HTTP/3는 왜 UDP를 선택한 것일까?
HTTP/3가 TCP 대신 UDP를 선택한 이유

HTTP/3는 HTTP(Hypertext Transfer Protocol)의 세 번째 메이저 버전으로, 기존의 HTTP/1, HTTP/2와는 다르게 UDP 기반의 프로토콜인 QUIC을 사용하여 통신하는 프로토콜이다. HTTP/3와 기존 HTTP 들과 가장 큰 차이점이라면 TCP가 아닌 UDP 기반의 통신을 한다는 것이다.
필자는 최근에 다른 분들이 공유해주시는 포스팅을 보고 나서 HTTP/3가 나왔다는 것을 처음 알게 되었다. 그 포스팅은 HTTP/3: the past, the present, and the future라는 포스팅이었는데, 솔직히 처음 딱 제목만 보고나서 이런 생각을 했었다.
아니, HTTP/2가 공개된지 4년 정도 밖에 안 지났는데 무슨 HTTP/3가 벌써 나와? 그냥 설계하고 있다는 거 아니야?
그런데 포스팅을 읽어 보니 이미 Google Chrome은 HTTP/3를 지원하는 카나리 빌드도 배포되어 있어서 실제로 사용까지 해볼 수 있는 단계에 도달했다는 사실을 알게 되어 놀랐다. HTTP/1에서 HTTP/2로 가는 데만 해도 대략 15년 정도의 시간이 걸렸는데, 고작 4년 만에 바로 사용해볼 수 있는 정도의 완성도인 다음 메이저 버전이 배포되었다는 것이다.
게다가 아직 전 세계의 HTTP/2 점유율을 보면 40% 정도 밖에 안된다. 그 정도로 HTTP/2가 나온지도 얼마 되지 않았다는 것이다.
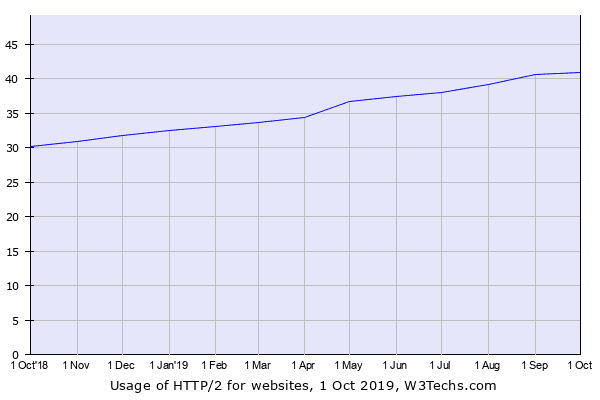 W3Techs.com에서 조사한 2019년 8월 HTTP/2 사용률
W3Techs.com에서 조사한 2019년 8월 HTTP/2 사용률
프로그래밍 언어나 프레임워크같은 친구들은 배포하는 쪽에서 업데이트를 쫙 해버리고 유저들이 업데이트를 하면 그만이지만, 프로토콜은 일종의 규약이기 때문에 소프트웨어 제조사 간 합을 맞추는 기간이 필요하므로 이렇게 단기간 안에 급격한 변화가 자주 발생하지 않을 것이라고 생각했다.
아무리 요즘 기술의 변화가 빠르다지만, HTTP는 나름 웹의 근간이 되는 프로토콜인데 꼴랑 4년 만에 이런 급격한 변화가 일어났다는 게 놀라울 따름이다. (몇 달 전에 HTTP/2를 처음 도입해본 웹 개발자는 웁니다)
그리고 또 한가지 놀랐던 점은 HTTP/3는 TCP가 아닌 UDP를 사용한다는 것이었다. 뭐 딱히 웹 프로토콜이 무조건 TCP만 사용해야 한다는 법이 있는 건 아니긴 하지만, 학교에서 배울 때도 그렇고 실무에서도 실제로 사용할 때도 그렇고 HTTP는 TCP 위에서 정의된 프로토콜이라는 사실이 너무 당연하게 인식되어 있었기 때문에 UDP를 사용한다는 점이 신기하기도 했고 “왜 멀쩡히 잘 돌아가는 TCP를 냅두고 UDP를 사용하는거지?”라는 의문도 들었다.
사실 HTTP/3는 정식으로 배포된 프로토콜이라기보다 아직 테스트를 거치고 있는 단계라고 보는 게 맞다. 하지만 위에서 이야기 했듯이 Google Chrome은 이미 HTTP/3를 지원하는 카나리 빌드를 배포한 상태이고, Mozila Firefox도 조만간 Nightly 버전에서 HTTP/3를 지원할 예정이며, cURL에서도 HTTP/3를 실험적 기능으로 제공하고 있는 만큼 가까운 미래 안에 HTTP/3가 메인 프로토콜이 될 가능성이 높은 것도 사실이다.
만약 Google Chrome에서 HTTP/3 프로토콜을 사용해보고 싶다면 터미널에서 --enable-quic과 --quic-version=h3-23 인자를 사용하여 실행하면 된다.
$ open -a Google\ Chrome --args --enable-quic --quic-version=h3-23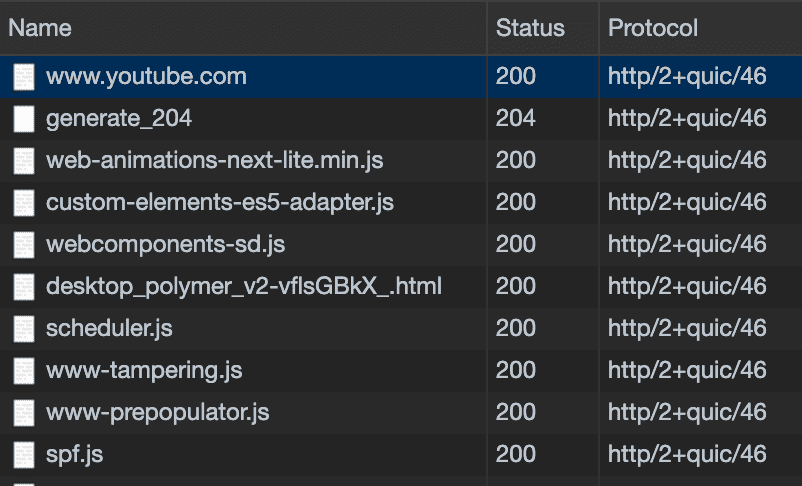 http/2+quic/46이라고 되어있는 녀석들이 HTTP/3 프로토콜을 사용한 연결이다
http/2+quic/46이라고 되어있는 녀석들이 HTTP/3 프로토콜을 사용한 연결이다
필자는 웹 개발자이기 때문에 HTTP가 메이저 업데이트 된다는 사실을 그냥 넘기기는 힘들었고, UDP를 사용한다는 것이 뭘 의미하는지도 궁금하기도 해서 결국 HTTP/3에 대한 조사를 하게 되었다. 그래서 이번 포스팅에서는 필자가 여기저기 쑤셔보면서 알아본 HTTP/3에 대한 내용을 정리해볼까 한다.
HTTP/3에 대한 간단한 소개
사실 HTTP/3는 처음에는 “HTTP-over-QUIC”이라는 이름을 가지고 있었는데, IETF(Internet Engineering Task Force) 내 HTTP 작업 그룹과 QUIC 작업 그룹의 의장인 마크 노팅엄이 이 프로토콜의 이름을 HTTP/3로 변경할 것을 제안했고, 2018년 11월에 이 제안이 통과되어 HTTP-over-QUIC이라는 이름에서 HTTP/3으로 변경되게 되었다.
즉, HTTP/3는 QUIC이라는 프로토콜 위에서 돌아가는 HTTP인 것이다. QUIC은 “Quick UDP Internet Connection”의 약자로, 말 그대로 UDP를 사용하여 인터넷 연결을 하는 프로토콜이다. (참고로 발음은 그냥 “퀵”이라고 한다)
HTTP/3는 QUIC을 사용하고, QUIC은 UDP를 사용하기 때문에 결과적으로 HTTP/3는 UDP를 사용한다고 이야기 할 수 있는 것이다.
그렇다면 QUIC이 도대체 뭐길래 기존의 TCP보다 더 빠른 전송 속도를 가질 수 있다는 것일까? 그 이유를 알려면 먼저 TCP가 왜 느리다고 하는지, UDP를 사용함으로써 어떤 이득을 얻을 수 있는지 부터 알아야 한다.
TCP가 왜 느리다고 하는 걸까?
필자는 학교에서 네트워크 강의를 들을 때 TCP와 UDP의 차이에 대한 내용을 처음 배웠었는데, 교수님이 이건 반드시 시험에 나온다길래 이런 표를 보면서 열심히 외웠던 기억이 난다.
| TCP | UDP | |
|---|---|---|
| 연결 방식 | 연결형 서비스 | 비연결형 서비스 |
| 패킷 교환 | 가상 회선 방식 | 데이터그램 방식 |
| 전송 순서 보장 | 보장함 | 보장하지 않음 |
| 신뢰성 | 높음 | 낮음 |
| 전송 속도 | 느림 | 빠름 |
위 표를 보면 대략 “TCP는 신뢰성이 높고 느리다”, “UDP는 신뢰성이 낮고 빠르다” 정도로 정리가 되는데, 여기서 말하는 신뢰성이란 전송되는 데이터 패킷들의 순서, 패킷 유실 여부 등을 검사하여 송신 측이 보낸 모든 데이터가 수신 측에 온전하게 전달이 될 수 있느냐를 말하는 것이다.
TCP는 클라이언트와 서버가 서로 신뢰성있는 통신을 할 수 있도록 몇 가지 방법을 사용하게되는데, 이 방법들 또한 결국은 클라이언트와 서버 간의 통신이기 때문에 레이턴시가 발생할 수 밖에 없다. 게다가 이 과정은 TCP라는 프로토콜이 생길 때부터 정의된 표준이므로 무시할 수도 없다.
그렇다면 레이턴시를 줄이기 위해서는 TCP에서 정의한 기능 외에 다른 부분들을 건드려야 한다는 것인데, 여러모로 제한 사항이 많다. 아무리 회선의 대역폭을 늘린다고 해도 기술이 발전하면서 전송해야하는 데이터의 크기도 점점 커지기 때문에 결국 언젠가는 또 느려질 것이고, 회선의 전송 속도 자체를 높힌다고 해도 결국은 빛의 속도 보다 빠르게 전송할 수 없기 때문에 한계가 있다.
HTTP/3이 UDP 기반인 QUIC 프로토콜을 사용하는 이유가 바로 이런 제약 조건을 뛰어넘기 위해 프로토콜 자체를 손보는 방법을 택한 것이다. 하지만 TCP는 워낙 오래된 프로토콜이기도 하고 커널까지 내려가는 로우 레벨에서 정의되어 있기 때문에 이걸 뜯어고치는 것도 만만치 않은 대작업이라 UDP를 선택한 것이다.
그럼 한번 TCP가 신뢰성 있는 통신을 위해 사용하는 방법들이 왜 느리다고 하는지 알아보자.
3 Way Handshake
TCP는 굉장히 친절한 프로토콜이다. 통신을 시작할 때와 종료할 때 서로 준비가 되어있는지를 반드시 먼저 물어보고 패킷을 전송할 순서를 정하고 나서야 본격적인 통신을 시작하기 때문이다.
이때 통신을 시작할 때 거치는 과정을 3 Way Handshake, 통신을 마칠 때 거치는 과정을 4 Way Handshake라고 한다. 이 포스팅의 목적은 이 과정을 자세히 다루는 것이 아니므로, TCP를 사용하여 통신을 시작할 때 거치는 과정인 3 Way Handshake가 어떤 원리로 작동하는지만 설명하겠다.
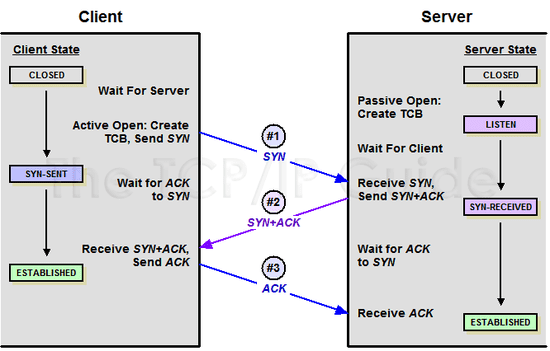 통신을 시작할 때 3 Way Handshake를 하는 과정
통신을 시작할 때 3 Way Handshake를 하는 과정
위 그림을 보면 클라이언트가 처음 서버와 통신을 하기 위해 TCP 연결을 생성할 때 SYN와 ACK라는 패킷을 주고 받고 있다. 이 패킷 내부에 들어있는 값들을 사용하여 클라이언트와 서버가 서로 보낸 패킷의 순서와 패킷을 제대로 받았는 지를 확인할 수 있는 것이다.
그리고 이 과정에는 총 3번의 통신이 필요하다. OSX나 Linux를 사용하고 있는 분이라면 터미널에서 tcpdump 유틸리티를 사용하여 이 과정을 직접 눈으로 확인해볼 수 있다.
단, tcpdump를 아무 옵션 없이 사용하면 디바이스의 모든 패킷을 감시하고 출력하기 때문에 원하는 정보를 찾기 힘들다. 그래서 필자는 루프백에서 동작하고 있는 블로그 서버와의 통신만 캡쳐해보았다.
$ sudo tcpdump host localhost -i lo0
IP localhost.53920 > localhost.terabase: Flags [S], seq 1260460927, win 65535
IP localhost.terabase > localhost.53920: Flags [S.], seq 3009967847, ack 1260460928, win 65535
IP localhost.53920 > localhost.terabase: Flags [.], ack 3009967848, win 6379보낸 놈 > 받은 놈: Flags [플래그 종류], 헤더의 값들
원래는 이것보다 더 많은 정보가 나오지만, 여기에 전부 기재하기에는 양이 너무 많으니 설명에 필요한 정보만 추려보았다. 이 로그에서 중요한 키워드는 Flag, seq, ack 정도이다. 한번 하나하나 뜯어보도록 하자.
먼저 localhost.53920은 클라이언트, localhost.terabase는 서버를 의미한다. 각 라인의 첫번째 필드는 보낸 놈 > 받은 놈을 의미하고 있으니, 첫 패킷은 클라이언트가 서버에게, 두 번째 패킷은 서버가 클라이언트에게 보낸 것이라고 할 수 있다. 그리고 각 라인에는 Flag라는 것이 붙어있는데, 플래그는 이 패킷이 어떤 타입의 패킷인지를 알려주는 역할을 한다.
| Flag | 이름 | 의미 |
|---|---|---|
| S | SYN | 연결을 생성할 때 클라이언트가 서버에 시퀀스 번호를 보내는 패킷 |
| S. | SYN-ACK | 시퀀스 번호를 받은 서버가 ACK 값을 생성하여 클라이언트에게 응답하는 패킷 |
| . | ACK | ACK 값을 사용하여 응답하는 패킷 |
이 통신 과정을 거치고 나면 클라이언트와 서버는 신뢰성 있는 TCP 연결을 생성할 수 있고, 이때 총 3회의 통신을 하기 때문에 3 Way Handshake라고 하는 것이다.
그렇다면 이 과정에서 어떤 일이 벌어지길래 신뢰성 있는 연결을 생성할 수 있다는 것일까? 조금 더 자세히 들여다보면 클라이언트와 서버는 3 Way Handshake를 할 때 대략 이런 과정을 거치고 있다.
1번 라인: 클라이언트가 서버로 시퀀스 번호를
seq필드에 담아 보냄
2번 라인: 서버는 클라이언트가 보내준 시퀀스 번호를 1 증가시켜서ack필드에 담아 보냄
3번 라인: 클라이언트는 다시 서버로부터 받은 시퀀스 번호를 1 증가시켜서 자신의ack필드에 담아 보냄
새로운 TCP 연결을 생성하고자 할 때 클라이언트가 서버에게 랜덤한 시퀀스 번호를 전송함으로써 3 Way Handshake가 시작된다. 이때 생성된 시퀀스 번호는 이후 송신 측이 전송한 패킷을 수신 측이 재조립할때 패킷의 조립 순서를 알려주는 역할을 한다.
이때 클라이언트와 서버는 상대방이 보내준 seq(시퀀스 번호)를 1 증가 시킨 후 자신의 ack(승인 번호) 필드에 담아서 보내는데, “지금 이 패킷이 니가 전에 보낸 시퀀스 번호의 다음으로 이어지는 패킷이야”라고 말하고 있는 것이다.
이 3회의 통신이 바로 3 Way Handshake이다. 이 과정을 통해 클라이언트와 서버는 데이터를 주고 받을 준비가 되었다는 것을 서로에게 알려주고 이후 데이터 전송에 필요한 시퀀스 번호를 알 수 있게 된다. 연결을 끊을 때도 마찬가지로 이와 비슷한 과정인 4 Way Handshake를 거치고 나서야 세션을 종료할 수 있으며, 이때는 총 4회의 통신을 통해 연결을 종료한다.
즉, TCP를 사용하는 이상 본격적인 통신을 시작하기 전에 무조건 저 번거로운 통신 과정을 거쳐야한다는 것이다.
HTTP/1은 하나의 TCP 연결에 하나의 요청만 처리하고 연결을 끊어버렸기 때문에 매 요청마다 이 번거로운 핸드쉐이크를 거쳐야 했다. 그래서 HTTP/2에서는 핸드쉐이크를 최소화하기 위해서 단일 TCP 연결을 유지하면서 여러 개의 요청을 처리할 수 있도록 변경된 것이다.
결국 HTTP/1에서 HTTP/2로 넘어갈 때도 핸드쉐이크 과정 자체는 건드리지 않았고 단지 핸드쉐이크가 발생하는 횟수를 최소화함으로써 레이턴시를 줄인 것이다. 이는 TCP를 사용하는 이상 핸드쉐이크가 반드시 필요한 과정이기 때문에 건드리지 못한 것이다.
그러나 HTTP/3는 UDP를 사용함으로써 이 핸드쉐이크 과정 자체를 날려버리고 다른 방법으로 연결의 신뢰성을 확보함으로써 레이턴시를 줄이는 방법을 택했다.
HOLB(Head of line Blocking)
그 외에도 TCP를 사용하는 기존의 HTTP에는 한 가지 문제가 더 있는데, 바로 HOLB(Head of Line Blocking)라고 하는 문제이다. 사실 HTTP 레벨에서의 HOLB와 TCP 레벨에서의 HOLB는 다른 의미이기는 하나 결국 어떤 요청에 병목이 생겨서 전체적인 레이턴시가 늘어난다는 맥락으로 본다면 동일하다고 할 수 있다.
TCP를 사용한 통신에서 패킷은 무조건 정확한 순서대로 처리되어야 한다. 수신 측은 송신 측과 주고받은 시퀀스 번호를 참고하여 패킷을 재조립해야하기 때문이다.
그래서 통신 중간에 패킷이 손실되면 완전한 데이터로 다시 조립할 수 없기 때문에 절대로 그냥 넘어가지 않는다. 무조건 송신 측은 수신 측이 패킷을 제대로 다 받았다는 것을 확인한 후, 만약 수신 측이 제대로 패킷을 받지 못했으면 해당 패킷을 다시 보내야 한다.
또한 패킷이 처리되는 순서 또한 정해져있으므로 이전에 받은 패킷을 파싱하기 전까지는 다음 패킷을 처리할 수도 없다. 이렇게 패킷이 중간에 유실되거나 수신 측의 패킷 파싱 속도가 느리다면 통신에 병목이 발생하게 되는 현상을 “HOLB”라고 부르는 것이다. 이건 TCP 자체의 문제이므로 HTTP/1 뿐만 아니라 HTTP/2도 가지고 있는 문제이다.
이런 문제들을 해결하기 위해 HTTP/3는 UDP를 기반으로 만들어진 프로토콜인 QUIC 위에서 작동하는 것을 선택한 것이다. 그럼 이제 QUIC가 정확히 어떤 프로토콜인지, UDP를 사용한다는 것이 TCP에 비해서 어떤 장점이 있다는 것인지를 알아보자.
HTTP/3가 UDP를 사용하는 이유
HTTP/3는 QUIC을 기반으로 돌아가는 프로토콜이기 때문에 우리가 HTTP/3를 이해하려면 QUIC에 초점을 맞춰야 한다. QUIC은 TCP가 가지고 있는 이런 문제들을 해결하고 레이턴시의 한계를 뛰어넘고자 구글이 개발한 UDP 기반의 프로토콜이다.
QUIC은 처음부터 TCP의 핸드쉐이크 과정을 최적화하는 것에 초점을 맞추어 설계되었고, UDP를 사용함으로써 이를 실현해낼 수 있었다.

UDP는 User Datagram Protocol이라는 이름에서도 알 수 있듯이 데이터그램 방식을 사용하는 프로토콜이기 때문에 애초에 각각의 패킷 간의 순서가 존재하지 않는 독립적인 패킷을 사용한다. 또한 데이터그램 방식은 패킷의 목적지만 정해져있다면 중간 경로는 어딜 타든 신경쓰지 않기 때문에 종단 간의 연결 설정 또한 하지 않는다. 즉, 핸드쉐이크 과정이 필요없다는 것이다.
결론적으로 UDP는 TCP가 신뢰성을 확보하기 위해 거치던 많은 과정을 거치지 않기 때문에 속도가 더 빠를 수 밖에 없다는 것인데, 그렇다면 UDP를 사용하게되면 기존의 TCP가 가지던 신뢰성과 패킷의 무결함도 함께 사라지는 걸까?
아니 그렇지 않다. UDP를 사용하더라도 기존의 TCP가 가지고 있던 기능을 전부 구현할 수 있다. UDP의 진짜 장점은 바로 커스터마이징이 용이하다는 것이기 때문이다.
UDP는 하얀 도화지 같은 프로토콜이다
필자는 학교에서 UDP와 TCP의 가장 큰 차이점으로 “UDP는 TCP보다 신뢰성이 없는 대신 빠르다”라고 배웠었는데, 사실 이 말은 반은 맞고 반은 틀리다.
왜냐면 애초에 UDP는 데이터 전송을 제외한 그 어떤 기능도 정의되어 있지 않은 프로토콜이기 때문에 프로토콜 자체적으로 신뢰성을 보장하지 않는 것은 맞지만, 다르게 말하자면 데이터 전송 기능을 제외한 아무 기능이 없는 백지 상태의 프로토콜이라고도 할 수 있기 때문이다. TCP가 신뢰성있는 연결과 혼잡 제어 등을 위해 얼마나 많은 기능을 가지고 있는 지는 TCP의 헤더를 보면 대충 각이 나온다.
 이미 정보들이 뚱뚱하게 들어찬 TCP의 헤더
이미 정보들이 뚱뚱하게 들어찬 TCP의 헤더
TCP의 경우 워낙 오래 전에 설계되기도 했고, 이런 저런 기능이 워낙 많이 포함된 프로토콜이다보니 이미 헤더가 거의 풀방이다. TCP에 기본적으로 정의되어 있는 기능 외에 다른 추가 기능을 구현하고 싶다면 가장 하단에 있는 옵션(Options) 필드를 사용해야 하는데, 옵션 필드도 무한정 배당 해줄 수는 없으니 최대 크기를 320 bits로 정해놓았다.
그러나 TCP의 단점을 보완하기 위해 나중에 정의된 MSS(Maximum Segment Size), WSCALE(Window Scale factor), SACK(Selective ACK) 등 많은 옵션들이 이미 옵션 필드를 차지하고 있기 때문에 실질적으로 사용자가 커스텀 기능을 구현할 수 있는 자리는 거의 남지도 않았다.
반면 UDP는 데이터 전송 자체에만 초점을 맞추고 설계되었기 때문에 헤더에 진짜 아무 것도 없다.
 TCP와 비교해보면 확실히 휑한 UDP의 헤더
TCP와 비교해보면 확실히 휑한 UDP의 헤더
UDP의 헤더에는 출발지와 도착지, 패킷의 길이, 체크섬 밖에 없다. 이때 체크섬은 패킷의 무결성을 확인하기 위해 사용되는데, TCP의 체크섬과는 다르게 UDP의 체크섬은 사용해도 되고 안해도 되는 옵션이다.
즉, UDP 프로토콜 자체는 TCP보다 신뢰성이 낮기도 하고 흐름 제어도 안되지만, 이후 개발자가 어플리케이션에서 구현을 어떻게 하냐에 따라서 TCP와 비슷한 수준의 기능을 가질 수도 있다는 것이다.
물론 TCP가 신뢰성을 확보하기위해 이런 저런 기능을 제공해주는 것이 개발자 입장에서는 편하고 좋지만, 한가지 슬픈 점은 이 기능들이 프로토콜 자체에 정의된 필수 과정이라서 개발자가 맘대로 커스터마이징 할 수 없다는 것이다. 결국 여기서 발생하는 레이턴시들을 어떻게 더 줄여볼 시도조차 하기 힘들다.
 TCP에 TLS까지 사용한다면 통신을 시작하기도 전에 이렇게 많은 과정을 거쳐야 한다
TCP에 TLS까지 사용한다면 통신을 시작하기도 전에 이렇게 많은 과정을 거쳐야 한다
결국 레이턴시를 줄이려면 프로토콜 외적인 것들을 건드려야 하는데, 위에서 이야기 했듯이 일반적인 개발자가 통신 과정에서 건드릴 수 있는 영역은 한계가 있기 때문에 이 또한 어려운 것이 사실이다.(통신 업계의 큰 손 형님들이 인프라를 깔아주시는 걸 기다리자)
아직 TCP와 UDP의 차이가 잘 와닿지 않는다면 “좋은 기능이 다 들어있는 무거운 라이브러리”와 “필요한 기능만 들어있는 가벼운 라이브러리”로 비교해보면 조금 더 이해가 빠를 것 같다.
예를 들어 JavaScript 진영에서 많이 사용하는 lodash와 같은 라이브러리는 기능은 무궁무진하고 사용자에게 큰 편리함을 주지만, 보통 lodash의 모든 메소드를 다 사용하는 사람은 많지 않을 것이다. 결국 편하긴 하지만 내가 사용하지 않는 기능까지 전부 내 JS 번들에 포함시켜야 한다는 부담이 있다.
반면 단순한 하나의 기능을 제공하는 라이브러리는 lodash보다 기능은 많지 않아도 내가 원하는 부분만 쏙쏙 골라서 사용할 수 있다는 장점이 있다. 하지만 해당 라이브러리에서 지원하지 않는 기능은 직접 구현해야하는 번거로움이 있을 수도 있다. 이때 lodash와 같은 만능 라이브러리가 TCP, 하나의 기능만 제공하는 작은 라이브러리가 UDP인 것이다.
이렇듯 구글이 QUIC을 만들 때 UDP를 선택한 이유에는 기존의 TCP를 수정하기가 어려운데다가, 백지 상태나 다름 없는 UDP를 사용함으로써 QUIC의 기능을 확장하기 쉽다고 생각했기 때문이라는 것도 있다.
HTTP/3가 UDP를 사용함으로써 기존 프로토콜보다 나아진 점
지금까지 HTTP/3의 뼈대로 사용되는 QUIC이 왜 TCP가 아닌 UDP를 사용했는지 간략하게 알아보았다. 그렇다면 실제로 UDP를 사용함으로써 얻는 이득에는 무엇이 있을까? 진짜로 HTTP/3는 UDP를 사용함으로써 기존의 HTTP + TCP + TLS를 사용했던 방법보다 더 좋아진 것 일까?
그에 대한 해답은 Chromium Projects의 QUIC Overview라는 문서에서 찾을 수 있었다. 한번 구글이 이야기하는 QUIC의 장점에 대해서 살펴보자.
연결 설정 시 레이턴시 감소
QUIC은 TCP를 사용하지 않기 때문에 통신을 시작할 때 번거로운 3 Way Handshake 과정을 거치지 않아도 된다. 클라이언트가 보낸 요청을 서버가 처리한 후 다시 클라이언트로 응답해주는 사이클을 “RTT(Round Trip Time)“라고 하는데, TCP는 연결을 생성하기 위해 기본적으로 1 RTT가 필요하고, 여기에 TLS를 사용한 암호화까지 하려고 한다면 TLS의 자체 핸드쉐이크까지 더해져 총 3 RTT가 필요하다.
반면 QUIC은 첫 연결 설정에 1 RTT만 소요된다. 클라이언트가 서버에 어떤 신호를 한번 주고, 서버도 거기에 응답하기만 하면 바로 본 통신을 시작할 수 있다는 것이다. 즉, 연결 설정에 소요되는 시간이 반 정도 밖에 안된다.
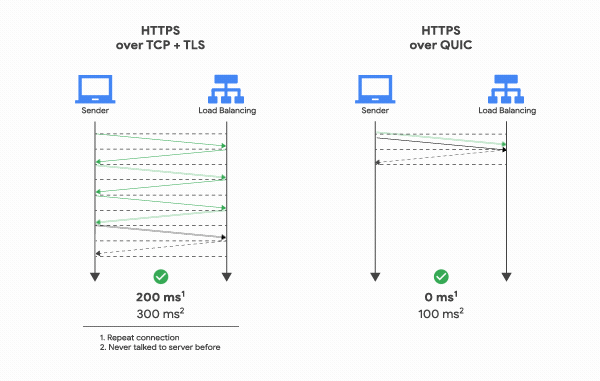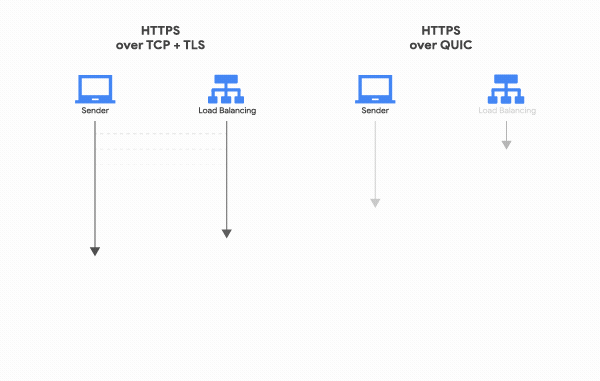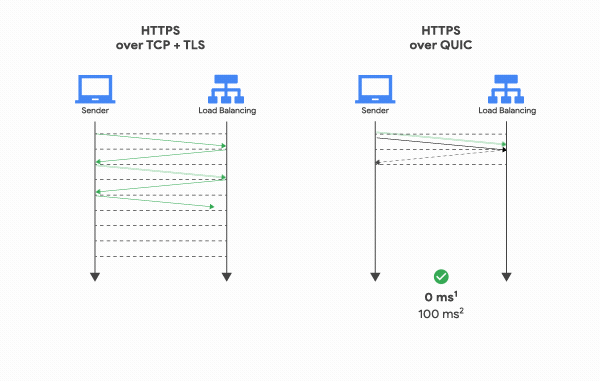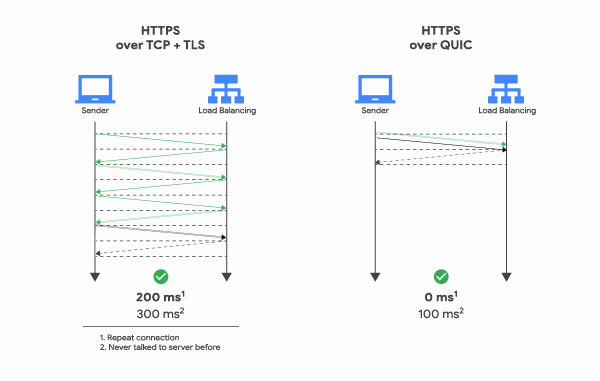
어떻게 이게 가능한 걸까? 그 이유는 생각보다 간단하다. 첫번째 핸드쉐이크를 거칠 때, 연결 설정에 필요한 정보와 함께 데이터도 보내버리는 것이다. TCP + TLS는 데이터를 보내기 전에 신뢰성있는 연결과 암호화에 필요한 모든 정보를 교환하고 유효성을 검사한 뒤에 데이터를 교환하지만, QUIC은 묻지도 따지지도 않고 그냥 바로 데이터부터 꽂아버리고 시작한다.
이 과정에 대해서는 2015년 IEEE Symposium에서 발표된 ”How Secure and Quick is QUIC?“이라는 세션에서 자세히 들어볼 수 있다.
한 손 주머니에 꽂고 발표하는 모습에서 스웩이 넘친다
결국 이 영상에서 말하고자 하는 것은 TCP + TLS는 서로 자신의 세션 키를 주고 받아 암호화된 연결을 성립하는 과정을 거치고 나서야 세션 키와 함께 데이터를 교환할 수 있지만, QUIC은 서로의 세션 키를 교환하기도 전에 데이터를 교환할 수 있기 때문에 연결 설정이 더 빠르다는 것이다.
단, 클라이언트가 서버로 첫 요청을 보낼 때는 서버의 세션 키를 모르는 상태이기 때문에 목적지인 서버의 Connection ID를 사용하여 생성한 특별한 키인 초기화 키(Initial Key)를 사용하여 통신을 암호화 한다. 이 과정에 대한 자세한 설명은 QUIC 작업 그룹의 Using TLS to Secure QUIC 문서에서 확인 해볼 수 있다.
그리고 한번 연결에 성공했다면 서버는 그 설정을 캐싱해놓고 있다가, 다음 연결 때는 캐싱해놓은 설정을 사용하여 바로 연결을 성립시키기 때문에 0 RTT만으로 바로 통신을 시작할 수도 있다. 이런 점들 때문에 QUIC은 기존의 TCP+TLS 방식에 비해 레이턴시를 더 줄일 수 있었던 것이다.
참고로 이 세션이 발표될 당시에는 TLS 1.3이 나오기 전이라 따로 언급이 되지 않았지만, 지금은 TCP Fast Open과 TLS 1.3을 사용하여 QUIC와 비슷한 과정을 통해 연결을 설정함으로써 TCP를 사용하더라도 동일한 이점을 가져갈 수도 있긴하다.
그러나 TCP SYN 패킷은 한 패킷당 약 1460 Byte만 전송할 수 있도록 제한하지만 QUIC은 데이터 전체를 첫 번째 라운드 트립에 포함해서 전송할 수 있기 때문에 주고 받아야할 데이터가 큰 경우에는 여전히 QUIC가 유리하다고 할 수 있다.
패킷 손실 감지에 걸리는 시간 단축
QUIC도 TCP와 마찬가지로 전송하는 패킷에 대한 흐름 제어를 해야한다. 왜냐면 QUIC든 TCP든 결국 본질적으로는 ARQ 방식을 사용하는 프로토콜이기 때문이다. 통신과정에서 발생한 에러를 어떻게 처리할 것인지를 이야기하는 것인데, ARQ 방식은 에러가 발생하면 재전송을 통해 에러를 복구하는 방식을 말하는 것이다.
TCP는 여러 ARQ 방식 중에서 “Stop and Wait ARQ” 방식을 사용하고 있다. 이 방식은 송신 측이 패킷을 보낸 후 타이머를 사용하여 시간을 재고, 일정 시간이 경과해도 수신 측이 적절한 답변을 주지 않는다면 패킷이 손실된 것으로 판단하고 해당 패킷을 다시 보내는 방식이다.
우선 2017년 구글에서 발표한 QUIC Loss Detection and Congestion Control에 따르면, QUIC은 기본적으로 TCP와 유사한 방법으로 패킷 손실을 탐지하나, 몇 가지 개선 사항을 추가한 것으로 보인다.
TCP에서 패킷 손실 감지에 대한 대표적인 문제는 송신 측이 패킷을 수신측으로 보내고 난 후 얼마나 기다려줄 것인가, 즉 타임 아웃을 언제 낼 것인가를 동적으로 계산해야한다는 것이다. 이때 이 시간을 RTO(Retransmission Time Out)라고 하는데, 이때 필요한 데이터가 바로 RTT(Round Trip Time)들의 샘플들이다.
한번 패킷을 보낸 후 잘 받았다는 응답을 받을 때 걸렸던 시간들을 측정해서 동적으로 타임 아웃을 정하는 것이다. 즉, RTT 샘플을 측정하기 위해서는 반드시 송신 측으로 부터 ACK를 받아야하는데, 정상적인 상황에서는 딱히 문제가 없으나 타임 아웃이 발생해서 패킷 손실이 발생하게 되면 RTT 계산이 애매해진다.
패킷 전송 -> 타임 아웃 -> 패킷 재전송 -> ACK 받음!
(근데 이거 첫 번째로 보낸 패킷의 ACK야? 두 번째로 보낸 패킷의 ACK야?)
이때 이 ACK가 어느 패킷에 대한 응답인지 알기 위해서는 타임스탬프를 패킷에 찍어주는 등 별도의 방법을 또 사용해야하고, 또 이를 위한 패킷 검사도 따로 해줘야 한다. 이를 재전송 모호성(Retransmission Ambiguity)이라고 한다.
이 문제를 해결하기 위해 QUIC는 헤더에 별도의 패킷 번호 공간을 부여했다. 이 패킷 번호는 패킷의 전송 순서 자체만을 나타내며, 재전송시 동일한 번호가 전송되는 시퀀스 번호와는 다르게 매 전송마다 모노토닉하게 패킷 번호가 증가하기 때문에, 패킷의 전송 순서를 명확하게 파악할 수 있다.
TCP의 경우 타임스탬프를 사용할 수 있는 상황이라면 타임스탬프를 통해 패킷의 전송 순서를 파악할 수 있지만, 만약 사용할 수 없는 경우 시퀀스 번호에 기반하여 암묵적으로 전송 순서를 추론할 수 밖에 없지만, QUIC는 이런 불필요한 과정을 패킷마다 고유한 패킷 번호를 통해 타파함으로써 패킷 손실 감지에 걸리는 시간을 단축할 수 있었다.
이 외에도 QUIC는 대략 5가지 정도의 기법을 사용하여 이 패킷 손실 감지에 걸리는 시간을 단축시켰는데, 자세한 내용은 QUIC Loss Detection and Congestion Control의 “3.1 Relevant Differences Between QUIC and TCP” 챕터를 한번 읽어보는 것을 추천한다.
멀티플렉싱을 지원
멀티플렉싱(Multiplexing)은 위에서 TCP의 단점으로 언급했던 HOLB를 방지하기 때문에 매우 중요하다. 여러 개의 스트림을 사용하면, 그 중 특정 스트림의 패킷이 손실되었다고 하더라도 해당 스트림에만 영향을 미치고 나머지 스트림은 멀쩡하게 굴릴 수 있기 때문이다.
참고로 멀티플렉싱은 여러 개의 TCP 연결을 만든다는 의미가 아니라, 단일 연결 안에서 몇 가지 얌생이를 사용하여 여러 개의 데이터를 섞이지 않게 보내는 기법이다. 이때 각각의 데이터의 흐름을 스트림(Stream)이라고 하는 것이다.
HTTP/1의 경우는 하나의 TCP 연결에 하나의 스트림만 사용하기 때문에 HOLB 문제에서 벗어날 수 없었다. 또한 한번의 전송이 끝나게 되면 연결이 끊어지기 때문에 다시 연결을 만들기 위해서는 번거로운 핸드쉐이크 과정을 또 겪어야 했다.
비록 keep-alive 옵션을 통해 어느 정도의 시간 동안 연결을 유지할 수는 있지만 결국 일정 시간 안에 액세스가 없다면 연결이 끊어지게 되는 것은 똑같다.
그리고 HTTP/2는 하나의 TCP 연결 안에서 여러 개의 스트림을 처리하는 멀티플렉싱 기법을 도입하여 성능을 끌어올린 케이스이다. 이 경우 한번의 TCP 연결로 여러 개의 데이터를 전송할 수 있기 때문에 핸드쉐이크 횟수도 줄어들게 되어 효율적인 데이터 전송을 할 수 있게 된다.

HTTP/3도 HTTP/2와 같은 멀티플렉싱을 지원한다.
QUIC 또한 HTTP/2와 동일하게 멀티플렉싱을 지원하기 때문에, 이런 이점을 그대로 가져가고 있다. 혹여나 하나의 스트림에서 문제가 발생한다고 해도 다른 스트림은 지킬 수 있게 되어 이런 문제에서 자유로울 수 있다.
클라이언트의 IP가 바뀌어도 연결이 유지됨
TCP의 경우 소스의 IP 주소와 포트, 연결 대상의 IP 주소와 포트로 연결을 식별하기 때문에 클라이언트의 IP가 바뀌는 상황이 발생하면 연결이 끊어져 버린다. 연결이 끊어졌으니 다시 연결을 생성하기 위해 결국 눈물나는 3 Way Handshake 과정을 다시 거쳐야한다는 것이고, 이 과정에서 다시 레이턴시가 발생한다.
게다가 요즘에는 모바일로 인터넷을 사용하는 경우가 많기 때문에 Wi-fi에서 셀룰러로 전환되거나 그 반대의 경우, 혹은 다른 Wi-fi로 연결되는 경우와 같이 클라이언트의 IP가 변경되는 일이 굉장히 잦아서 이 문제가 더 눈에 띈다.
반면 QUIC은 Connection ID를 사용하여 서버와 연결을 생성한다. Connection ID는 랜덤한 값일 뿐, 클라이언트의 IP와는 전혀 무관한 데이터이기 때문에 클라이언트의 IP가 변경되더라도 기존의 연결을 계속 유지할 수 있다. 이는 새로 연결을 생성할 때 거쳐야하는 핸드쉐이크 과정을 생략할 수 있다는 의미이다.
마치며
사실 HTTP/3와 QUIC을 제대로 설명하기 위해서는 네트워크에 대한 기본 개념들이 필수적으로 동반되야하기 때문에 이 짧은 포스팅 만으로 세부적인 설명을 하기 힘든 부분이 있었다. 최대한 자세하게 작성해보려고 했지만 생각보다 글이 너무 길어지게 되어서 분량 조절을 조금 하려고 한다.
이번에 HTTP/3를 공부해보고 여러가지 자료를 찾아보면서 느낀 점은 “뭐가 이렇게 많이 바뀌었어?” 였던 것 같다. 일단 TCP부터 갖다 버렸으니 뭐가 많이 바뀔만 하긴 했지만, HTTP/2를 사용해본지도 몇 달 밖에 되지 않은 필자의 입장에서는 조금 당황스럽기는 했다. (HTTP를 만든다면서 TCP를 갖다 버린 건 아직도 신기하다)
사실 개발자들이 HTTP/2를 사용하든 HTTP/3를 사용하든 한국에서 인터넷을 사용하고 있는 사용자는 별로 큰 차이를 못 느낄 것이다. 한국은 워낙 땅덩이도 작고 통신 인프라도 좋다보니 핸드쉐이크 레이턴시고 나발이고 그냥 인프라로 대충 커버칠 수 있지만, 그래도 상대적으로 통신 인프라가 빈약한 나라의 경우에는 꽤 큰 차이가 느껴질 수도 있을 것 같다.
필자가 이 포스팅에서는 HTTP/3와 UDP의 장점만을 이야기했지만, 사실 많은 사람들이 TCP를 버리고 UDP로 갈아타는 것에 대해서 걱정하고 있다. 당연히 완벽한 기술이란 없으니 문제도 있을 것이다.
그러나 기존의 HTTP와 TCP가 가지고 있는 한계를 돌파하기 위한 시도로는 굉장히 좋은 것 같다. 마치 엔비디아의 RTX 시리즈 같은 느낌이랄까.
이상으로 HTTP/3는 왜 UDP를 선택한 것일까? 포스팅을 마친다.