추상이란 무엇일까
좋은 추상화는 구현보다 어렵다

이번 포스팅에서는 추상(Abstraction)에 대한 이야기를 한번 해보려고 한다. 추상화는 비단 어플리케이션 설계 뿐만 아니라 컴퓨터 공학 전체에서 굉장히 중요한 자리를 차지하고 있는 개념이지만, 애초에 추상이라는 개념 자체도 워낙 추상적이라 이제 갓 개발을 시작한 많은 개발자들은 이 개념을 이해하는데 많은 혼란을 겪고는 한다.
이 추상이라는 개념은 복잡한 구조의 무언가를 만들어야 할 때 특히 빛을 발하는 개념이기 때문에, 거대하고 복잡한 어플리케이션을 설계할 때는 반드시 알고 있어야하는 개념이기도 하다.
필자가 예전에 작성했던 알고 보면 재밌는 객체 지향 프로그래밍, OOP 흝어보기 포스팅과 기존의 사고 방식을 깨부수는 함수형 사고 포스팅에서 간단하게 추상화에 대해 언급하기는 했지만, 추상이라는 개념이 꼭 OOP에만 국한된 개념이 아니기도 하고 포스팅의 메인 주제와는 다른 주제라 해당 포스팅들에서는 추상 자체에 대해 자세히 이야기하지 못 했던 것 같다.
많은 분들이 추상화를 “공통된 부분을 추려내는 것”이라고만 인지하고 있는 경우가 많다. 물론 엄밀히 이야기하면 틀린 말은 아니지만, 사실 이건 추상적인 무언가를 정의하기 위해 수행하는 구체적인 추상화 스킬 중 하나일 뿐이지 추상이라는 것의 본질이 무엇인지를 설명해주는 것은 아니다.
만약 이런 개념으로부터 추상을 이해하려고 한다면, 누군가가 여러분에게 “프로그래밍에서 추상화가 왜 필요해요?”와 같은 질문을 했을 때, “공통적인 부분을 뽑아내서 재사용성을 높힐 수 있습니다”와 같이 지엽적인 답변을 할 수 밖에 없게 되는 것이다. (사실 필자가 면접 때 자주 물어본다)
즉, 추상이라는 개념을 제대로 이해하기 위해서는 우선 프로그래밍에서 설명하는 추상화의 개념에서 벗어나, 본질적으로 추상이라는 것이 무엇인지, 그리고 이런 개념이 왜 필요한지에 대한 고민을 밑바닥부터 해보는 것이 중요하다.
복잡한 것을 단순하게 표현하자
자, 그렇다면 가장 근본적인 것부터 한번 고민해보도록 하자. 추상이라는 것은 도대체 무엇일까?
여러분도 아시다시피 추상이라는 용어 자체는 프로그래밍의 세계에서만 사용되는 것은 아니다. 사실 이 용어는 프로그래밍이나 수학에서도 사용되기는 하지만, 미술이나 건축에서도 많이 사용되는 용어이며, 대표적인 추상파 화가로는 그 유명한 피카소 형이 있다.
 소의 복잡한 부분을 전부 제거하고 가장 핵심적인 특징만을 나타낸 피카소의 그림
소의 복잡한 부분을 전부 제거하고 가장 핵심적인 특징만을 나타낸 피카소의 그림
이런 모습에서도 알 수 있듯이 추상화가 된 대상은 현실의 대상보다 그 대상의 본질, 조금 더 쉽게 이야기하면 각각의 디테일한 특징이 배제되어 대상 자체를 표현하는 특징들이 강화된다.
피카소가 그린 소 그림은 “소”라는 본질만 가지고 있다면, 모두 대응이 가능한 표현이다. 젖소든, 한우든, 황소든 간에 저 형태에서 크게 벗어나는 소는 없다는 이야기이다. 현실에서 이 소들은 각각 다른 모습을 가지고 있지만, 다리가 4개 달리고 머리에 뿔이 있다는, 소라는 것이 가지는 본질적인 형태에서는 크게 벗어나지 않는다.
마치 인간 개개인의 생김새, 목소리, 성격 등은 모두 다르지만, 결국 기본적으로 팔 2개, 다리 2개, 머리가 1개 달린 형태라는 것은 변하지 않는 것처럼 말이다. 이것이 바로 그 대상이 가지는 본질이다.
또한 이렇게 대상의 본질만을 표현하고 디테일한 요소들을 배제하면 표현이 단순해질 수 밖에 없다. 100개의 세세한 특징을 표현한 것보다 10개의 핵심적인 특징만을 표현한 것이 더 단순한 것은 당연하다.
 간단한 원 하나와 직선 5개로 표현했지만, 아무도 이걸 개나 고양이라고 생각하지는 않는다.
간단한 원 하나와 직선 5개로 표현했지만, 아무도 이걸 개나 고양이라고 생각하지는 않는다.이것이 바로 대상의 본질을 뽑아내어 표현한, 추상화된 대상인 것이다.
결국 추상화가 된 대상은 “어떤 복잡한 대상의 핵심적인 특징만 남기고 나머지는 제거하여 단순화시킨 것”이라고 볼 수 있다. 마치 감정, 동물, 사물과 같은 복잡한 덩어리와 의미를 가진 것들을 단순한 도형들로 구성하여 단순화시키고 핵심적인 부분만을 강조한 추상파 화가들의 그림들처럼 말이다.
그리고 이렇게 일반화된 핵심적인 특징들은 이러한 개체, 물체들의 공통적인 부분이 될 수 밖에 없다. 그래서 OOP에서 객체들의 공통점을 뽑아내어 클래스를 정의하라고 가이드하는 것이다.
만약 필자가 그린 인간 그림에서 원이 없어진다면, 여러분은 이 그림이 로켓인지, 화살표인지, 머리가 없는 인간인지 알기 어려울 것이다. 왜냐면 살아있는 인간이라면 누구나 저 위치에 머리가 있어야 하는 것이 일반적이기 때문이다. 즉, 머리의 위치와 형태는 인간이라면 누구나 다 가지고 있는 대표적인 공통점인 것이다.
 이 사진을 보고 자연스럽다고 생각하는 사람은 아마 아무도 없을 것이다
이 사진을 보고 자연스럽다고 생각하는 사람은 아마 아무도 없을 것이다
이렇게 복잡한 특성을 가진 대상이 가진 핵심적인 특징을 제외한 나머지 자잘한 것들은 모두 쳐내 단순하게 표현하는 것, 이것이 바로 추상화의 본질이다.
왜 프로그래밍에 추상화가 필요할까?
필자는 추상화라는 것이 복잡한 특성을 가진 대상이 가진 핵심적인 특징을 제외한 나머지 자잘한 것들은 모두 쳐내 단순하게 표현하는 행위라고 설명했다.
그럼 이런 행위가 프로그래밍을 할 때 도대체 왜 필요한 것일까? 우리는 피카소처럼 사물의 본질을 파악하여 예술적으로 표현하는 그런 사람들도 아닌데 말이다.
사실 이 질문에 대한 답은 매우 간단하다. 바로…
더 복잡하고 어려운 것을 만들기 위해서이다.
추상화는 더 복잡한 것을 만들 수 있게 해준다
앞서 이야기했듯 추상화를 당한 대상은 본래 자신이 가지고 있던 특징들 중 가장 핵심적인 특징만을 표현하게 되기 때문에, 매우 단순한 형태를 가지게 된다. 여기서 중요한 점은 “실제로는 복잡한 것을 단순하게 표현한다는 것”이다.
다만 미술에서 사용하는 추상적 표현은 대상의 복잡한 부분을 제거하여 추상화를 진행하지만, 산업에서의 추상적 표현은 복잡한 부분을 감춤으로써 추상화를 진행한다는 차이점이 존재한다.
즉, 구체적이고 복잡한 구현을 감추어 단순한 형태로 표현함으로써, 내가 만든 모듈이나 부품, 혹은 제품을 사용하는 사용자가 근본적인 원리를 알지 못 하더라도 대상의 기능을 활용할 수 있도록 만들어주는 것이다.
우리가 일상 속에서 사용하는 컴퓨터만 해도, 가장 기본이 되는 부품인 반도체의 원리까지 모두 이해하고 사용하는 사람은 그리 많지 않으며, 심지어는 CPU가 뭔지도 모르는 초등학생조차도 컴퓨터를 사용할 수 있다. 우리는 그냥 컴퓨터라는 개념을 “키보드, 마우스로 조작하여 모니터나 스피커를 통해 뭔가 결과를 볼 수 있는 장치” 정도로 추상화하여 이해해도 사용에는 아무 문제가 없으니, 굳이 컴퓨터의 디테일한 원리까지 모두 알 필요도, 이유도 없는 것이다.
또한 포토샵을 사용하여 사진을 보정하는 사람은 그냥 포토샵의 사용 방법 자체에만 집중하면 되지, 포토샵이라는 프로그램이 어떤 원리로 작동하는지, OS가 이 프로그램을 굴리기 위해 프로세스에 자원을 어떻게 할당하는지와 같은 내용은 전혀 몰라도 된다.
만약 포토샵을 사용하는 사람이 이런 것까지 모두 신경써야 한다면 “포토샵으로 사진을 편집한다”라는 행위 자체가 너무 어렵고 복잡해지지는 않을까?
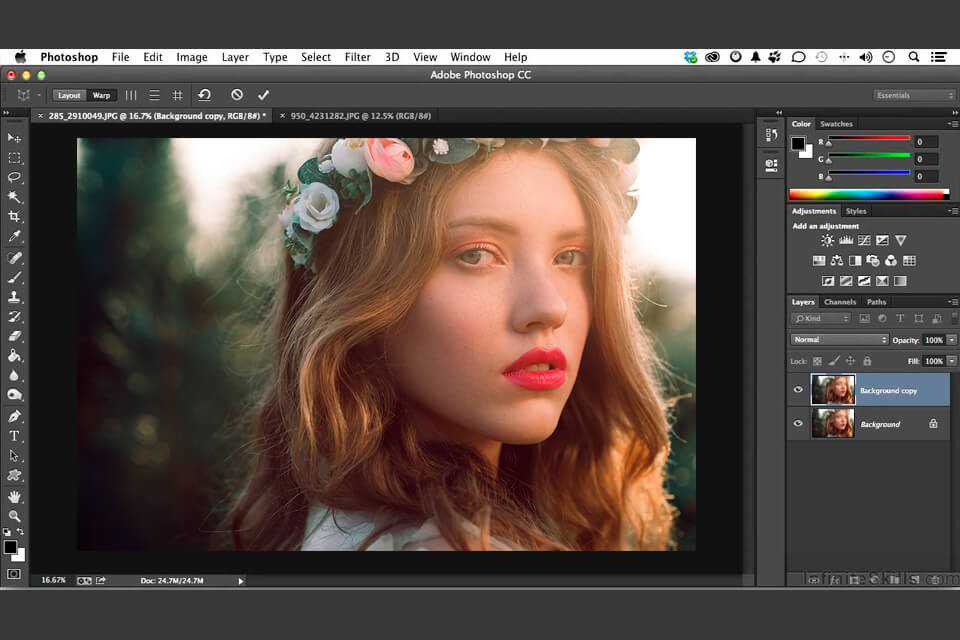 만약 포토샵으로 사진을 편집할 때 이미지 프로세싱의 모든 원리를 알고 활용해야 한다면
만약 포토샵으로 사진을 편집할 때 이미지 프로세싱의 모든 원리를 알고 활용해야 한다면인간 한 명의 리소스만으로는 너무 어려운 작업이 되어버릴 것이다.
이미 추상화의 근본적 개념은 자동차, 스마트폰, 도시 인프라 시스템, 행정처리 시스템 등 다양한 부분에서 활용되고 있으며, 평소 우리가 당연하다고 생각하고 누리고 있는 많은 것들이 내부적으로 굉장히 복잡한 로직과 인프라가 추상화된 결과물이다.
우리는 이러한 추상화 덕분에 모든 분야에 대한 방대한 지식을 쌓지 않아도 복잡한 현대 사회의 시스템을 활용할 수 있게 되었다.
수도꼭지를 돌리면 깨끗한 물이 나온다 👉 도시의 상수도 시스템이 추상화됨
동사무소에 가면 주민등록을 할 수 있다 👉 국가의 행정처리 시스템이 분업화되어 추상화됨
자동차의 액셀러레이터를 밟으면 차가 앞으로 전진한다 👉 흡기/압축/폭발/배기 과정을 다루는 ECU와 엔진의 로직이 추상화됨
이렇듯 현재 우리가 살아가는 세상은 다양한 추상 개념 위에 쌓아올려진 것이며, 복잡한 것을 단순하게 표현하는 이 개념 덕분에 사람들은 자신이 담당하는 것에만 집중하며 작업을 할 수 있게 되어 분업이 가능해지고, 기존보다 더욱 더 복잡한 것들을 만들 수 있게 된다.
반도체를 생산하는 사람은 반도체라는 개념에만, 컴퓨터를 조립하는 사람은 컴퓨터라는 개념에만, 포토샵을 개발하는 사람은 이미지 프로세싱과 프로그래밍에만, 작품을 만드는 사람은 포토샵을 활용하는 것에만 집중하면되니, 각 분야에 대한 전문성을 가진 여러 사람이 모여 기존보다 더 거대하고 복잡한 것들을 만들 수 있게 되는 것이다. 만약 이 모든 것을 한 사람이 이해해야 제품을 생산할 수 있다면, 평생에 걸쳐서 지식을 쌓아도 복잡한 제품을 높은 퀄리티로 생산해내기 쉽지 않을 것이다.
이런 추상화의 이점은 우리가 경험하는 프로그래밍에도 동일하게 적용되고 있다. 내가 만드는 소프트웨어 또한 다른 산업과 마찬가지로 전 세계의 수 많은 사람들이 기여한 여러가지 작은 모듈들의 조립품이기 때문이다.
필자와 같은 프론트엔드 개발자들은 대부분 React나 Vue같은 라이브러리/프레임워크들을 사용하여 웹 어플리케이션을 개발하는데, 이렇게 작은 프로그램들인 라이브러리나 프레임워크를 조합하여 복잡한 어플리케이션을 만드는 것은 그리 어색한 일이 아니다.
솔직히 JavaScript 엔진에 대한 자세한 동작 원리는 모르더라도, JavaScript에 대한 대략의 문법과 React라는 라이브러리에 대한 사용법만 알아도 어플리케이션을 개발하는 것이 불가능하지는 않다.
또한 예전에는 Webpack을 개발자가 직접 세팅하여 어플리케이션을 번들링하는 것이 일상적이었지만, 이제는 CRA같은 Cli나 Next.js 같은 프레임워크가 자체적으로 Webpack Configuration을 만들어주고, 심지어 이를 감춰서 추상화해버리기 때문에 최근 개발을 시작하시는 분들은 Webpack을 직접 다뤄보지 않은 분들도 계신다. (실제로 최근에는 Webpack에 대한 지식이 없어도 일반적인 어플리케이션을 개발하는 자체에는 큰 지장이 없다)
 구글에 "webpack eject"로 검색해보면
구글에 "webpack eject"로 검색해보면얼마나 많은 사람들이 추상화를 깨고 webpack을 직접 건드리는 것을 피하려고 하는지 알 수 있다.
이러한 추상화 덕분에 오늘날의 프론트엔드 개발자들은 상태와 UI를 연동하여 렌더링하고, 프로젝트를 직접 번들링하는 등의 복잡한 개념에서 해방되어 조금 더 고차원적인 부분들에 집중할 수 있게 되었고, 그로 인해 예전보다 점점 더 거대하고 복잡한 웹 클라이언트 어플리케이션을 개발할 수 있게 된 것이다.
바로 이것이 프로그래밍, 더 나아가서는 산업에서의 추상화가 우리에게 가져다주는 이점이다.
공통점을 뽑아내는 추상화 방법에서 벗어나보자
지금까지는 추상이라는 개념이 프로그래밍에 국한되지 않은 일반적인 개념이라는 것과 프로그래밍의 세계에 추상화라는 개념이 필요한 이유에 대해서 살펴봤다면, 이제는 조금 더 국지적인 부분을 살펴보도록 하자.
앞서 필자는 OOP에서 이야기하는 “구체적인 것들의 공통점을 뽑아내어 추상적인 것을 정의한다”라는 추상화의 가이드라인이 추상화의 본질을 제대로 설명하지 못 한다고 이야기했다. 이는 복잡한 무언가를 단순한 것으로 추상화를 하는 접근 방법 중 하나일 뿐이기 때문이다.
물론 이 방법이 틀렸다는 것은 아니지만, 개인적으로 필자는 이 가이드라인으로부터 추상화를 이해하려는 것을 추천하지는 않는다. 이것은 그냥 “추상화를 하기 위해 대상에 접근하는 방법 중 하나일 뿐”이며, 오히려 너무 이 방법에 얽매이게 되면 추후 어플리케이션이 진화할 방향성에 대한 상상을 제한하게 되어 변경에 열려있지 않은 설계를 만들어낼 수도 있다.
간단한 클래스를 한번 예로 들어보자.
현재의 요구사항을 너무 충실하게 반영하는 설계
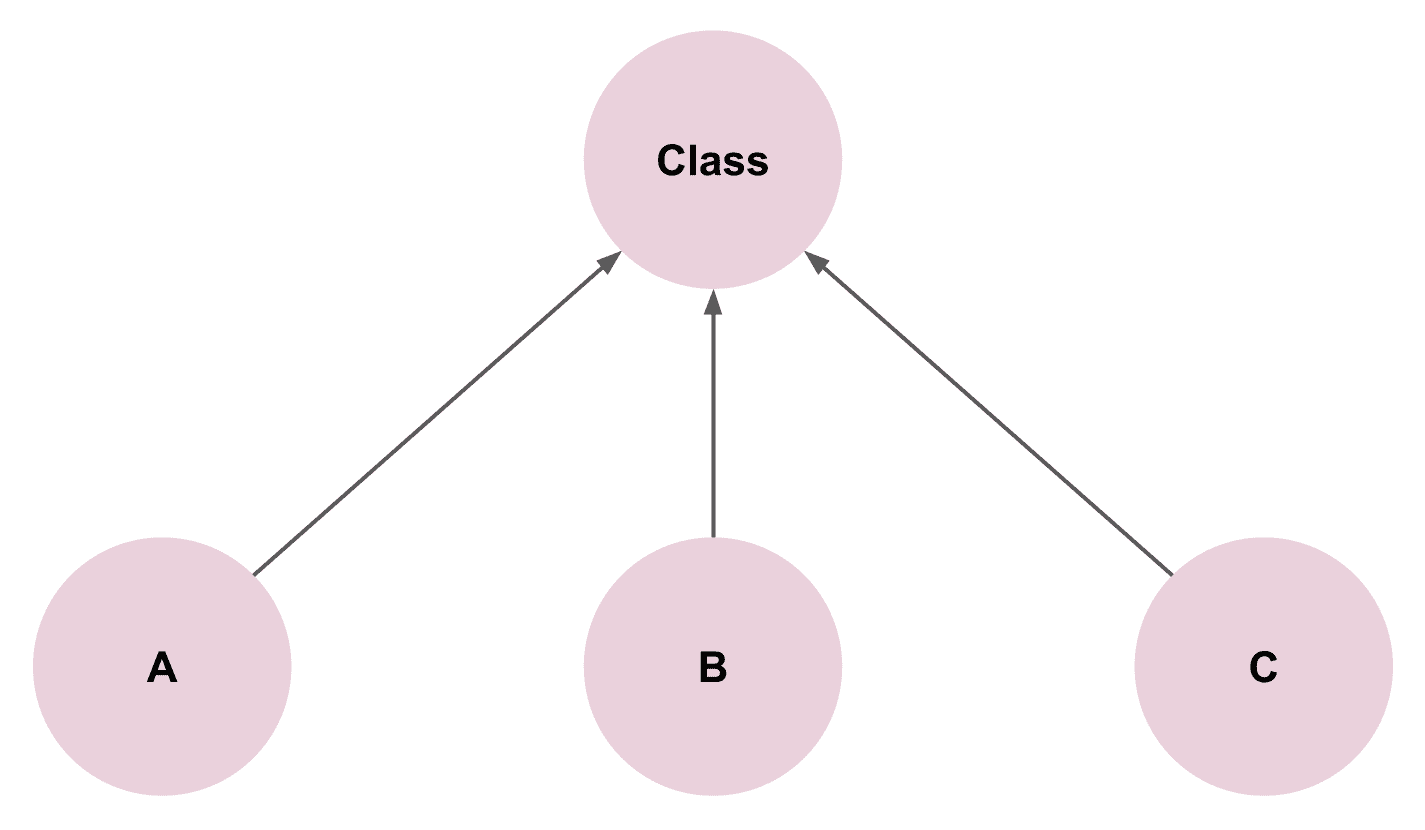
- 요구사항에는 A, B, C라는 객체가 존재한다.
- A, B, C 객체의 공통점은 분홍색의 동그라미 모양이라는 것이고, 차이점은 가운데 들어가는 글자가 다르다는 것이다.
- 분홍색 동그라미 모양 + 가운데 글자를 주입할 수 있는 클래스를 정의한다.
이렇게 정의된 클래스는 현재 제시된 요구사항의 모든 케이스를 커버할 수 있기 때문에 추상화가 잘 된 것처럼 보인다. 실제로 이 설계는 현재의 비즈니스 요구사항을 충실하게 만족시키고 있기 때문에 별다른 문제가 없다.
하지만 항상 문제는 현재의 스펙을 벗어난 추가적인 변경사항이 들어왔을 때 발생한다.
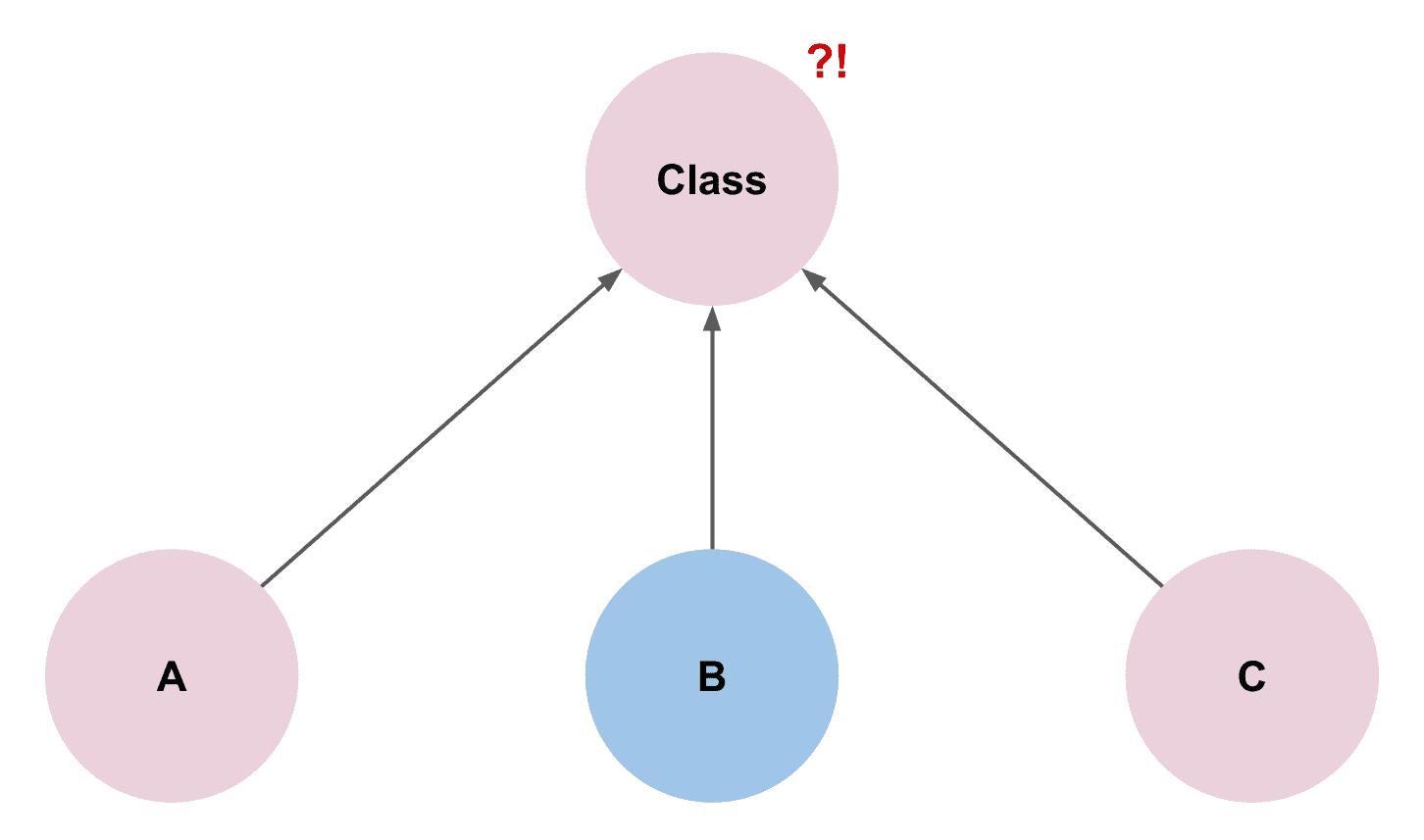 "PO/PD: 동욱님 B객체의 색을 바꿀 수 있게 해주세요"
"PO/PD: 동욱님 B객체의 색을 바꿀 수 있게 해주세요"
 요구사항을 들은 나의 심정.jpg
요구사항을 들은 나의 심정.jpg
아마 독자 여러분도 이런 경험이 많이 있을 것이라고 생각한다. 이처럼 빠르게 변화하는 비즈니스 상황 속에서 내가 개발하고 있던 어플리케이션의 스펙이 이에 따라 변경되는 것은 너무나도 자연스러운 일이며, 이런 상황은 내가 OOP를 사용하던 FP를 사용하던 패러다임과는 무관하게 항상 발생하게 된다.
사실 위 예시의 설계에서 객체의 색을 변경할 수 있게 만들어주는 것은 간단한 작업이라 크게 문제가 없어보일 수도 있지만, 현실 세계에서 우리에게 들어오는 변경사항이 이 정도 수준이 아니라는 것은 다른 누구보다 독자 여러분이 더 잘 아실거라고 생각한다. (빌딩을 1cm만 오른쪽으로 옮겨주…읍읍)
좋은 코드라는 것을 정의할 수 있는 조건은 여러 개가 있지만, 그 중 대표적인 조건 중 하나는 요구사항이 변경되더라도 기존의 설계를 최대한 건드리지 않고 확장할 수 있는 “변경에 열린 코드”이다. 비즈니스 요구사항은 시장의 상황에 따라 변화무쌍하게 변할 수 밖에 없는데, 코드가 이 속도를 따라가지 못 한다면 결국 제대로 된 비즈니스 임팩트를 낼 수 없기 때문이다.
하지만 위 예시의 코드는 미래의 변경사항을 대처하지 못 했고, 결국 클래스에 수정을 가해야 하는 상황을 만들어냈다. 또한 추상 표현을 담당하는 클래스라는 개념의 특성 상 여기저기서 재사용되고 있을 가능성도 높으니, 이 클래스만 수정해서 끝날 일도 아닐 것이다.
왜 이렇게 되었을까?
왜 이 클래스는 변경에 열린 설계가 되지 못 했을까? 여러가지 이유가 있겠지만, 필자는 “현재의 요구사항에 충실한 설계를 했기 때문”이라고 생각한다.
물론 우리는 비즈니스 요구사항에 맞춰 제품을 개발하는 사람들이니 현재의 요구사항에 맞춰 설계를 하는 것은 당연한 일이겠지만, 개발자라면 누구든 미래지향적인 설계, 추후 새로운 기능이 얼마나 붙든 기존 코드를 최대한 재사용할 수 있는 확장성있고 변경에 열린 설계를 하고 싶어한다.
하지만 현재 나에게 주어진 기능의 스펙에서부터 공통점을 추려내는 방식으로 추상화를 진행하게된다면, 추상화된 대상 조차도 “당장 현재의 요구사항”만을 투영하고 있도록 설계될 가능성이 높아진다.
 애초에 나에게 주어진 재료인 요구사항을 기반으로 추상화를 하게 되니,
애초에 나에게 주어진 재료인 요구사항을 기반으로 추상화를 하게 되니,추상화된 개념도 자연스레 현재의 요구사항만을 반영하게 되기 쉽다
물론 디테일에서부터 추상화를 진행해도 얼마든지 변경에 열린 설계를 만들어낼 수는 있다. 흔히 객체지향에서 이야기하는 SOLID 원칙, 더 구체적으로는 IoC, DI 같은 디자인 패턴들이 바로 그런 설계를 하기 위한 방법이라고 할 수 있다.
그러나 이런 사고 과정을 통해 추상화를 하는 상황에서 변경에 열린 설계를 하려면, 개발자의 짬바에 의존한 미래 예측력과 비즈니스 도메인 지식이 필요할 수 밖에 없다. 왜냐하면 어디가 얼마나 자주 바뀔 것 같은지에 대한 감이 있어야 그 부분을 유연하게 설계해놓을 수 있기 때문이다.
심지어 일반적으로 추상화에 대한 설명을 할 때 따라오는 “객체들의 공통점을 뽑아라”이라는 문장에는 이런 디자인 패턴에 대한 이야기가 담겨있지 않으니, 개발자가 이런 원칙들을 알아서 공부하고 적재적소에 사용해야한다.
물론 짬바가 어느 정도 찬 개발자들은 “그냥 하면 되는거 아님?”이라고 생각할 수 있지만, 처음 개발을 접한 초보자 입장에서는 현재의 요구사항만 보고 “여기는 나중에 변경되기 쉬운 부분이니까 원하는 기능을 외부에서 주입할 수 있도록 설계해놔야겠다”라는 생각을 하기가 참 쉽지 않다.
그래서 필자가 제안하고 싶은 방향은 구체적인 것에서 추상적인 것을 정의하는 방향이 아닌, 반대로 추상적인 것을 먼저 떠올려 보는 방법이다.
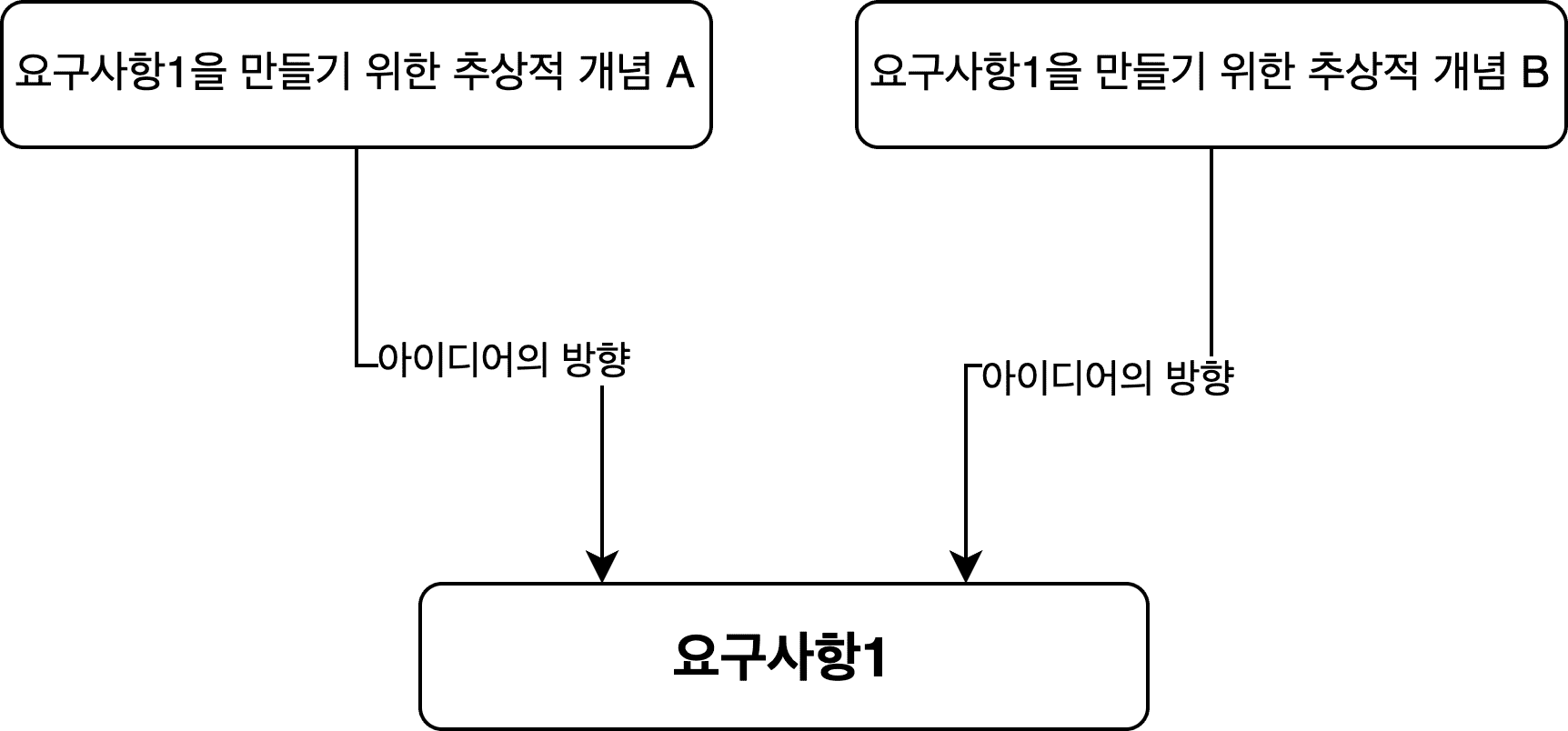 구체적인 요구사항을 달성하기 위해 필요한 재료가 무엇인지를 고민해보자
구체적인 요구사항을 달성하기 위해 필요한 재료가 무엇인지를 고민해보자
추상적인 것들을 합성하여 구체적인 것을 만들기
기존의 추상화 방법에 익숙한 분이라면, 구체적인 것보다 추상적인 것을 먼저 정의해보자고 했을 때 감이 잘 안 오실 수도 있지만, 사실 이 개념은 그렇게 새로운 것도 아니고 이상한 것도 아니다.
앞서 필자는 추상이라는 개념을 사용하면 복잡한 것들을 감추어 단순하게 보이도록 만들 수 있고, 이런 추상의 효과 덕분에 우리가 복잡한 현대 사회를 구성하는 모든 지식을 알지 못 하더라도 현대 사회의 문물들을 충분히 이용하면서 살아갈 수 있다고 이야기했다.
어플리케이션 설계 또한 마찬가지이다. 즉, 구체적인 객체 또는 구현체들의 공통점이 무엇이고 이런 공통점을 어떻게 추상화할지에 대한 고민보다는, 구체적인 구현 중에서 어떤 부분을 부품처럼 따로 나누어 포장하고, 또 이 부품들을 어떤 방식으로 조립하게 만들어줘야 내 코드를 사용하는 개발자들이 필요 이상의 맥락을 몰라도 내 코드를 편하게 사용할 수 있을 지에 대해 고민해야하는 것이다.
물론 이런 접근 방식을 사용해도 결과적으로는 구체적인 개념들의 공통적인 부분이 추상화되는 결과가 나올테니 어떻게 보면 비슷하다고 느낄 수 있지만, 공통점을 뽑아내는 방법과는 사고의 방향이 정반대라는 차이가 있다.
자, 만약 우리가 아이폰을 만들어야 하는 상황이라고 생각해보자. 객체들의 공통점을 뽑아내어 추상 개념을 정의하는 방식으로 접근하면 대략 이런 사고 흐름을 타게 될 것이다.
아이폰의 모든 기종에는 홈으로 이동할 수 있는 기능이 존재한다 (공통점)
아이폰은 홈 버튼이 있는 놈이랑 없는 놈으로 나눌 수 있지 않나? (차이점)
그럼 함수에 홈 버튼을 보이게 하거나, 안 보이게 하는 인자를 하나 추가하면 되려나? (차이점의 구현)
interface Props {
showHomeButton: boolean;
}
const IPhone = ({ showHomeButton }: Props) => {
const [isHomeScreen, setHomeScreen] = useState(false);
const moveHome = () => setHomeScreen(true);
if (showHomeButton === true) {
return <HomeButton onClick={moveHome} />
} else {
return <HomeGesture onSwipeUp={moveHome} />
}
}어차피 추상적인 무언가를 조합해서 복잡하고 구체적인 것을 만든다는 개념 자체는 변하지 않는다.
뭐 대충 이런 모양이 되지 않을까? 얼핏 보면 현재의 요구 사항을 잘 맞추긴 했다. 아이폰은 기종에 따라 홈 버튼이 존재하는 구형 기종과 홈 버튼이 없는 신형 기종이 존재하기 때문이다.
하지만 만약 나중에 (그럴리 없겠지만) 홈 버튼을 다이얼로 만든 아이폰이 출시된다면 어떻게 될까? 이 아이폰은 홈 버튼을 터치하거나 누른다는 개념이 없고 그저 돌릴 수만 있다.
당연히 현재 우리의 함수는 그런 개념까지 생각하지 못 한 상태로 작성되었으니, 이제 이 함수에 homeUIType이라는 새로운 인자를 추가하고, 의미가 없어진 showHomeButton 인자는 제거해야 할 것이다.
type IPhoneHomeButtonType = 'dial' | 'gesture' | 'button';
interface Props {
homeUIType: IPhoneHomeButtonType;
}
const IPhone = ({ homeUIType, onMoveHome }: Props) => {
const [isHomeScreen, setHomeScreen] = useState(false);
const moveHome = () => setHomeScreen(true);
switch(homeUIType) {
case 'button':
return <HomeButton onClick={moveHome} />;
case 'gesture':
return <HomeGesture onSwipeUp={moveHome} />;
case 'dial':
return <HomeDial onChange={moveHome} />;
}
}단지 홈으로 이동하는 동작의 트리거 종류가 하나 추가되었을 뿐인데도 함수의 인자와 내부 로직이 전부 변경되었다. 게다가 함수의 인자가 변경되었으니 기존에 이 함수를 사용하고 있던 모든 곳에도 이 변경사항에 맞춰 수정을 해줘야 할 것이다.
여기까지 보신 많은 개발자 분들은 이렇게 생각하실 수도 있겠다.
 아니 처음부터 IoC로 외부에서 주입하도록 유연하게 설계하면 되는데, 누가 저렇게 개발하냐!
아니 처음부터 IoC로 외부에서 주입하도록 유연하게 설계하면 되는데, 누가 저렇게 개발하냐!
interface Props {
renderHomeUI: (moveHome: () => void) => ReactNode;
}
const IPhone = ({ renderHomeUI }: Props) => {
const [isHomeScreen, setHomeScreen] = useState();
const moveHome = () => setHomeScreen(true);
return renderHomeUI(moveHome);
}
// 애초에 외부에서 IoC 패턴으로 합성해놓으면,
// IPhone 컴포넌트 내부의 로직을 아예 변경하지 않고도 다양한 Home UI를 사용할 수 있도록 설게할 수 있다.
<IPhone renderHomeUI={(moveHome) => <HomeButton onClick={moveHome} />}>
<IPhone renderHomeUI={(moveHome) => <HomeGesture onSwipeUp={moveHome} />}>
<IPhone renderHomeUI={(moveHome) => <HomeDialog onChange={moveHome} />}>물론 필자도 그렇게 생각한다. 사실 홈으로 이동하는 기능은 “홈 버튼”과는 크게 관련이 없는 추상적인 기능이니, 홈으로 이동하는 이벤트를 호출하는 주체인 홈 버튼이라는 녀석은 스마트폰의 설계에 따라 변경될 가능성이 농후하기 때문이다.
하지만 앞서 이야기했듯이 이러한 설계에 익숙하지 않은 개발자라면 이미 자신이 알고 있는 아이폰의 기능이나 현재 주어진 요구사항이라는 개념에 매몰되어 홈 버튼이라는 녀석이 굉장히 변경되기 쉬운 녀석이라는 사실을 인지하기 어려울 수도 있고, 변경될 가능성이 낮은 홈으로 이동하는 기능과 변경될 가능성이 높은 홈 버튼이 마치 하나의 개념인 것처럼 오인식하여 결합도가 높은 설계를 하게 되기가 쉽다.
아마 처음부터 “엥 이건 외부에서 주입해야 할 것 같은데…?”라고 생각하신 분들은 과거에 직접 경험했던 여러 삽질을 통해서 해당 부분이 자주 변경될 것 같다는 인사이트를 쌓으셨기 때문에 문제의식을 가지게 되셨을거라고 생각한다. 쉽게 말해 짬바다.
그러나 이런 인사이트가 부족한 초보 개발자들은 일종의 공식처럼 구체적인 것들의 공통점을 뽑아내어 추상화를 진행할 수 밖에 없고, 이후 비즈니스가 변화함에 따라 발생하는 이슈들을 대응할 때 주먹구구식으로 설계를 확장하게 되기 너무 쉬운 것이다.
솔직히 IoC, DI 같은 개념들은 이런 삽질을 통해 몇 번 고생을 해보다 보면 자연스럽게 공부를 통해 알게 되는 것이지, 처음부터 이런 개념을 가지고 개발을 시작하는 사람은 그리 많지 않다고 생각한다.
그렇기 때문에 추상적인 설계를 하기 위해서는 구체적인 것들로부터 공통점을 뽑아내는 것보다는 내가 구현해야하는 이 개념이 어떤 작은 부품들로 이루어져 있는지부터 고민해보고, 이 부품들을 어떤 방식으로 조립(합성)해가며 구체적인 개념을 만들어가는 방식으로 접근하는 것을 추천하는 것이다.
아이폰이라는 것은 마이크, 스피커, 디스플레이, 홈버튼 등으로 이루어져있다.
각각의 부품들은 어떤 방식으로 조립되어야 할까?
아마 스피커나 마이크 같은 애들은 다른 스마트폰이라도 위치가 크게 변하지 않을거야.
홈 버튼은 스마트폰마다 모양도 다르지 않나? 요즘에는 심지어 없는 것도 있던데, 그럼 이걸 어떻게 조립해야할까?
이렇게 Bottom-Up 사고 방식으로 설계를 하게되면 자연스럽게, 아이폰이라는 개념과, 더 나아가서는 스마트폰이라는 개념까지도 포괄할 수 있는 설계를 만들기 쉬워진다.
아무래도 구체적인 개념은 당장 현재의 비즈니스 상황만을 반영하게 되기 때문에, 구체적인 개념에서 공통점을 뽑아내어 추상적인 개념을 정의할 때는 미래의 변경 가능성까지 고려하기 어렵지만, 추상적인 개념들을 조립하여 구체적인 개념을 만들어내는 과정으로 사고하게 되면 내가 딱히 의식하지 않아도 어느 정도는 자연스럽게 추상적인 개념들을 갈아끼울 수 있게 만드는 설계를 하기 쉬워진다.
좋은 추상화를 위해 고민해볼만한 것들
추상화라는 개념과 추상화를 시작할 때의 접근 방법과 같은 거시적인 것들에 대해 알아보았다면, 지금부터는 실제로 추상화를 진행할 때 한번 고민해보면 좋을 법한 액션아이템들에 대한 이야기를 해보려고 한다.
앞서 필자는 Bottom-Up 사고 방식을 통해, 구체적인 요구사항을 달성하기 위해서 어떤 추상화된 부품들이 필요할지에 대해 고민해보자고 이야기했었는데, 이런 방식을 통해 추상화를 진행하게 되면 이제 “부품을 어떤 단위로 설계해야하는지”, “부품의 기능을 어떻게 표현해줄지” 같은 고민이 새롭게 생겨난다.
각각의 부품이 하나의 작은 역할만 담당하도록 관심사를 나눠서 설계할 수도 있지만 오히려 각 부품의 개념을 잘게 나누었다가 과한 추상화로 인해 맥락을 파악하기 어려운 코드가 될 수도 있으며, 각각의 부품의 기능을 제대로 표현하지 못 해 다른 부품과 합성이 어려운 부품을 만들어버리게 될 수도 있다.
그래서 이번 챕터에서는 필자가 추상화를 진행할 때 신경쓰는 몇 가지 고민들을 함께 공유하려고 한다.
개발자에게 과한 맥락을 부여하지 않기
추상화의 장점이라고 하면 보통 재사용성에 대한 이야기를 많이 하지만, 필자가 여러 번 이야기 했듯이 추상화의 가장 큰 장점은 복잡한 것을 단순해보이게 만들 수 있다는 점이다.
이러한 추상화의 장점은 오늘날 자주 사용하는 클래스, 함수, 컴포넌트 모두에게서 발견할 수 있는데, 대충 예를 들어보자면 이런 느낌이다.
배열 내부에 있는 값들의 앞에 “I am “이라는 값을 붙혀주세요.
const arr = ['Evan', 'Daniel', 'Martin'];
const newArr = [];
for(let i = 0; i < arr.length; i++) {
newArr[i] = `I am ${arr[i]}`;
}
console.log(newArr); // ['I am Evan', 'I am Daniel', 'I am Martin'];사실 요즘 이렇게 명령형 프로그래밍을 하시는 분을 많지 않을 거라고 생각하지만, 설명을 위해 조금 과장되게 작성해보았다. 위 코드는 배열 내부의 값들에 I am이라는 값을 붙히기 위해 for 문을 사용하여 직접 배열을 순회하고 인덱스를 사용하여 각 원소에 접근하여 값을 재할당하고 있다.
그리고 이 코드를 읽는 개발자는 자연스럽게 아래와 같은 맥락들을 파악하게 될 것이다.
for문을 사용하여 내부의 코드를 반복 실행할 것이다.
i라는 변수를0으로 초기화하고 반복이 한 번 종료될 때마다 해당 변수에1을 더할 것이다.위에서 선언한
i를 배열의 인덱스로 사용하여 각 원소에 접근한다.템플릿 스트링을 사용하여 배열의 원소 값의 앞 쪽에
I am이라는 값을 합성한다.
사실 이 코드는 굉장히 많은 맥락을 내포하고 있는 코드이다. 왜냐하면 개발자는 이 코드가 배열 내부의 값들의 앞 쪽에 I am이라는 값을 붙힌다는 동작을 충실히 수행할 수 있는 코드인지만 알면 이 코드를 이해하는데 아무런 무리가 없기 때문이다. 인덱스를 어쩌고 for 문을 어쩌고 하는 것들을 알 필요가 없다는 것이다.
그렇다면 이 동작을 여러가지 레벨로 추상화해보면 어떻게 될까?
// 배열을 순회하며 새로운 배열을 만드는 부분까지만 추상화
const newArray = arr.map(v => `I am ${v}`);
// 템플릿 스트링으로 문자열을 합성하는 부분까지도 추상화
const newArray = arr.map(v => addPrefix(v, 'I am'));
// map을 사용한다는 사실까지도 추상화
const newArray = addPrefixToItems(arr, 'I am');
// "I am"이라는 문자열을 합성하는 과정까지 추상화
const newArray = addIamToItems(arr)위 코드들은 위에서 밑으로 내려갈수록 점차 높아지는 추상화 레벨을 보여주고 있다.
가장 위 쪽에 있는 코드는 for 문을 사용하여 배열을 순회하고 새로운 배열을 반환하는 부분이 추상화되었으니, 이제 개발자는 배열 내부의 원소에 접근하기 위해 for 문을 사용하여 i라는 변수를 직접 초기화하고 관리해야 한다는 맥락이나 새로운 변수로 배열을 선언해야한다는 맥락을 잊을 수 있다.
즉, 개발자는 배열을 순회하여 기존 원소들을 토대로 만들어낸 새로운 원소를 담은 배열을 생성한다는 Array.prototype.map이라는 메소드의 동작만 알고 있으면 되는 것이다. 이렇게 추상화된 코드는 컴퓨터가 수행하는 명령의 절차보다는 개발자가 의도한 행위 자체에 더 초점을 맞춰 표현되게 되므로 이를 선언적 프로그래밍이라고 하기도 한다. (어떻게 할 것인지 보다는, 무엇을 할 것인지에 초점을 맞춰 선언하며 프로그래밍을 진행한다)
조금 더 일상적인 예시를 하나 더 보도록 하자. 아마 여러분은 이미 평소에 다양한 라이브러리를 사용하며 이러한 코드를 작성하는 경험을 하고 있을 것이다.
import { css } from '@emotion/css';
import format from 'date-fns/format';
const Foo = () => {
// Date 객체를 생성하고 내부 상태를 오늘 날짜로 초기화하는 행위를 추상화
const now = new Date();
// Date 객체를 토대로 원하는 String을 생성하는 행위를 추상화
const formattedDate = format(now, 'yyyy-MM-dd');
return (
// React.createElement 함수로 VDOM 객체를 생성하는 행위를 추상화
<h1 className={
css`
font-size: 1.8rem;
font-weight: 800;
` // 작성한 css를 style 태그로 감싸 <head> 태그에 넣는 행위, class를 생성하는 행위를 추상화
}>
Today is {formattedDate}
</h1>
);
}
// 그리고 위 모든 행위를 추상화
<Foo />Foo 컴포넌트는 단순히 오늘 날짜를 2023-03-02와 같은 포맷으로 보여주는 굉장히 간단한 일을 하는 녀석이지만, 이렇게 작은 컴포넌트조차 동작을 하나하나 뜯어본다면 굉장히 많은 부분이 추상화되어있다는 사실을 알 수 있다.
만약 여러분이 이 컴포넌트 하나를 만들기 위해 이 모든 행위에 대한 코드를 읽고 이해해야 하거나, 혹은 코드를 직접 작성해서 해결해야 한다면, 더 이상 이 녀석이 간단한 컴포넌트라고 말하기는 어려울 것이다. 즉, 추상화를 통해 간단해보이도록 만들었을 뿐 사실은 전혀 간단하지 않은 것이다. (일단 VanilaJS로 React 구현하는 것부터 빡세다…)
하지만 위 코드에 적혀있는 주석들이 이야기하고 있는 행위들이 모두 emotion, date-fns, react 등의 라이브러리에 추상화되어있으니, 우리는 이런 복잡한 행위를 신경쓰지 않고 “현재 시간을 렌더하는 것”에만 집중할 수 있게 되었다.
다시 강조하지만 산업에서의 추상화가 가지는 가치는 복잡한 무언가를 단순해보이게 만들어, 각각의 인간들이 자신의 전문 분야에만 집중하여 협업함으로써 더 고도화되고 복잡한 것을 만들 수 있게 만들어준다는 것이다. 이러한 추상화의 본질적 가치는 우리가 매일 경험하고 있는 프로그래밍의 세계에서도 마찬가지로 통용되고 있는 것이다.
흔히들 가독성이 부족한 코드에 대한 내용을 이야기할 때 많은 분들이 코드 라인의 수에 대한 이야기를 하시는데, 이것은 단순히 코드 라인의 수가 많다는 것보다는 “모듈의 동작을 이해하기 위해 읽고 분석해야 할 코드의 양이 많다”라는 것에 대한 문제를 이야기하는 것에 가깝다.
간단하게 생각해서 위 예시의 코드에서 emotion, date-fns, react 라이브러리들의 내용물이 전부 Foo 컴포넌트와 같은 모듈에 선언되어있다면 어떨지 상상해보면 된다.
아무것도 모르는 상태에서 해당 모듈을 딱 열었을 때 모든 라이브러리의 코드가 한번에 보인다면 내가 어디에서부터 어디까지 읽어야 하는 것인지, 어떤 부분은 그냥 무시하고 넘어가도 되는 것인지, 도대체 이 많은 코드 중에서 버그는 어디에 발생한 것인지 한 번에 파악하기 어려울 것이기 때문이다. 즉, 개발자에게 강요되는 맥락이 과하다.
조직 내에서 자주 사용되는 모듈을 굳이 어플리케이션 내에서 분리해두는 것이 아닌, 별도 패키지로 구성하여 레지스트리에 배포하고 사용하게 하는 이유도 마찬가지이다. 두 방법 모두 비즈니스 로직과 분리되어있는 것은 마찬가지겠지만, 개발자가 소스코드를 까보는 행위 자체를 아예 차단해버리거나 귀찮게 만듦으로써 분리된 모듈에 대한 맥락을 인식하는 것을 제한하려는 의도인 것이다. (물론 의존성 관리가 가능하다는 점, 여러 어플리케이션 간 재사용이 용이하다는 점도 사내라이브러리의 장점이다)
// 딱 봐도 레퍼런스타면 @quotalab/utils.d.ts로 갈 것처럼 생김
// 그래서 사람들이 소스코드를 까볼 시도를 잘 안 한다
import { uniq } from '@quotalab/utils';
// 왠지 레퍼런스 타자마자 소스를 볼 수 있을 것만 같은 기분이 든다
// 경로가 이렇게 생기면 뭔가 이상하다 싶을 때 사람들이 바로 소스 까봄 -> 맥락이 노출된다.
import { uniq } from 'utils/array';결국 우리가 추상화를 해야하는 근본적인 이유는 내 코드를 읽는 다른 개발자, 혹은 미래의 나 자신이 코드의 동작을 이해할 때 너무 과한 맥락에 노출되지 않도록 맥락의 스코프를 만들어주는 것에 가깝다. 마치 컴퓨터를 사용할 때 반도체의 원리를 몰라도 괜찮은 것처럼 말이다.
그러니 추상화를 진행하는 사람은 다른 사람들이 내 코드의 동작을 이해하고 활용하기 위해 어떤 부분까지 알아야하는지, 어떤 부분은 굳이 몰라도 되는지에 대한 깊은 고민을 해볼 필요가 있다.
표현에 대해서 고민하기
결국 좋은 추상화라는 것이 디테일한 코드를 숨겨, 개발자가 내부를 까보지 않더라도 코드의 동작을 이해하는 비용을 줄일 수 있도록 도와주는 수단이라면, 이제 우리는 추상화해놓은 모듈 내부에 존재하는 코드를 외부 세계에 어떻게 하면 잘 표현하여, 내가 작성한 모듈을 사용하는 개발자가 모듈 내부를 까보지 않아도 동작을 충분히 유추할 수 있을지에 대한 고민을 시작해야 한다.
흔히들 사람들이 제품에 대한 설명서를 제대로 안 읽는다는 우스갯소리가 있는데, 결국 이런 밈이 가능한 이유도 사용자가 굳이 설명서를 처음부터 끝까지 읽지 않더라도 제품의 사용 방법을 대략적으로 예측할 수 있도록 만들어졌기 때문이다. 즉, 설명서를 읽지 않아도 제품을 사용할 수 있다는 것은 역설적으로 그 제품이 누구에게나 익숙한 UX 패턴을 가지고 있다는 것을 의미한다.
 당장 필자부터도 간단한 장비에 대해서는 제대로 설명서를 읽지 않는다.
당장 필자부터도 간단한 장비에 대해서는 제대로 설명서를 읽지 않는다.사실 워런티 카드가 있다는 것도 방금 알았다.
사실 대부분의 제품은 설명서를 읽어보지 않더라도, 눈에 보이는 버튼을 몇 번 눌러보고 대충 이것저것 만져보기만 해도 금새 사용법을 유추할 수 있다. 필자도 3년 전에 구매한 모니터 설명서를 아예 뜯지도 않았지만 모니터를 연결하고 사용하는 것에는 아무런 무리가 없었다.
오히려 설명서를 읽지 않고는 전혀 제품의 사용 방법이나 동작을 유추할 수 없는 제품이라면, 그 제품의 사용법이 일반적이지 않고 너무 어렵다는 이야기이니 소비자들에게 외면받지는 않을까?
우리가 만들어야 하는 모듈도 이와 똑같다. 설명서를 소스 코드라고 생각해보자. 추상화를 진행하는 개발자는 사용자가 설명서, 즉 소스 코드를 직접 까보지 않더라도 모듈의 사용 방법을 대략적으로라도 유추할 수 있도록 모듈의 동작, 입력/출력에 대해서 명확하게 표현해줘야 하는 것이다.
우리가 외부 세계에 내부 동작을 표현하고 싶을 때 사용할 수 있는 방법은 크게 2가지 정도이다.
변수나 모듈의 이름
대상이 함수나 클래스라면, 모듈의 입력과 출력 타입
function addDays(date: Date, amount: number): Date;위 예시는 addDays라는 date-fns 라이브러리의 함수의 정의이다. 이 함수는 이름만 봐도 특정 대상에게 days라는 것을 더하는 역할을 한다는 것을 알 수 있으며, Date 타입의 값과 number 타입의 값을 입력으로 받고 다시 Date 타입을 출력하고 있으니, 인자로 받은 Date 객체에 amount 만큼의 일자를 더한 Date 객체를 반환해준다는 동작을 유추해볼 수 있다.
물론 필자는 이 함수를 호출했을 때 내부에서 정확히 어떤 일이 발생하는지 모른다. 뭐 대충 유추해보자면 Date.prototype.getDate로 일자를 가져와서 amount 만큼 값을 더하고 어쩌고 하는 행위를 수행하겠지만, 필자가 이 함수를 사용하기 위해 굳이 이런 것까지 알 필요는 없기 때문이다.
필자는 그저 “이 함수를 사용하면 Date 객체에 원하는 만큼의 일자를 더한 새로운 Date객체를 얻을 수 있다”라는 사실 하나만 알면 되며, 이러한 사실은 함수의 이름과 입출력 타입에서 충분히 유추해볼 수 있다.
하지만 만약 이 함수의 이름과 입출력 타입이 이런 느낌이었다면 어땠을까?
function add(a: any, b: any): any; 도대체 무슨 일을 하는 녀석인지 알 수가 없다...!!!
도대체 무슨 일을 하는 녀석인지 알 수가 없다...!!!
일단 이 함수도 이름이 add이니 뭔가를 더하긴 더하는 것 같은데, 도대체 뭘 더한다는 것인지, 그리고 함수가 어떤 값을 반환하는지 전혀 감을 잡을 수가 없다. 왜냐하면 이 함수는 입출력에 대한 타입이나 변수명 등으로 자신 내부의 동작을 충실하게 표현하고 있지 않기 때문이다.
만약 여러분이 이 함수를 사용하는 사용자라면 이 함수의 동작을 믿고 사용할 수 있을까? 아니 믿는 것은 둘째치더라도 도대체 이 함수가 뭐 하는 녀석인지 감을 잡을 수 없으니 아예 사용 자체를 안 하게 될 수도 있을 것 같다.
혹여나 어떻게든 사용을 한다고 해도 드러난 표현만으로는 함수의 동작을 이해할 수 없어 저 함수의 소스 코드를 까봐야지만 해당 함수를 사용할 수 있을테니, 복잡한 맥락을 감출 수 있다는 추상화의 장점 또한 잃어버리게 된다.
이런 경우 외에도 함수의 인자가 지나치게 많다던가, 함수의 이름이 함수의 동작과 다른 맥락을 표현하고 있다던가 하는 것들 또한 내 코드를 사용하는 개발자가 함수의 역할을 쉽게 유추하지 못 하게 방해하는 요소일 수 있다.
이러한 표현의 중요성은 비단 함수가 아니더라도 클래스나 일반 변수 등 모듈 밖으로 노출될 수 있는 모든 개념들에게 공통적으로 적용되는 사항이며, 내가 작성한 코드를 사용할 다른 개발자나 혹은 미래의 나 자신을 배려하는 설계의 기초가 되는 것이기도 하다.
입력의 자유도를 제어해서 좋은 DX 만들기
추상화된 모듈의 동작을 외부 세계에 제대로 표현하는 것에 대해 익숙하다면 이제는 내 모듈을 사용하는 사용자들의 DX에 대해서 깊게 고민해볼 차례이다.
물론 DX를 만들어내는 요인은 여러가지가 있겠지만, 그 중에서도 필자가 가장 신경쓰는 부분 중 하나는 바로 “기능을 어디까지 열어줄 것이냐”이다. 왜냐하면 이 의사결정에 의해 필자가 개발한 모듈을 사용하는 사람들의 작업 리소스, 인지해야하는 맥락의 정도, 휴먼 에러의 가능성 등이 달라질 수 있기 때문이다.
예를 들어 간단한 버튼 컴포넌트 하나를 개발한다고 생각해보자.
const Button = ({ children }: PropsWithChildren<unknown>) => {
return <button>{children}</button>;
}위 컴포넌트는 외부 세계에 자신의 기능을 많이 드러내지 않고 있는, 이른바 기능이 닫힌 컴포넌트이다. 애초에 컴포넌트 자체에서 children을 꽂아넣을 수 있는 기능만을 제공하고 있으니, 이런 컴포넌트를 사용하는 사용자는 선택의 자유도가 높지 않다.
그나마 children이라는 프로퍼티는 합성을 통해 마음껏 외부에서 주입할 수 있겠지만, 그 외에 button의 type을 변경하고 싶다던가, 클릭 이벤트 핸들러를 사용하고 싶다던가 하는 것들은 전부 불가능하기 때문이다.
그러나 제공해주고 있는 기능 자체가 매우 제한적이고 적기 때문에, 이 컴포넌트를 사용하는 사용자는 컴포넌트의 사용법에 대해서 크게 고민해야 할 필요가 사라졌다.
const Button = (props: ComponentProps<'button'>) => {
return <button {...props} />;
};반면 위 컴포넌트는 React의 button 컴포넌트가 기존에 제공하고 있던 모든 기능을 입력으로 받을 수 있도록 설계되었다. 이런 컴포넌트를 사용하는 사용자는 자신이 원하는 button 컴포넌트의 프로퍼티를 모두 사용할 수 있으니 자유도가 높은 개발을 할 수 있을 것이다.
그러나 컴포넌트가 제공하는 프로퍼티가 매우 많기 때문에 사용하는 입장에서도 자신의 목적과 다소 어긋난 맥락들에 지속적으로 노출될 수 있다. 필자는 이런 상황을 주로 “컴포넌트가 개발자에게 고민을 강요한다” 표현한다.
또한 이 컴포넌트를 개발한 사람 입장에서는 사용자가 어떤 방식으로 내가 설계한 모듈을 사용하게 될 지에 대한 모든 경우의 수를 예측할 수 없으니 그만큼 버그나 설계 의도와 벗어난 사용 사례가 늘어날 수 있다는 리스크도 있다.
즉, 추상화된 모듈을 만드는 개발자는 모듈의 입력 범위를 제어함으로써, 사용자가 어떤 방식으로 내 모듈을 사용하게 만들지도 어느 정도 제어할 수 있다는 것이다. 그러니 이런 입력에 대한 설계는 모듈을 사용하는 개발자의 DX와도 직결된다.
이런 고민은 주로 다양한 개발자들이 함께 사용해야하는 사내라이브러리 등을 개발할 때 주로 하게 되는데, 특히 디자인 시스템 같은 경우는 이러한 인터페이스를 설계할 때 디자이너 분들의 의도까지 함께 녹여야하니 더 복잡한 상황이 펼쳐진다. (코드에 정의된 프로퍼티들이 Figma, Framer 등에 정의된 프로퍼티와 유사할수록 개발자/디자이너 간 커뮤니케이션 비용이 낮아진다)
사실 모듈의 입력을 많이 열어줄 것이 좋냐, 혹은 제한할 것이 좋냐에 대한 정답은 없다. 이는 모듈을 사용하는 사용자들의 전문성, 모듈의 목적과 용도, 혹은 오픈소스와 같은 불특정 다수의 사용자인지 사내라이브러리같은 제한된 그룹의 사용자인지에 따라서도 달라질 수 있기 때문이다.
이렇게 비슷한 역할을 하는 도구라고 해도 제공해주는 기능의 범위를 제한함으로써 사용자의 경험을 만들어나가는 개념은 비단 코드 뿐 아니라 우리의 일상 속에서도 흔히 볼 수 있는 개념이다.

 전문적인 오디오 지식이 있는 사람들은 기능이 다양한 신디사이저를 적재적소에 활용하지만
전문적인 오디오 지식이 있는 사람들은 기능이 다양한 신디사이저를 적재적소에 활용하지만전문적인 지식이 없다면 차라리 기능이 제한된 디지털 피아노를 사용하는 게 더 목적에 맞을 수 있다.
신디사이저라는 악기는 오디오 파형을 직접적으로 변경해가면서 원하는 소리를 만들 수 있는 악기이기에 사용자에게 무궁무진한 자유도를 가져다 주지만, 만약 오디오에 대한 전문적인 지식이 없는 사람에게 이런 악기를 가져다준다면 제대로 사용하지도 못 하고 이것저것 만져보다가 당근마켓에 올려버릴 가능성이 높다.
게다가 이렇게 복잡한 장비들은 전압에 민감하게 반응하도록 설계된 경우도 있어, 사용자의 부주의로 인해 자칫 장비가 망가질 위험도 존재한다.
그러니 오히려 전문적인 지식이 없는 사람이거나, 아예 이런 자유도가 필요없는 사람에게는 신디사이저보다 기능은 제한되어있지만 비전문가도 편하게 접근하여 이쁜 소리를 낼 수 있는 디지털 피아노가 더 적당할 수 있는 것이다.
즉, 단순히 전문가가 더 많이 알고 있으니 기능을 노출시켜주자는 개념보다는 해당 도구가 사용되어야 하는 상황과 사용하는 사람이 도구의 원리에 대해서 알 필요가 있냐, 없냐에 따라 달라지는 개념이다. 애초에 단순히 피아노를 치고 싶어하는 사람이 신디사이저 같이 복잡하고 기능이 다양한 악기를 살 필요가 없다는 말이다.
필자가 예시로 들었던 악기가 아니더라도 자동차의 수동 변속기와 자동 변속기, 휴대폰과 HAM에 사용하는 무선송수신기, C와 JavaScript처럼 비슷한 기능을 제공하지만 도구의 목적과 사용자의 페르소나에 따라 기능의 범위를 제한하는 개념은 무궁무진하게 많다.
결국 우리는 사용자가 도구의 원리를 알 필요도 없는 상황에서 넓은 범위의 입력을 구현하여 괜히 고민하도록 만들거나, 반대로 도구의 원리를 이해하고 다양한 상황에 재사용해야하는 상황에서 좁은 범위의 입력을 구현하여 사용처를 제한해버리는 설계를 하지 않도록 주의해야 하는 것이다.
앞서 이야기했던 것처럼 이는 비즈니스나 조직의 상황, 도구의 목적, 사용자들의 니즈 등의 문제를 모두 고려해서 의사결정해야하는 부분인 만큼 어떠한 정답이 있는 문제는 아니지만, 적어도 나 이외에 사용자들이 함께 사용해야하는 모듈을 추상화하여 만들어야 하는 입장이라면 한번 쯤 고민해볼만한 문제라고 생각한다.
마치며
오늘날 지구 상에 존재하는 모든 개발자들은 다른 개발자들과 긴밀한 협력 관계에 놓여있다. 물론 프리랜서나 초기 스타트업에서 일하는 분들처럼 혼자서 개발하는 분들도 있겠지만, 결국 그 분들도 다른 사람이 고안하고 개발한 도구를 가져다 쓰는 것을 피할 수는 없으며, 내가 작성한 코드를 무덤까지 가져가는 것도 아니니 언젠가는 다른 개발자가 내 코드를 이어받는 그 날이 반드시 찾아온다.
결국 내가 지금 작성한 코드를 다른 사람이 읽고 이해해야하는 순간은 피할 수 없기 때문에, 우리는 기본적으로 사람이 이해하기 좋은 코드를 작성하는 것이 힘을 기울일 수 밖에 없는 것이다. 심지어 정말로 혼자서만 작성하는 코드라고 해도, 결국 미래의 나 자신이 모든 코드의 동작을 기억하고 있을거란 보장이 없으니 미래의 나 자신을 위해서라도 이런 코드를 작성해야한다.
결국 프로그래밍에서의 추상화는 복잡한 원리를 가진 무언가 또는 컴퓨터는 이해하기 쉽지만 사람은 이해하기 어려운 무언가를 사람이 이해하기 쉽도록 만드는 과정이다. 물론 좋은 추상화를 하는 방법이나 노하우는 사람마다 다를 수 있지만, 결국 이러한 추상화의 본질 자체는 바뀌지 않는 것이다.
필자는 개인적으로 추상화에 대한 방법이나 노하우는 그렇게 중요하지 않다고 생각한다. 앞서 말한 것처럼 변경에 열린 설계를 하기 위한 패턴이나 방법들은 이미 인터넷에 널려있고, 이미 깔끔하게 정리되어있는 개념들이 많기 때문에 그 정보들을 읽고 몇 번 사용해보는 것만으로도 익히는 것에는 크게 문제가 없을 것이다.
다만 추상화라는 선물이 우리에게 가져다주는 근원적 가치에 대한 이해가 없다면, 이렇게 공부한 정보들이 나에게 정말로 유용한 것인지 아닌지에 대한 가치 판단마저도 하기 어렵게 되어버릴 수 있다.
개발자들은 모든 문제를 해결할 수 있는 만능적인 해결책은 존재하지 않는다는 “No Silver Bullet”이라는 문장을 자주 사용한다. 이 문장이 의미하는 것처럼 우리가 접하는 수많은 정보들은 모두 이익만을 가져다주는 것이 아니며, 때로는 내가 내린 기술적 의사결정으로 인해서 오히려 잃는 것이 발생할 수도 있다.
이런 상황 속에서 개발자는 항상 내가 내리는 의사결정이 가져다주는 이익과 그와 반대로 잃게되는 손해에 대해서 냉철하게 저울질해보고 판단해야하며, 필자는 이러한 의사결정에 도움이 되는 것이 바로 “해당 기술이 가져다주는 근원적 가치에 대한 이해”라고 생각한다.
물론 이 포스팅에서 필자가 작성한 것이 정답이라는 이야기는 아니다. 이 내용은 필자가 지금까지 개발자로 일을 하면서 고민했던 내용에 불과하며, 전 세계에 존재하는 수천만 명의 개발자들 또한 각각 저마다의 고민 끝에 내려진 정의를 가지고 있으리라 생각한다.
필자가 고민해온 이 내용들이 독자 여러분이 내렸던 혹은 앞으로 내릴 추상에 대한 정의에 조금이나마 도움이 되길 바라면서, 이상으로 추상이란 무엇일까 포스팅을 마친다.