동기(Synchronous)는 정확히 무엇을 의미하는걸까?
실무에서 헷갈리기 쉬운 동기와 비동기의 개념 정리
는 정확히 무엇을 의미하는걸까?")
이번 포스팅에서는 I/O와 네트워크 등 전반적으로 다양한 모델에서 사용하는 개념인 동기(Synchronous)가 정확히 무엇을 의미하는 것인지, 그리고 동기 방식과 비동기 방식의 차이에 대해서 한번 이야기 해보려고 한다. 그리고 이 두 가지 개념과 많이 혼동되는 개념인 블록킹(Blocking)과 논블록킹(Non-Blocking)에 대해서도 간단하게 짚고 넘어갈 예정이다.
본격적인 포스팅에 들어가기에 앞서 한가지 확실하게 이야기하고 싶은 것은 동기와 비동기는 프로세스의 수행 순서 보장에 대한 매커니즘이고 블록킹과 논블록킹은 프로세스의 유휴 상태에 대한 개념으로 완전한 별개의 개념이라는 것이다.
아무래도 동기와 블록킹, 비동기와 논블록킹의 작동 매커니즘이 더 직관적이기 때문에 많은 사람들이 이 개념들을 같은 것 혹은 비슷한 것으로 오해하고 있는데, 방금 이야기 했듯이 이 두가지 개념은 서로 전혀 다른 곳에 초점을 맞춘 개념들이므로 서로 직접적인 관련은 거의 없다고 봐도 된다. 단지 조합하여 사용되는 것 뿐이다.
 출처 - Boost application performance using asynchronous I/O, IBM
출처 - Boost application performance using asynchronous I/O, IBM
이미 많은 능력자 분들이 이 주제에 대해서 잘 정리해놓은 포스팅들이 있지만, 대부분 이 개념들을 묶어서 함께 다루고 있기 때문에 이 개념들을 처음 접하거나 컴퓨터 공학에 대해 잘 모르는 사람은 이 개념들이 서로 뭔가 연관이 있는 것으로 오해하기 쉽다. 하지만 많은 포스팅에서 이 주제들을 묶어서 다루는 이유는 단지 이 개념들을 구현한 구현체에서 이 두 가지 개념이 함께 사용되고 있기 때문에 이 개념을 분리해서 따로 설명하는 것이 더 어렵기 때문이다.
그래서 필자도 어쩔 수 없이 이 개념들을 함께 설명하기는 하지만, 직관적인 개념인 블록킹 & 논블록킹보다는 좀 더 추상적인 개념인 동기 & 비동기에 초점을 맞춰서 진행할 것이다.
동기는 정확히 뭘 뜻하는 걸까?
동기에 관련된 포스팅들을 읽어보면 사람마다 동기라는 단어를 해석한 결과가 가지각색이다. 어떤 사람은 동시에 발생하는 것, 어떤 사람은 특정한 클럭을 정해 통신하는 것, 어떤 사람은 상태를 동일하게 만드는 것 등 동기라는 단어의 쓰임새가 다양한 만큼 다양한 해석들이 존재한다. 도대체 뭐가 맞는 건지 알기가 힘들다.
필자 또한 처음 동기라는 개념을 배울 때 동기라는 단어와 매커니즘이 잘 와닿지 않아서 혼란스러웠었다. 뭐 블록킹 같은 단어는 농구같이 일상에서 접할 수 있는 스포츠에서도 사용하고 있는데다가 “뭔가를 막는다”라는 뜻이 바로 와닿기 때문에 조금 이해하기 쉬운 편이지만 동기는 아니다.
일상에서 주로 접하는 동기의 쓰임새 중 대표적인 예는 동기화(Synchronization) 정도가 있을 것 같다. 아이폰에 음악을 넣을 때 아이튠즈에서 사용하는 동기화 기능 같은 것 말이다. 이때 동기화라는 행위는 “서로 다른 상태를 같은 것으로 만드는 것”을 의미한다.
 동기화 한번 잘못해서 아이폰에 있는 음악이 다 날아가는 경험은 다들 한번쯤 있지 않을까
동기화 한번 잘못해서 아이폰에 있는 음악이 다 날아가는 경험은 다들 한번쯤 있지 않을까
하지만 컴퓨터 공학에서는 대부분 동기를 “동시에 발생하는 것”이라고만 설명하고 있기 때문에 느낌이 조금 다르다. 물론 데이터베이스 동기화와 같이 동일한 의미로 사용되는 경우도 있지만, 많은 포스팅이 I/O나 네트워크에 대한 내용을 다루고 있기 때문에 전자의 의미로 해석되는 경우가 많다.
동기와 비동기라는 단어 중 비동기는 “동기가 아니다”라는 의미이기 때문에 우리는 동기가 정확히 무엇을 말하는 것인지에 초점을 맞춰서 생각해봐야한다.
단어의 뉘앙스를 파악해야한다
고등학교 때 언어 영역이나 외국어 영역을 공부할 때 “지문 안에 답이 있다”라는 말을 들어본 적이 있을 것이다. 공학이나 과학 분야에서 사용되는 용어는 주로 영어에서 파생되었고, 이를 한국어로 번역하는 과정에서 오히려 뜻을 알기가 어려운 단어로 번역되는 경우가 있기 때문에 원본인 영어 단어의 뜻을 제대로 파악하는 것이 중요하다.
갑자기 분위기가 외국어 영역이 된 것 같지만, 필자는 개인적으로 이런 과정 또한 중요하다고 생각한다. 이 과정을 통해 왜 동기라는 단어가 상황에 따라 다른 의미를 가질 수 있는지 알 수 있기 때문이다.
 암기하지말고 이해하자
암기하지말고 이해하자
먼저 동기(同期)라는 단어의 한자를 보면 같을 동(同), 기약할 기(期)를 사용하고 있으며, 일반적으로 우리가 입사 동기, 군대 동기 등을 이야기 할 때 쓰는 동기와 같은 단어다. 이 단어의 한자만 보면 “같은 기간” 또는 “같은 주기”라는 뜻이다. 역시 우리가 일반적으로 사용하는 동기화의 의미랑은 조금 다른 것 같다.
우리가 아이폰과 아이튠즈를 동기화하는 것이 이 두 대상의 기간이나 주기를 같게 맞추는 것은 아니지 않은가? 게다가 일반적으로 한국어에서 “~화”라고 함은 앞에 붙은 단어의 의미를 그대로 가져가는 경우가 많아서 더 헷갈린다.
하지만 사실 우리가 동기의 번역으로 많이 사용하는 “Synchronous”는 살짝 다른 뉘앙스를 가지고 있다.
synchronous [adjective]
: happening, existing, or arising at precisely the same time
자, 일단 Synchronous는 동기와 다르게 형용사다. 그래서 사실 한국어로 정확히 번역하면 “동기적인”과 같은 뜻이 되어야 하지만, 한국어로 형용사를 단독으로 사용하는 경우는 별로 없기 때문에 그냥 편의상 명사로 번역하는 것 같다. 그러나 이런 과정에서 한국어 단어와 영어 단어의 뉘앙스가 달라지는 경우가 발생한다.
그리고 의미를 보면 “정확히 같은 시간에 발생, 존재하는 것”이라고 한다. 그리고 이 단어는 형용사이기 때문에 무엇이 정확하게 같은 시간에 발생하는지는 적혀있지 않다. 그럼 이제 동기화를 의미하는 명사인 “Synchronization”의 사전적 의미를 한번 살펴보자.
synchronization
: the state of being synchronous
Synchronization은 “Synchronous한 상태”라고 한다. 즉, 동기와 동기화는 근본적으로 같은 뜻이라는 말이다. 같은 단어를 공유하는 이 두 단어가 한국어로 변형되며 다른 뜻이 되는 것은 영어를 한국어로 번역하는 과정에서 영어 특유의 뉘앙스를 제대로 표현하기가 어렵기 때문에 발생하는 문제이다.
게다가 이 단어들의 원형인 “Synchro”는 단어 자체가 뜻을 의미하는 변태적인 단어이기 때문에 한국어로 번역하기도 쉽지 않다. (한국어로 치면 “애매하다”같은 느낌이다. 이런건 반대로 영어로 번역하기 쉽지 않다.)
Synchronize, Synchronization, Synchronous 등 Synchro를 공유하는 이 단어들이 공통적으로 가지는 뉘앙스는 바로 “동시에 똑같이 진행되는 느낌”이다. 그것이 상태이든 동작이든 사건이든 동시에 똑같이 진행되는 느낌을 말하는 것이다.
 대표적인 싱크로의 예
대표적인 싱크로의 예
즉, 아이폰과 아이튠즈의 상태를 동일하게 만드는 것은 작업이 끝남과 동시에 아이폰과 아이튠즈가 같은 상태가 되므로 Synchronous한 상태가 된 것이고, 일반적으로 컴퓨터 공학에서 이야기하는 동기의 해석인 동시에 발생하는 사건 또한 Synchronous한 사건이라고 할 수 있는 것이다.
심지어 이 단어들의 어원인 “Syn-”은 단순히 “Together”라는 의미를 내포하는 단어이기 때문에 이런 상황에서도 사용할 수 있다.
He and I are out of sync in everything
그와 나는 모든 면에서 맞지 않는다
이렇게 한국어로 직역하기 어려운 단어는 뉘앙스를 통해서 뜻을 이해하는 편이 더 좋다. 교수님들이나 과학자들이 한국어로 말하는 중간에 영어 단어를 섞어가면서 사용하는 것은 이런 이유도 있다고 생각한다. 사실 한국어의 동기라는 의미에만 초점을 맞추면 Synchro에서 변형된 단어들 간의 공통점을 연상하기가 쉽지 않다.
다시 정리하자면, “Synchro-”를 사용하는 단어들은 모두 “동시에 똑같이 진행되는 느낌”의 뉘앙스를 가지는 단어이다. 결국 우리가 상태의 통일을 의미하는 동기화든 컴퓨터 공학에서 말하는 동시에 발생한 사건이든 모두 같은 뉘앙스를 가지고 있다는 것이다.
컴퓨터 공학에서의 동기
많은 포스팅에서 동기의 의미를 설명할 때 현재 작업의 요청과 응답이 동시에 발생하는 것으로 설명하고 있지만, 필자는 이 “동시”라는 단어가 가지는 의미와 다르게 요청과 응답 사이에는 일정한 시간이 존재할 수 밖에 없기 때문에 뭔가 모순이 느껴진다고 생각했다.
사실 동시라는 단어는 동시다발적에서의 용법과 같이 반드시 찰나의 순간만을 의미하는 것이 아니기 때문에 이렇게 설명할 수도 있긴 하지만, 일반적인 동시라는 단어의 용법을 생각해보면 직관적이지 않다고 생각한다.
그래서 필자는 동시에 발생하는 것은 현재 작업의 요청과 응답이 아니라 “현재 작업의 응답과 다음 작업의 요청”이라고 설명하는 게 더 맞지 않나 싶다. (애초에 Synchronous는 형용사라 주어가 없다)
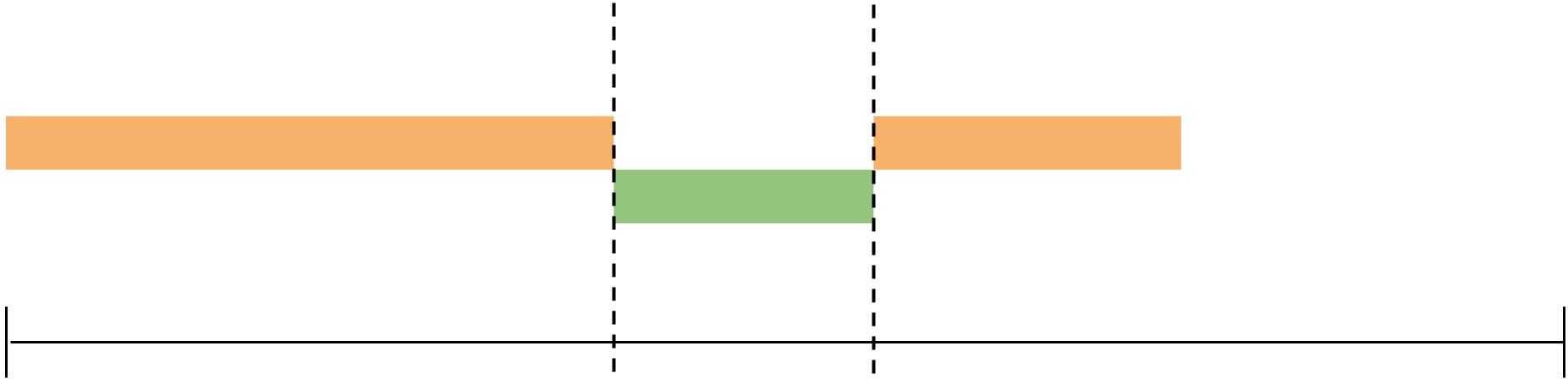 동기 방식은 현재 작업의 응답과 다음 작업의 요청의 타이밍을 맞추는 방식이다
동기 방식은 현재 작업의 응답과 다음 작업의 요청의 타이밍을 맞추는 방식이다
즉, 현재 작업의 응답이 발생함과 동시에 다음 작업을 요청한다는 것은 작업이 “어떠한 순서를 가지고 진행된다는 것”을 의미한다. 그리고 이 응답이라는 것도 사실 귀에 붙히면 귀걸이고 코에 붙히면 코걸이로, 네트워크 모델에서는 서버의 응답일 수도 있고 I/O 모델에서는 프로세스 제어권의 반납일 수도 있다.
그럼 먼저 우리가 가장 흔하게 접할 수 있는 동기 방식의 예를 한번 보자.
동기 방식 + 블록킹 방식
우리가 가장 흔하게 접하는 동기 방식의 예는 바로 동기 & 블록킹 방식이다. 동기 방식이기 때문에 작업의 흐름도 순차적으로 진행되는 것이 보장되고, 블록킹 방식이기 때문에 어떠한 작업이 진행 중일 때는 다른 작업을 동시에 진행할 수가 없다.
function employee () {
for (let i = 1; i < 101; i++) {
console.log(`직원: 인형 눈알 붙히기 ${i}번 수행`);
}
}
function boss () {
console.log('사장: 출근');
employee();
console.log('사장: 퇴근');
}
boss();사장: 출근
직원: 인형 눈알 붙히기 1번 수행
직원: 인형 눈알 붙히기 2번 수행
...
직원: 인형 눈알 붙히기 100번 수행
사장: 퇴근이 코드를 보면 우리는 자연스럽게 이 작업들이 순서를 가지고 진행될 것이라는 것을 알 수 있다. 내부적으로는 하나의 콜 스택에 작업을 넣고 LIFO(Last In First Out)으로 진행되기 때문이라는 것을 알고 있지만, 여기서는 그런 내부 로직보다는 그냥 작업이 순서대로 진행된다는 것이라는 것에만 집중하자.
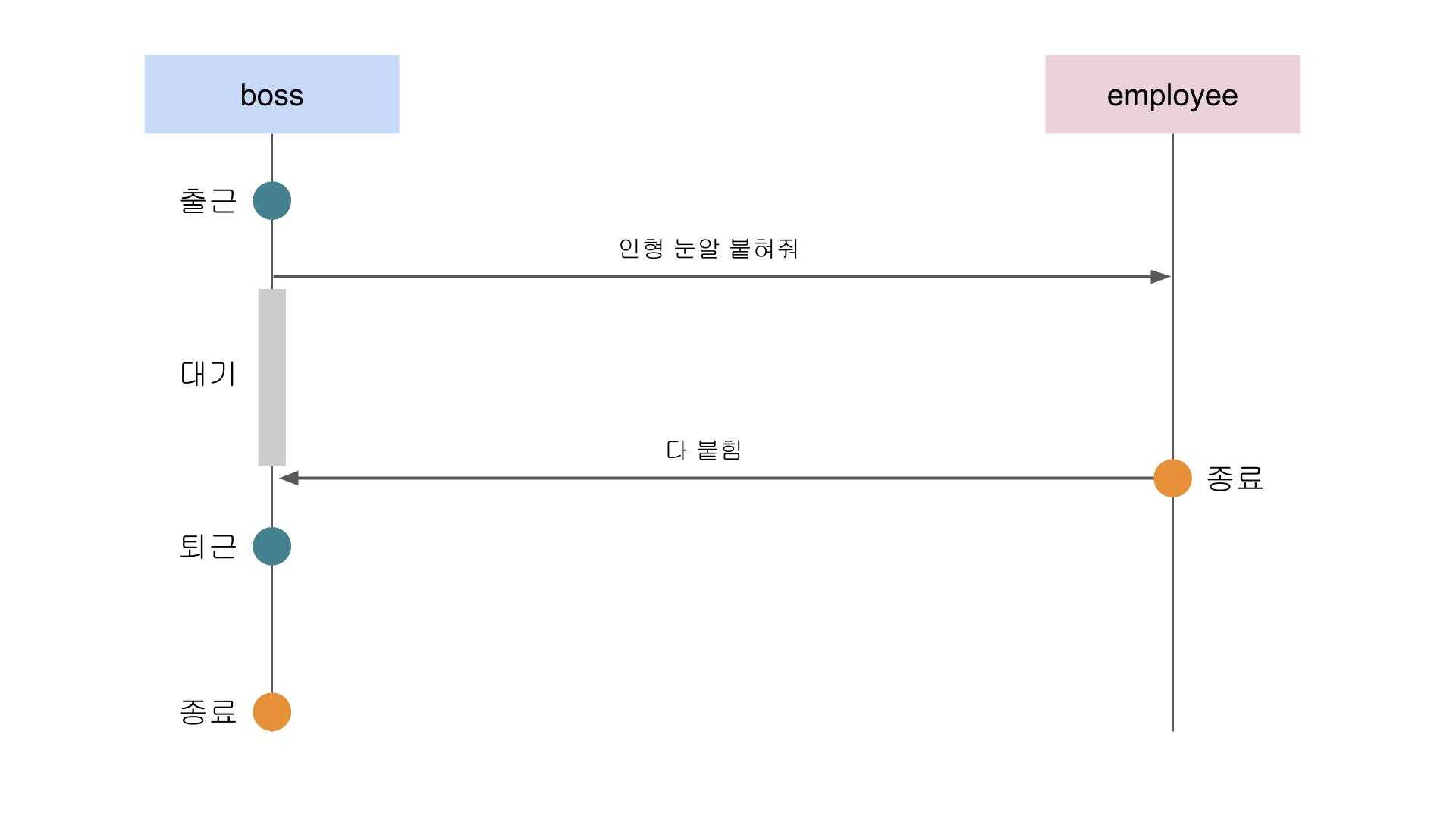 모든 인형의 눈알을 다 붙히기 전까지 퇴근은 없다
모든 인형의 눈알을 다 붙히기 전까지 퇴근은 없다
상위 프로세스인 boss 함수는 출근 작업을 수행한 뒤 하위 프로세스인 employee 함수에게 인형 눈알 붙히기 작업을 요청하고 있고, 이 인형 눈알 붙히기 작업이 완료되고나서야 boss 함수는 퇴근 작업을 수행한다.
쉽게 말해서 작업을 시킨 놈인 상위 프로세스는 작업을 하는 놈인 하위 프로세스가 종료될 때까지 절대 퇴근할 수 없다는 것이다. 이 예제와 같이 동기 방식과 블록킹 방식을 함께 사용하는 매커니즘은 일반적으로 사람들이 동기 방식이라고 하면 가장 먼저 떠올리는 방식이고 직관적으로 이해하기도 쉬운 편이다.
그렇다면 이 예제와 같이 동기적인 작업의 흐름을 유지하면서 employee 함수가 인형의 눈알을 붙히는 동안 boss 함수가 다른 일을 할 수도 있을까?
동기 방식 + 논블록킹 방식
물론 할 수 있다. 뭐가 어찌됐건 동기라는 것은 작업들이 순차적인 흐름을 가지고 있다는 것을 의미하기 때문에 이 전제만 지켜진다면 나머지는 어떻게 지지고 볶든 간에 동기 방식이라는 것은 변하지 않기 때문이다. 그래서 동기 === 블록킹이라고 말할 수 없는 것이다.
JavaScript의 제너레이터를 사용하면 작업의 순서를 지키면서도 상위 프로세스가 다른 작업을 하도록 만들 수 있다.
function* employee () {
for (let i = 1; i < 101; i++) {
console.log(`직원: 인형 눈알 붙히기 ${i}번 수행`);
yield;
}
return;
}
function boss () {
console.log('사장: 출근');
const generator = employee();
let result = {};
while (!result.done) {
result = generator.next();
console.log(`사장: 유튜브 시청...`);
}
console.log('사장: 퇴근');
}
boss();사장: 출근
직원: 인형 깔알 붙히기 1번 수행
사장: 유튜브 시청...
직원: 인형 눈알 붙히기 2번 수행
사장: 유튜브 시청...
...
직원: 인형 눈알 붙히기 100번 수행
사장: 유튜브 시청...
사장: 퇴근이 예제를 보면 상위 프로세스인 boss 함수는 출근한 후 하위 프로세스인 employee를 호출하여 인형 눈알 붙히기 작업을 시키고 주기적으로 이 작업이 끝났는지를 검사하고 있다.
그리고 아직 작업이 끝나지 않았다면 자신 또한 열심히 유튜브 시청을 수행하는 것을 볼 수 있다. 이 코드는 분명히 동기적인 흐름을 가지고 진행하고 있지만 boss 함수 또한 중간중간 자신의 작업을 수행하고 있으므로 블록킹이 아니라 논블록킹 방식을 사용하고 있는 것이다.
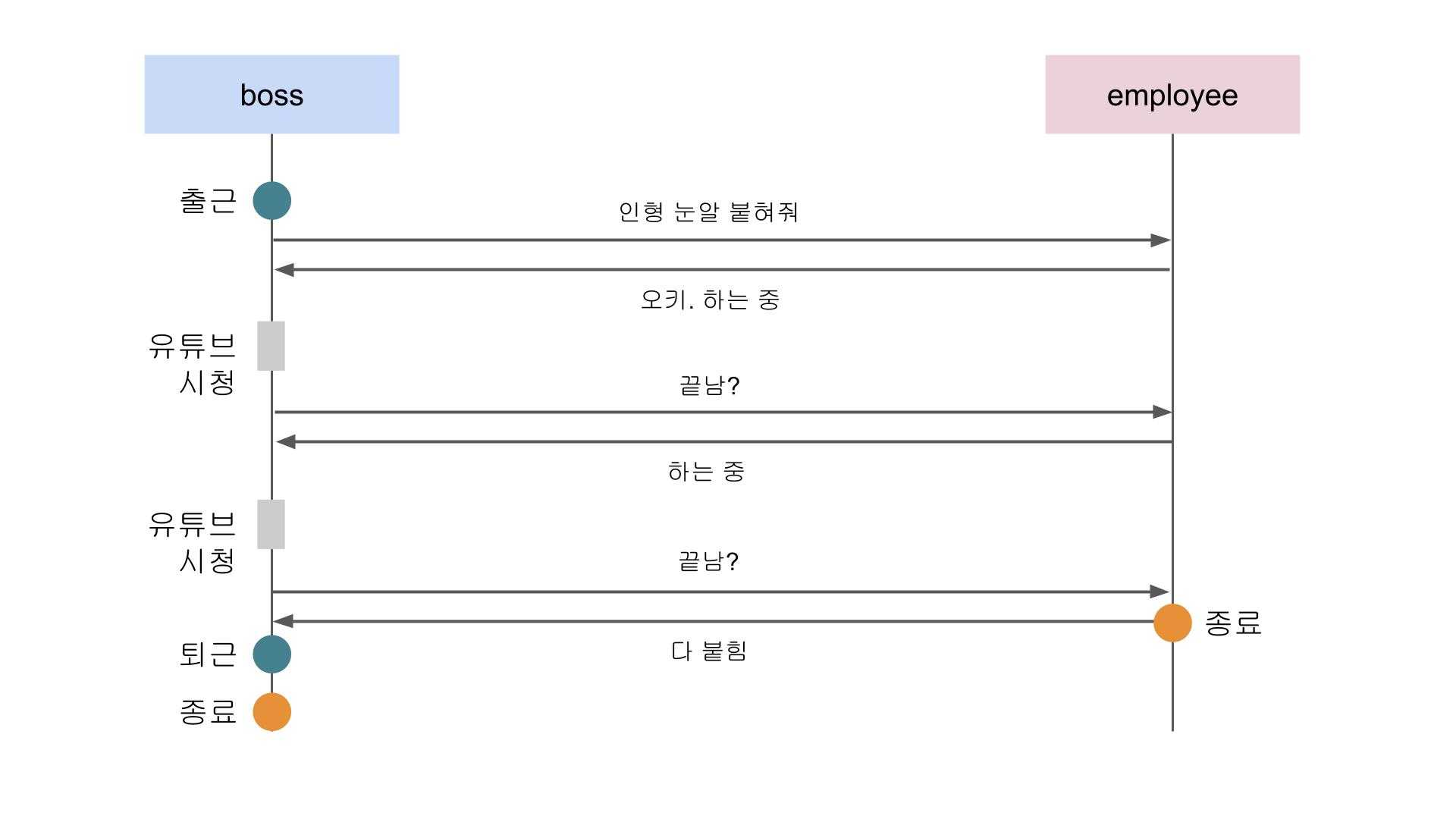 니가 일하는 동안 난 짬짬히 유튜브를 보겠다
니가 일하는 동안 난 짬짬히 유튜브를 보겠다
이 예제에서도 동기 & 블록킹 방식과 마찬가지로 boss 함수는 employee 함수의 작업이 끝나기 전까지는 절대 퇴근할 수 없다. 작업의 순서가 지켜지고 있는 것이다. 즉, 동기 방식이라는 것은 작업의 순차적인 흐름만 지켜진다면 블록킹이든 논블록킹이든 아무 상관이 없다고 할 수 있다.
컴퓨터 공학에서의 비동기
필자는 동기 방식을 현재 작업의 응답과 다음 작업의 요청의 타이밍이 일치하는 것이라고 이야기 했다. 비동기 방식은 말 그대로 동기 방식이 아니라는 의미이기 때문에 반대로 생각하면 된다. 즉, 현재 작업의 응답과 다음 작업의 요청의 타이밍이 일치하지 않아도 되는 것이다.
 작업을 지시하고나면 그 작업이 언제 끝나는 지는 신경쓰지않는다.
작업을 지시하고나면 그 작업이 언제 끝나는 지는 신경쓰지않는다.
동기 방식은 상위 프로세스가 하위 프로세스에게 작업을 지시할 때 작업의 종료 시점을 알고 있어야한다. 하위 프로세스의 작업이 완료되어 결과물을 뱉어내든 혹은 작업이 아직 진행 중이든 작업의 종료 시점은 항상 작업을 시킨 놈인 상위 프로세스가 신경쓰고있다.
하지만 비동기 방식은 다르다. 상위 프로세스는 작업을 일단 지시했으면 그 다음부터는 작업이 진행 중이든 종료가 되었든 신경쓰지않는다. 동기 방식을 설명했을 때와 마찬가지로 이때 상위 프로세스가 자신의 작업을 할 수 있냐 없냐는 별개의 문제이다.
또한 상위 프로세스가 하위 프로세스의 작업 종료 여부를 신경쓰지 않기 때문에 작업의 종료가 순차적으로 이루어지는 것을 보장하지 않는다. 그럼 먼저, 우리에게 익숙한 방식인 비동기 & 논블로킹 방식부터 한번 살펴보자.
비동기 방식 + 논블로킹 방식
비동기 방식과 논블로킹 방식을 조합한 방법은 우리에게 굉장히 익숙한 방식이다. 비동기 방식이기 때문에 상위 프로세스는 하위 프로세스의 작업 완료 여부를 따로 신경쓰지 않는다. 이후 하위 프로세스의 작업이 종료되면 스스로 상위 프로세스에게 보고를 하든 아니면 다른 프로세스에게 일을 맡기든 할 것이다.
그리고 논블로킹 방식이기 때문에 상위 프로세스는 하위 프로세스에게 일을 맡기고 자신의 작업을 계속 수행할 수도 있다.
function employee (maxDollCount = 1, callback) {
let dollCount = 0;
const interval = setInterval(() => {
if (dollCount > maxDollCount) {
callback();
clearInterval(interval);
}
dollCount++;
console.log(`직원: 인형 눈알 붙히기 ${dollCount}번 수행`);
}, 10);
}
function boss () {
console.log('사장: 출근');
employee(100, () => console.log('직원: 눈알 결산 보고'));
console.log('사장: 퇴근');
}
boss();사장: 출근
사장: 퇴근
직원: 인형 눈알 붙히기 1번 수행
직원: 인형 눈알 붙히기 2번 수행
...
직원: 인형 눈알 붙히기 100번 수행
직원: 눈알 결산 보고이 예제를 보면 boss 함수는 employee 함수에게 인형 눈알 100개를 붙히라고 지시한 후 자신은 바로 퇴근해버렸다.
상위 프로세스인 boss 함수는 employee 함수의 작업이 언제 끝나는지는 관심이 없으며 작업의 완료 신호는 콜백으로 넘겨진 눈알 결산 보고 작업이 대신 받아서 처리하고 있다.
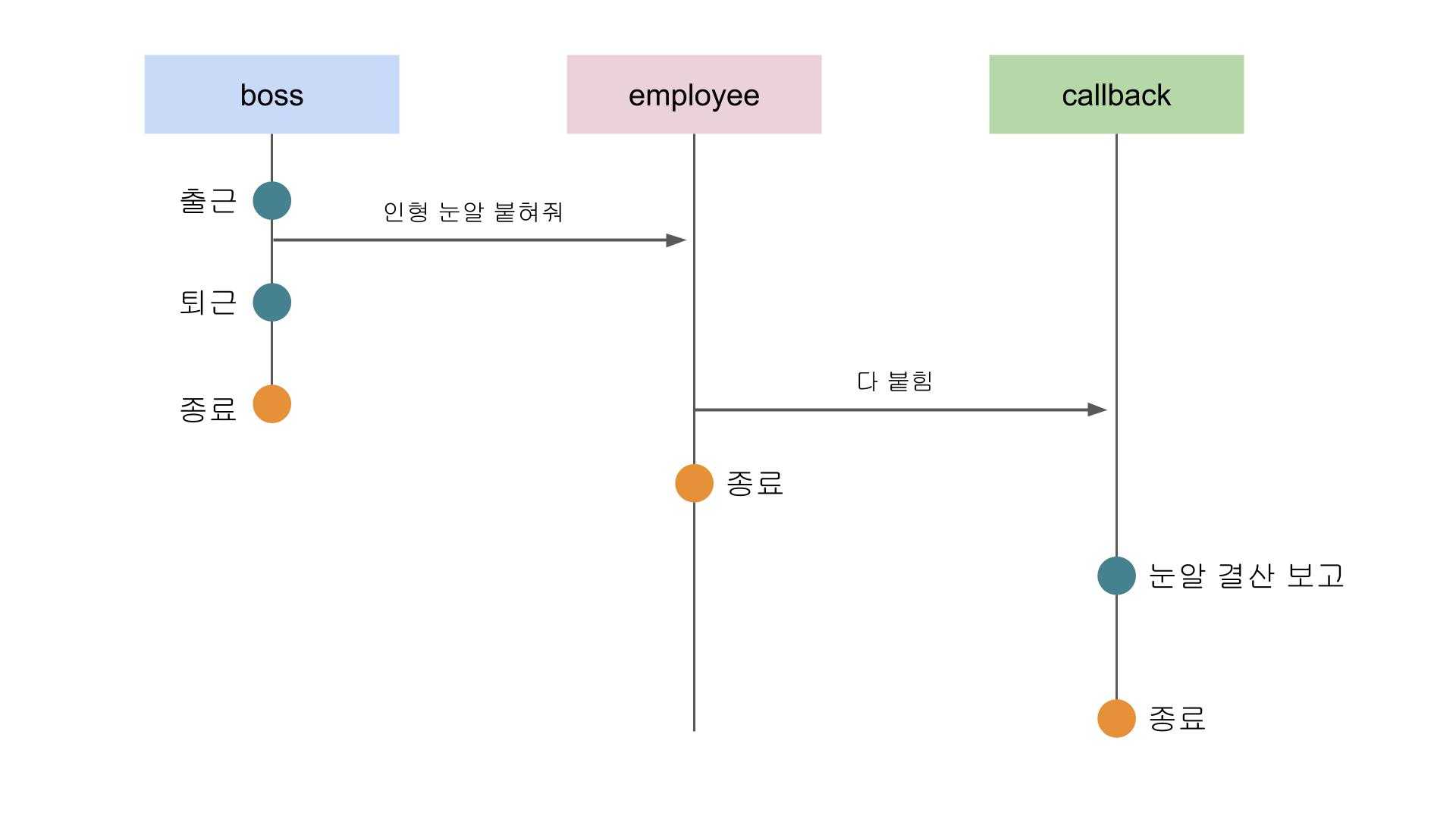 사장님은 작업만 지시하고 바로 퇴근하신다
사장님은 작업만 지시하고 바로 퇴근하신다
비동기 & 논블로킹 방식은 여러 개의 작업을 동시에 처리할 수 있는 부분에서 효율적이라고 할 수 있지만, 너무 복잡하게 얽힌 비동기 처리 때문에 개발자가 어플리케이션의 흐름을 읽기 어려워지는 등의 문제가 있을 수 있다. JavaScript에서 Promise나 async/await와 같은 문법을 사용하는 이유도 이런 비동기 처리의 흐름을 좀 더 명확하게 인지하고자 하는 노력인 것이다.
또한 NodeJS의 이벤트 루프와 같이 비동기 방식도 내부 구현을 뜯어보면 동기적인 패턴이 포함되어있기 때문에 남발하게되면 어딘가에 병목이 생길 수도 있다.
비동기 방식 + 블로킹 방식
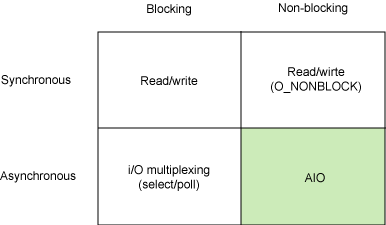
그럼 이제 마지막으로, 평소에 접하기 힘든 개념인 비동기 & 블로킹을 살펴보자. 이 방식은 일반적인 어플리케이션 레이어에서는 자주 사용되지 않고 Linux와 Unix 운영체제의 I/O 다중화 모델 정도의 저레벨에서 사용되고 있다. 그래서 지금까지 예제로 사용하던 사장님과 직원은 이제 그만 퇴근시켜주고 설명을 진행할 것이다.
일단 이 개념은 얼핏 들으면 비효율적이기만 할 수도 있다. 비동기 방식의 장점은 하위 프로세스의 작업이 끝나는 것을 기다리지 않음으로써 여러 개의 작업을 동시에 처리할 수 있다는 것인데, 프로세스가 블록킹되어버려서 유휴 상태에 빠진다면 아무 것도 처리할 수 없기 때문이다.
하지만 이 개념이 나오게 된 이유는 다음과 같다.
- 동기 & 블록킹 I/O의 경우 직관적이나, 여러 개의 I/O를 동시에 처리할 수 없다.
- 논블록킹 I/O는 프로세스들의 작업을 컨트롤하는 것이 까다롭다. (대부분 이런 저레벨 프로그램은 C로 짠다. JS나 Python 같은 걸 생각하면 안된다.)
- 그렇다고 동기 & 블록킹 I/O와 멀티 프로세싱이나 쓰레딩을 결합해서 쓰자니 자원 문제도 있고 프로세스/쓰레드 간 통신이나 동기화가 빡셈
그래서 나온 개념이 바로 “그럼 그냥 프로세스를 블록킹해놓고 비동기로 여러 개의 I/O를 다중화해서 받아버리는 놈을 만들면 어때?”인 것이다. 즉, 직관적인 코드의 흐름을 유지하면서도 작업을 동시에 처리하겠다는 것이다.
참고로 이 내용은 IBM에서 2006년에 작성한 Boost application performance using asynchronous I/O이라는 포스팅에도 소개되어 있다.
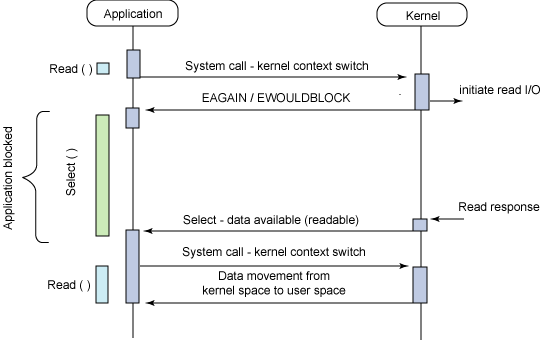
비동기 + 블록 방식의 워크 플로우
위 그림을 보면 중간에 select()라는 함수가 있는데, 이 친구가 바로 프로세스를 블록킹함과 동시에 여러 개의 I/O를 받아서 처리하는 역할을 한다. 이 함수는 C언어의 API로 제공되고 있으며, 그냥 include <sys/select.h>와 같이 헤더를 가져와서 쓰면 된다.
int select (int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);이때 nfds는 감시할 파일의 개수를, fd_set 구조체들은 각각 읽을 데이터, 쓰여진 데이터, 예외처리가 발생한 것을 감시할 파일 목록이다. 이때 fd...는 File Descriptor의 약자이며, 파일을 감시하고 있다가 해당 I/O가 발생하면 자신이 가지고 있는 비트 배열 구조체의 해당 값을 1로 변경한다.
[0, 0, 1, 0, 0, 0, 0, 0]
// 파일 목록 중 3번째 파일에 변경사항이 있다면 FD의 비트 배열 구조체가 변경된다그리고 timeval 구조체인 timeout 인자는 감시할 시간을 의미한다. 즉, 이 timeout 인자에 넘겨준 시간 동안 상위 프로세스를 블록킹하면서 자신이 넘겨받은 파일 목록을 계속 감시하고 있는 것이다. 그리고 감시하고 있는 동안 파일에 읽기, 쓰기, 예외가 발생하면 select 함수가 종료될 때 자신이 감시하던 있는 파일들 중 해당 변경사항이 발생한, 즉 처리해야할 파일의 개수를 반환한다.
대충 이 정도가 비동기 & 블록 방식의 대표적인 예인 select 함수가 작동하는 방식이다. 정리하자면 일정 시간동안 프로세스를 멈춰놓고 자신이 감시하고 있는 파일들에서 I/O가 발생하는지를 감시하는 것이다. 그리고 일정 시간이 지나면 함수가 종료되며 그동안 감시했던 파일들의 I/O 결과를 반환하고 프로세스의 블록킹이 풀린다.
이 방식은 블록킹 방식으로 진행되기 때문에 개발자에게도 직관적으로 다가오고, 비동기 방식이기 때문에 여러 개의 I/O를 동시에 감시하며 처리할 수 있다. 하지만 성능이 그렇게 좋은 편은 아니므로 IBM에서는 높은 성능이 필요한 어플리케이션에서는 되도록 쓰지 말라고 한다.
마치며
필자는 대학교 때 네트워크 과목을 수강하며 동기에 대한 개념을 처음 배웠었는데, 사실 그때는 굉장히 단편적인 내용만을 알고 있었다. 단순히 두 디바이스간의 클럭과 일정 크기의 프레임을 맞추어 통신하는 것이 동기식 통신이라는 것 정도?
하지만 개발자로 일을 하면서 공부를 더 하다보니까 동기식 I/O, 동기식 프로그래밍 등 동기에 대한 다른 개념들을 계속 해서 접하게 되었는데, 서문에서 이야기했듯이 누구는 동기라는 단어가 동시에 발생하는 것이라고 하고 누구는 특정한 클럭을 맞춰서 통신하는 것, 또 누구는 이전 작업이 끝날 때까지 기다리는 것이라고 하는 등 해석이 다 달라서 더 혼란스러웠다.
 아니 왜 말하는 게 다 달라...?
아니 왜 말하는 게 다 달라...?
그래서 이번 포스팅을 작성하면서 “Synchronous”라는 단어가 정확히 어떤 상태를 의미하는 것인지부터 다시 공부했었는데, 확실히 단어의 뉘앙스를 이해하고나니 왜 이렇게 다른 해석들이 나오게 되었는지 약간은 이해가 가는 것 같다. 단어 자체가 뜻을 의미하는 단어다보니 이건 그냥 해석하기 나름인것 같기도 하다.
어쨌든 다른 건 다 차치하고서라도 Synchronous라는 단어가 “동시에 똑같이 진행되는 느낌”이라는 뉘앙스를 알게 된 것이 이번 포스팅의 최대 수확이 아닐까라는 생각을 해본다.
이상으로 동기(Synchronous)는 정확히 무엇을 의미하는걸까? 포스팅을 마친다.