으로 우리가 자주 사용하는 map이라는 메소드가 Array에 물려있기 때문에 매핑이라는 행위를 이터레이션과 연결지어 생각하기 쉬운데, 매핑은 그렇게 구체적인 행위가 아니다.
뭐 map 메소드 내부에서 이터레이션을 돌던 북을 치던 브레이크댄스를 추던 최종적으로 Functor<T> -> Functor<U>라는 변환만 수행할 수 있으면 되는 것이다. 이제 펑터가 어떤 느낌으로 돌아가는 개념인지 살짝 감을 잡을 수 있을 것이다.
자, 이제 펑터를 직접 구현해볼 시간이다. 펑터라는 게 워낙 추상적인 개념인 만큼 어떻게 응용하냐에 따라 무궁무진한 펑터를 만들 수 있지만, 이미 포스팅이 꽤나 길어졌기 때문에 많은 펑터를 선보이기는 힘들 것 같다. 그리고 펑터를 사용한 구현체들은 다른 분들이 작성해주신 포스팅에도 많으니 궁금하신 분들은 그 쪽을 참고해보도록 하자.
이 포스팅에서는 가장 간단한 형태의 펑터인 Just 펑터와 Nothing 펑터를 만들어보고, 이 두 펑터를 조합하여 값의 유무로 인한 사이드 이펙트를 관리할 수 있는 Maybe 펑터만 만들어보도록 하겠다.
Just
Just 펑터는 아무런 추가적인 기능없이 값을 그냥 감싸고 있기만 하고 map 메소드를 통해서 그 값을 변경할 수 있는 펑터이다.
class Just<T> implements Functor<T> {
value: T;
constructor (value: T) {
this.value = value;
}
map<U> (f: (x: T) => U) {
return new Just<U>(f(this.value));
}
}Just는 자신 내부에 값을 가지고 있는 단순한 펑터이다. 이 펑터의 map 메소드를 사용한다는 것은 펑터가 가지고 있는 T 타입의 값을 U 타입의 값으로 변경하고, 이 값을 다시 새로운 Just 펑터에 감싸서 반환하는 것을 의미한다.
new Just(3)
.map(v => v + 1000)
.map(v => v.toString)
.map(v => v.length);Just { value: 4 }Nothing
Nothing 펑터는 이름 그대로 내부에 어떠한 값도 가지고 있지 않은 펑터를 의미한다. 그리고 펑터 내부에 값이 없으니 트랜스폼 함수를 적용할 수도 없으므로 이 펑터의 map 메소드는 아무 행동도 하지 않고 그대로 Nothing 펑터를 반환하기만 한다.
class Nothing implements Functor<null> {
map () {
return new Nothing();
}
}
new Nothing().map().map().map();Nothing {}굳이 이렇게 값의 유무를 표현하는 펑터가 필요한 이유는 무엇일까?
한번 펑터를 사용하여 함수를 합성하기 시작하면 그 연산 과정에서 필요한 모든 값들 또한 펑터로 감싸져 있어야하기 때문이다. 만약 펑터로 감싸진 값에 그냥 함수를 적용하려고 하면 당연히 에러가 발생한다.
const foo = new Just(3);
foo + 2;Operator '+' cannot be applied to types 'Just<number>' and 'number'.그렇기 때문에 한번 펑터를 사용하여 함수를 합성하기 시작했다면 합성이 끝날 때까지 계속 펑터를 사용해야한다. 애초에 펑터를 사용하는 이유는 함수를 합성하는 동안 타입 안정성을 유지하고 사이드 이펙트를 관리하기 위해서인데, 이 과정에서 펑터가 아닌 녀석이 하나라도 끼어들게 되면 합성한 연산 전체의 안정성을 보장할 수 없기 때문이다. (미꾸라지 한 마리가 물을 흐린다)
이렇게 들으면 뭔가 불편하다고 느껴질 수도 있지만 아까 위에서 대표적인 펑터라고 이야기했던 Array를 사용하는 경우를 생각해보면 이게 그렇게 특이한 개념이 아니라는 사실을 알 수 있다.
만약 new Array(3)이라는 배열이 있을 때 이 배열이 가지고 있는 값에 2를 더하고 싶다면 어떻게 해야할까? 단, 함수형 프로그래밍의 세계에서는 상태의 변경을 허용하지 않으므로 new Array(3)[0] += 2와 같은 개념으로 접근해서는 안된다는 사실을 잊지말자.
즉, 불변성을 중시하는 함수형 프로그래밍의 세계에서 배열 내부의 값을 변경하고 싶다면, “변경된 값을 가지고 있는 새로운 배열”을 생성할 수 밖에 없다.
그래서 우리는 불변성을 지키며 배열 내부의 값을 변경하기위해 무조건 map이라는 메소드를 사용해야하는 것이다. 이제 펑터의 map 메소드가 왜 값을 변경한 후 새로운 펑터를 생성해서 반환하는지 조금은 이해가 갈 거라고 생각한다.
Maybe
자, 여기까지 이해했다면 조금 더 복잡한 펑터를 만들어보도록 하자. Maybe라는 펑터의 map 메소드는 펑터 내부에 값이 있다면 인자로 받은 함수를 값에 적용하고, 값이 없다면 값이 없음을 의미하는 펑터인 Nothing 펑터를 반환하는 펑터이다.
class Maybe<T> implements Functor<T> {
value: Just<T> | Nothing;
constructor (value?: T) {
if (value) {
this.value = new Just<T>(value);
}
else {
this.value = new Nothing();
}
}
map<U> (f: (x: T|null) => U) {
if (this.value instanceof Just) {
return this.value.map<U>(f);
}
else {
return new Nothing();
}
}
}const getFirstLetter = s => s[0];
const getStringLength = s => s.length;
const foo = new Maybe('hi')
.map(getFirstLetter)
.map(getStringLength);
const bar = new Maybe('')
.map(getFirstLetter)
.map(getStringLength);
console.log(foo); // Just { value: 1 }
console.log(bar); // Nothing {}Maybe 펑터를 사용하면 우리는 중간에 null이나 undefined가 반환되어 함수의 합성이 깨져버리는 걱정 없이 안심하고 함수를 합성할 수 있다.
물론 최종적으로 연산 결과가 Just인지 Nothing인지 구분하려면 if 문을 통해서 조건 검사를 해야하기는 하지만, 적어도 함수를 합성하는 중간중간마다 검사하지는 않는다. 즉, 함수를 합성할 때는 합성에만 집중할 수 있다는 뜻이다.
// 펑터가 없다면 함수를 함부로 합성할 수 없다
const firstLetter = getFirstLetter('');
if (firstLetter) {
console.log(getStringLength(firstLetter));
}
else {
console.log('함수 합성 실패');
}// Maybe 펑터를 사용하면 마음놓고 합성이 가능하다
const result =
new Maybe('')
.map(getFirstLetter)
.map(getStringLength);
if (result instanceof Just) {
console.log(result);
}
else {
console.log('함수 합성 실패');
}이렇게 단순히 값을 감싸고, 내부에 있는 값을 변경할 수 있다는 단순한 개념만으로 우리는 함수의 안전한 합성을 할 수 있게 되었다.
이 포스팅에서는 값의 유무로 인한 사이드 이펙트를 관리할 수 있는 Maybe 펑터 만을 예시로 들었지만, 여러 번 이야기 했듯이 펑터는 그냥 값을 감싸고 있는 박스이기 때문에 어떤 로직을 구현하냐에 따라 천차만별로 다른 펑터를 만들어낼 수 있다.
예를 들면 현재에는 아직 값이 없지만 미래에 값이 결정되는 것을 약속해주는 Promise 같은 개념도 일종의 펑터라고 볼 수 있고, 여러 개의 값을 순차적으로 저장할 수 있는 Array도 일종의 펑터라고 할 수 있다.
펑터라는 것은 추상적인 개념일 뿐이지 구체적으로 특정 로직만을 수행하는 구현체가 아니라는 말이다. 말 그대로 코에 붙히면 코걸이고 귀에 붙히면 귀걸이기 때문에 단순히 뭔가로 값을 감싸고 그 값을 변환할 수 있다는 개념만으로도 마음껏 상상의 나래를 펼치며 다양한 펑터 구현체들을 만들어낼 수 있다.
마치며
이 포스팅을 읽는 독자 분들 중 펑터에 대한 설명을 읽으면서 “어? 이거 모나드 아닌가?”라고 하신 분들도 있을 것이라 생각한다.
정확히 말하면 반은 맞고 반은 틀리다. 모나드도 결국 함수를 안전하게 합성하기 위한 펑터의 한 종류이기 때문이다. 간단하게 말하면 모나드라는 것은 수학적으로 특별한 몇 가지 조건을 만족시키는 두 개의 펑터 사이의 사상이라고 할 수 있다.
어플리케이티브 펑터나 모나드를 이 포스팅에서 따로 설명하지는 않았지만, 뭐 원리가 어쩌고 저쩌고를 떠나서 그냥 이런 개념들을 추가적으로 사용하는 이유는 그냥 딱 한 가지 밖에 없다.
어 뭐여…? 펑터로도 해결이 안되네…?
함수의 안전한 합성이라는 목표를 이루기 위해 펑터를 사용했지만 사실 프로그래밍을 하다보면 펑터로 해결이 안되는 케이스도 수두룩하기 때문이다. 뭐 펑터로 여러 번 감싸져 있는 값에 매핑해야한다거나 하는 케이스말이다. 이런 경우에는 펑터의 매핑만으로는 함수를 합성할 수 없다.
결국 어플리케이티브 펑터나 모나드는 펑터로도 해결되지 않는 예외 상황들까지 모두 커버할 수 있도록 더 추상적이고 강력하게 만든 펑터라고 생각하면 된다.
사실 이번 포스팅에서 모나드의 개념까지 설명을 해보려고 했지만, 이 포스팅에서 펑터를 설명했던 방식으로 모나드를 설명하기 위해서는 개요 수준의 카테고리 이론이 아니라 조금 더 깊숙한 설명이 필요하기 때문에 포기했다. (모나드는 다음 포스팅에서 한 번 조져보겠다)
물론 함수의 합성과 펑터와의 관계를 파악하는 것은 꽤나 추상적인 개념이기 때문에 이해하기에 조금 어렵긴 하다. 그런 이유로 어떤 개발자들은 펑터와 모나드의 사용 방법 정도만 익히고 프로그래밍하기도 하지만, 개인적으로는 이러한 개념들이 왜 사용되는 것인지, 어디서 아이디어를 얻은 것인지 알고 있다면 프로그래밍이 더 재밌어지지 않을까라는 생각이 든다.
이상으로 어떻게 하면 안전하게 함수를 합성할 수 있을까? 포스팅을 마친다.