서버의 상태를 알려주는 HTTP 상태 코드
인터넷의 질서를 만드는 작은 숫자들

최근의 모던 어플리케이션은 완전히 네트워크 위에서 돌아가는 프로그램이라고 해도 과언이 아닐 정도로 프로그램의 비즈니스 로직에서 통신이 차지하는 비중이 높다. 클라이언트 어플리케이션은 백엔드에 위치한 서버와 통신하여 현재 로그인한 사용자의 정보를 받아오거나, 새로운 게시글을 생성하기도 하고, 때로는 Web Socket을 통해 서버에서 발생한 이벤트를 구독하여 푸시 메세지나 채팅과 같은 기능을 구현하기도 한다.
이 과정에서 프론트엔드와 백엔드는 어떤 방식으로 통신을 할 것인지부터 시작하여 리소스의 생성과 삭제는 어떻게 정의할 것인지, 프론트엔드에서 요청한 백엔드 작업의 성공/실패 여부는 어떻게 알려줄 것인지 등 많은 규칙들을 정의해야한다.
그래서 이러한 규칙들을 정의할 때 도움을 주는 몇 가지 가이드라인들이 존재하는데, 이때 등장하는 것들이 HTTP 메소드나 상태 코드같은 표준과 REST 같은 녀석들이다.
이번 포스팅에서는 이 중에서 프론트엔드와 백엔드 간의 통신을 할 때 조금 더 명확한 정의를 위해 필요한 요소 중 하나인 HTTP 상태 코드를 파헤쳐보는 시간을 가져보려고 한다.
굳이 이러한 가이드라인을 지켜야 하나요?
사실 HTTP 메소드나 상태 코드, 그리고 REST 같은 것들은 말 그대로 가이드라인에 불과하다. 이것들을 지키지 않는다고 해서 프로그램이 작동하지 않는 것도 아니고 사용자가 프로그램을 사용하던 도중 런타임 에러가 발생하는 슬픈 일도 발생하지 않는다.
즉, 지키지 않아도 사실 프로그램을 작성하는데는 아무런 지장이 없다는 것이다.
 그럼 굳이 안 지켜도 상관없는 것 아닌가요?
그럼 굳이 안 지켜도 상관없는 것 아닌가요?
음, 이러한 규칙들을 지키지 않는 것은 자유지만 그로 인해 발생하는 사이드 이펙트들을 생각해보면 되도록이면 지켜주는 것이 좋다고 이야기하고 싶다.
표준 인터페이스의 존재 이유를 생각해보자
산업 표준은 불특정 다수에 의해 생산되는 제품들의 호환성을 맞추고, 제품 생산자들 간의 커뮤니케이션을 원활하게 하기 위해서 제정되며, 이렇게 각자 다른 객체들을 호환하기 위해 정의하는 일련의 표준 규격을 우리는 “인터페이스(Interface)“라고 부른다.
이 인터페이스라는 개념은 꽤나 광범위해서 뭐든 연결해주기만 할 수 있다면 인터페이스라고 생각하면 된다. 모니터와 컴퓨터를 연결하는 HDMI, 저장 장치에 사용되는 SATA, USB와 같은 친구들도 전부 인터페이스다. 심지어 UI(User Interface)같은 경우에는 기계와 기계가 아니라 인간과 기계를 이어준다는 개념으로까지 사용된다.
그 중 개발자들에게 가장 친숙한 인터페이스는 바로 API(Application Programming Interface)이다. API는 응용 프로그램을 제작할 때 필요한 기능들을 일련의 인터페이스로 제공된 것을 의미한다.
이때 API를 사용하는 쪽에서는 API의 사용법만 알면 되고 그 이면에 어떤 거대한 로직들이 숨어있는지는 일절 관심을 끊어도 되기 때문에 굉장히 편리하다는 장점이 있다. 대표적인 API의 한 종류로는 C에서 제공하는 Windows 운영체제의 API가 있다.
#include <Windows.h>
#include <tchar.h>
int APIENTRY _tWinMain(
HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPTSTR lpCmdLine,
int nCmdShow
) {
MessageBox(NULL, TEXT("Hello, Windows!"), TEXT("App"), MB_OK);
return 0;
}개발자는 Windows 운영체제가 어떻게 저 메세지박스를 렌더하는지 모르더라도 단지 MessageBox라는 API의 함수를 사용함으로써 간단하게 메세지박스를 사용할 수 있다. 그리고 이 과정은 필자가 작성하는 C 어플리케이션과 운영체제, 전혀 다른 두 프로그램 간의 통신이기도 하다.
즉, API는 프로그램 간의 통신을 위한 인터페이스라고 할 수 있다. 마찬가지로 클라이언트가 서버에게 뭔가를 요청할 때도 특정 규칙으로 정의된 API를 사용하여 서버의 리소스를 사용하게 되는데, HTTP를 사용하여 통신하는 대부분의 모던 어플리케이션에서는 이 API를 엔드포인트(endpoint)라고 불리는 특정한 URL을 사용하여 정의하게되며, 서버는 일관된 방식으로 이 엔드포인트로 들어온 클라이언트 요청에 대한 응답을 보내줘야한다.
이때 HTTP 상태 코드는 클라이언트가 보냈던 요청의 수행 결과를 의미하는 일종의 약속이며, API를 구성하는 중요한 요소 중 하나이다.
백엔드는 잘 모르는 프론트엔드의 슬픈 사정
이 섹션에서는 잘못 정의된 API를 사용하는 프론트엔드 개발자라면 한번쯤은 겪어보았음직한 일을 한번 짧게 이야기해보려고 한다. 아마 백엔드 개발자들은 프론트엔드 어플리케이션의 소스를 직접 보는 경우가 드물기 때문에 이런 상황이 있다는 사실조차 모를 수 있을 것 같다.
바로 HTTP 상태 코드를 잘못 사용하고 있는 경우인데, 이런 상황에 대한 대표적인 예시는 바로 요청이 실패했을 때에도 상태 코드를 요청 성공을 의미하는 200 Ok로 내려주는 것이다.
GET /api/users/123HTTP/1.1 200 OK
{ "success": false }이렇게 설계한 API의 경우, 위 예시처럼 HTTP 응답 바디에 요청의 성공/실패 여부나 실패 이유를 함께 담아서 보내주는 경우가 대다수인데, 그러면 프론트엔드 어플리케이션에서는 처리가 약간 애매해지는 상황이 발생한다.
프론트엔드에서는 이런 비동기 요청을 Promise를 통해서 처리하게 되는데, 문제는 대부분의 HTTP 통신 라이브러리나 API들은 백엔드에서 보내주는 요청의 상태 코드에 따라 요청의 성공/실패 여부를 판단하고, 요청이 실패했을 경우에만 에러를 던진다는 것이다.
그래서 일반적인 경우, 프론트엔드 어플리케이션에서는 대략 이런 느낌으로 통신을 담당하는 코드를 작성한다.
async function fetchUsers () {
try {
const response = await fetch('/api/users/123');
return response.json();
}
catch (e) {
alert('요청이 실패했어요!');
}
}서버로 보냈던 요청이 실패했다면 서버는 반드시 400이나 500번대의 상태 코드를 보내줄 것이고, 그렇게 되면 fetch API는 에러를 발생시킨다. 그래서 fetch를 사용할 때는 단순히 외부에서 try/catch 구문을 사용하는 것만으로도 간단하게 통신에 대한 에러를 핸들링할 수 있는 것이다.
하지만 위의 잘못된 예시처럼 백엔드 어플리케이션에서 요청이 실패했음에도 불구하고 상태 코드로 200번대 코드를 내려준다면 프론트엔드 어플리케이션의 코드에는 이런 슬픈 상황이 발생한다.
async function fetchUsers () {
try {
const response = await fetch('/api/users/123');
const { success } = await response.json();
if (!success) {
throw new Error();
}
} catch (e) {
alert('요청이 실패했어요');
}
}아까 전에는 없던 if (!success)가 생긴 것을 볼 수 있다. 즉, 불필요한 예외 처리가 한번 더 발생한 것인데, 이런 불필요한 예외처리는 코드의 가독성을 해치지만 프론트엔드 입장에서는 딱히 선택권이 없다. 그렇다고 서버가 보내주는 에러를 무시하고 핸들링을 안 할수도 없지 않은가?
게다가 백엔드 어플리케이션이 미처 핸들링하지 못한 에러가 발생하거나 서버가 아예 죽어버리기라도 하면 응답의 상태 코드에는 에러 코드인 500이나 502가 내려올 것이기 때문에 try/catch 구문을 사용하지 않을 수도 없다.
클라이언트에서 사용하는 모든 HTTP 통신 라이브러리들은 올바른 HTTP 상태 코드의 사용을 가정하고 설계되었기 때문에, 서버가 올바르지 않은 상태 코드를 사용한다면 이런 슬픈 상황이 발생할 수도 있다는 점을 이야기해두고 싶다. 그리고 사실 백엔드 어플리케이션에서 상황에 맞는 올바른 상태 코드를 내려주는 것이 그렇게 어려운 일도 아니다. (다만 조금 귀찮을 뿐이다)
클라이언트와 마찬가지로 대부분의 서버 프레임워크에서 제공하는 통신 라이브러리들도 모든 상황에 맞는 HTTP 상태 코드들을 제공하고 있으니 되도록이면 알맞은 상황에 맞는 상태 코드를 사용하는 것을 추천한다.
자, 그럼 이제 본격적으로 이 수많은 HTTP 상태 코드들이 정확히 어떤 상태를 의미하는지 알아보도록하자.
작업의 수행 상태를 알려주는 HTTP 상태 코드
클라이언트가 서버에게 작업을 요청하면 서버는 요청받은 작업을 수행한 후 작업의 수행 결과를 응답으로 보내주는데, 이때 HTTP 상태 코드를 사용하여 작업의 성공/실패 여부와 작업이 실패했다면 어떤 이유로 실패했는지도 알려주게 된다. 위에서 보았던 잘못된 예시처럼 HTTP 응답 바디에 작업의 실패 여부를 담아서 응답해주는 경우도 있지만, 더 좋은 방법은 바로 올바른 HTTP 상태 코드를 사용하는 것이다.
HTTP 상태 코드는 “200 = 성공”, “400 = 클라이언트가 요청 잘못함”, “500 = 서버가 잘못함”과 같이 각 상황에 맞는 코드가 표준으로 정해져있으며, 웹 상에서 돌아가는 기본적인 프로그램의 동작이나 프론트엔드, 백엔드 프레임워크들의 설계 또한 이 표준을 기준으로 만들어져 있기 때문에 되도록이면 이 표준을 지켜주는 것이 좋다.
HTTP 프로토콜을 사용하는 대표적인 프로그램인 웹 브라우저 또한 이러한 상태 코드 표준을 엄격하게 지키는 녀석 중 하나인데, 실제로 브라우저는 서버가 어떤 상태 코드를 응답으로 내려주는지에 따라 이번에 자신이 보낸 요청의 성공/실패 여부를 구분하고, 이를 시각적으로 표현해주기도 한다.
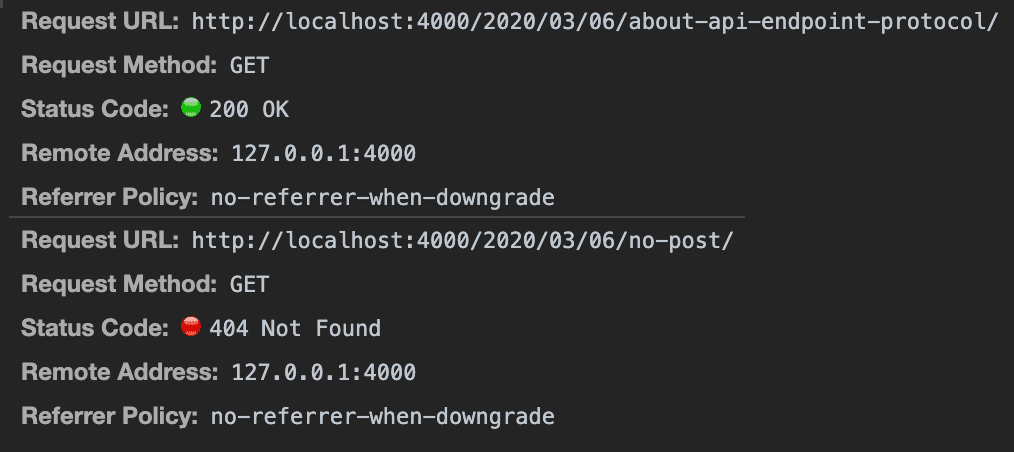 브라우저는 200번대의 상태 코드와 400, 500번대의 상태 코드를 전혀 다르게 인식한다
브라우저는 200번대의 상태 코드와 400, 500번대의 상태 코드를 전혀 다르게 인식한다
이런 상황에서 서버가 상태 코드는 200인데 응답의 바디로만 에러를 표현한다고 하면, 브라우저는 요청이 성공했다고 생각하지만 실제로는 요청이 실패한, 요상한 상황이 발생하게 된다.
심지어 서버가 응답의 상태 코드로 301과 같은 코드를 내려준다면, 브라우저는 자동으로 사용자를 다른 페이지로 리다이렉트(Redirect)해버리기 때문에 서버가 제대로 된 상태 코드를 응답에 담아주지 않는다면 브라우저가 예측하지 못한 동작을 일으킬 수도 있다.
자, 그럼 이제 각 HTTP 상태 코드가 어떤 상태들을 의미하는 것인지 하나씩 살펴보도록 하자. HTTP 상태 코드는 100번대 부터 500번대까지로 이루어져 있으며 꽤나 다양한 상태들을 정의할 수 있지만, 이걸 다 알 필요도 없고 설명하려면 너무 길기도 하니, 필자가 단 한번이라도 사용해보았던 상태 코드들을 기준으로 설명을 진행하려고 한다.
100번대
100번대 코드는 프로토콜을 교체해도 된다거나 계속 요청을 보내도 된다거나하는 식의 정보성을 띄고 있는 상태를 의미하지만, 실제로 필자가 어플리케이션을 개발하며 이 상태 코드들을 만나본 사례는 아직 단 한번도 없기 때문에 건너뛰도록 하겠다.
200번대
200번대 코드들은 클라이언트가 요청한 작업을 서버가 성공적으로 수행했다는 상태라는 것을 알려주는 코드이다. 200번대 코드들은 브라우저의 콘솔의 네트워크 탭에서도 깔끔한 초록색으로 표시해준다.
물론 “요청한 작업이 성공”이라는 응답만으로도 클라이언트가 원하는 정보를 모두 만족시킬 수 있긴 하지만, 조금 더 디테일한 상태를 정의해야하는 상황이라면 이 200번대의 상태 코드를 적극적으로 사용하여 클라이언트에게 더 자세한 정보를 알려줄 수도 있다.
200 OK
상태 코드 200은 단순히 작업이 성공했음을 의미한다. 대부분의 경우 클라이언트는 자신이 요청한 작업이 정확히 어떤 작업인지 알고 있기 때문에, 서버에서 “니가 보낸 요청이 성공했어”라는 정보만 알려주면 굳이 그 이상의 디테일한 정보는 알 필요가 없다. 그래서 이 상태 코드 하나만으로 모든 API 응답 성공 상태를 퉁치는 경우가 대다수이다.
201 Created
상태 코드 201은 말 그대로 요청이 정상적으로 수행되었고, 그로 인해 리소스가 새롭게 생성되었다는 것을 의미한다. 클라이언트가 서버에게 요청을 보내서 새로운 리소스를 생성하는 상황은 굉장히 흔한데, 그 중 필자가 경험했던 대표적인 사례는 바로 “회원가입”이다. 결국 클라이언트의 회원가입 요청으로 인해 데이터베이스에 새로운 유저의 로우가 생성되었기 때문에, 이런 경우가 201 상태 코드가 아주 잘 들어맞는 케이스라고 볼 수 있다.
204 No Content
상태 코드 204는 요청이 정상적으로 수행되었고, 이 요청과 관련되었던 컨텐츠 또한 더 이상 깔끔하게 존재하지 않음을 의미한다. 이 상태 코드는 클라이언트가 서버에게 요청을 보내서 뭔가를 삭제해야하는 응답으로 사용될 수 있고, 실제로 필자가 경험했던 사례 또한 게시글을 삭제하는 API였다.
참고로 이때 이 삭제 작업이 Soft Delete냐 Hard Delete냐와는 아무런 상관이 없다. 서버에서 어떤 방식으로 리소스의 삭제를 표현하던 클라이언트가 알아야할 정보는 “이 리소스는 삭제되었고, 더 이상 사용할 수 없다” 뿐이라는 사실을 명심하자.
300번대
300번대 코드들은 리다이렉션에 관련된 상태들을 의미한다. 클라이언트가 요청한 리소스가 옮겨졌거나 리소스가 삭제되었거나해서 정상적인 방법으로는 더 이상 해당 리소스에 접근할 수 없고 다른 URL을 통해서 그 리소스에 접근해야하는 경우 서버는 “여기로 가면 니가 찾는 리소스가 있어!”라는 정보를 알려줄 수 있는데, 이때 사용되는 상태 코드들이 바로 300번대 코드들이다.
301 Moved Permanetly
상태 코드 301은 301 Redirect라는 별칭으로 불리기도 할 만큼 리다이렉션을 위한 코드 중 가장 많이 사용되는 녀석이다. 브라우저는 자신의 대한 요청의 응답으로 301을 받으면 HTTP 헤더에 들어있는 Location 필드를 찾아보고, 해당 필드가 존재할 경우 Location 필드에 담긴 URL로 자동으로 리다이렉션한다.
HTTP/1.1 301 Moved Permanetly
Location: https://evan/moved-contents/1234또한 구글과 같은 검색 엔진의 봇들은 특정 페이지에 접근했는데 응답으로 301 상태 코드를 받을 경우 자동으로 페이지 정보를 갱신하기도 하기 때문에, SEO(Search Engine Optimization) 관점에서도 이 상태 코드를 올바르게 사용하는 것은 매우 중요하다.
이런 리다이렉션 설정은 보통 서버 엔진의 설정 파일 내에서도 할 수 있고, 백엔드 어플리케이션 내에서 직접 할 수도 있다. 일반적인 경우 이 상태코드는 HTTP 프로토콜로 접속한 사용자를 HTTPS 프로토콜을 사용해야만 접근 가능한 포트로 보내버릴 때에도 많이 사용된다.
server {
listen 80;
server_name evan.com;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
server_name evan.com;
...
}이 경우 80 포트로 접속한 사용자를 발견한 Nginx는 HTTPS 프로토콜을 사용해야만 접근할 수 있는 443 포트로 리다이렉트시켜서 해당 프로토콜 사용을 강제할 수 있다.
304 Not Modified
상태 코드 304는 클라이언트가 요청한 리소스가 이전 요청때와 비교해보았을 때 전혀 달라진 점이 없다는 것을 의미한다. 즉, 말 그대로 Not Modified, 수정되지 않음이다.
서버가 응답으로 이 상태 코드를 보내주면 클라이언트는 굳이 서버에게 리소스를 재전송받아야할 필요가 없기에 자신이 캐싱해놓았던 리소스를 사용하게되며, 이 과정에서 불필요한 통신 페이로드의 낭비를 줄일 수 있다.
이 과정에서 클라이언트는 서버로부터 요청된 리소스를 받은 것이 아니라 자신의 캐싱해놓았던 리소스를 사용하는 것이므로 이 또한 캐싱된 리소스로 리다이렉션되었다고 치는 것이다. 그런 이유로 304 상태 코드는 암묵적인 리다이렉션으로 불리기도 한다.
브라우저 역시 이 응답을 위한 자체 캐싱 기능을 가지고 있으며, 만약 304 상태 코드를 응답으로 받았는데 캐싱된 리소스가 없는 경우에는 빈 화면을 띄우거나 에러 화면이 노출된다. 그러니 이런 상황을 만나면 “브라우저에 Cached Resource가 없는 거 아님?”이라는 킹리적 갓심을 발휘해볼 수 있다.
400번대
400번대의 코드들은 클라이언트가 서버에게 보낸 요청이 잘못된 경우를 의미한다. 만약 이 상태 코드를 발견한다면 높은 확률로 프론트엔드 개발자가 예외 처리를 제대로 안 했거나 요청에 이상한 값이 묻은 경우가 많으니, 프론트엔드 개발자의 멱살을 잡도록 하자. (낮은 확률로 백엔드의 잘못인 경우도 있다…)
400 Bad Request
상태 코드 400는 가장 많이 만날 수 있는 400번대 코드 중 하나이며, 밑도 끝도 없이 “클라이언트가 요청 잘못 날림”을 의미한다. 이때 뭘 어떻게 잘못 날렸는지는 보통 HTTP 응답 바디에 담아서 알려주는 경우도 있지만, 그렇지 않은 경우에는 백엔드 어플리케이션의 로그를 까봐야하는 슬픈 상황이 펼쳐질 수도 있다.
401 Unauthorized
상태 코드 401는 인증되지 않은 사용자가 인증이 필요한 리소스를 요청하는 경우에 “너 인증 필요함”이라고 알려주는 상태 코드이다. 보통 로그인이 필요한 API를 비로그인 사용자가 호출했을 때 많이 사용된다.
클라이언트에서는 서버가 401을 응답으로 보내준 경우, 로그인이 필요하다는 것으로 판단하고 로그인 페이지로 사용자를 리다이렉션하기도 한다.
403 Forbidden
상태 코드 403는 클라이언트가 접근이 금지된 리소스를 요청했음을 의미한다. 이 상태 코드는 간혹 401 Unauthorized와 헷갈리고는 하는데, 상태 코드의 의미만 보면 확실히 애매모호하지만, 사실 분명한 한 가지 차이점이 있다.
401은 말 그대로 인증되지 않았다는 것을 의미하며, 인증이 되지 않았다는 것은 백엔드 어플리케이션이 현재 요청한 사용자가 누구인지 알 수가 없다는 것을 의미한다. 즉 이때 서버는 클라이언트에게 “너의 신원을 밝혀!”라고 말하고 있는 것이다.
그러나 403의 경우, 백엔드 어플리케이션은 현재 리소스를 요청한 사용자가 누구인지 전혀 신경쓰지 않는다. 클라이언트가 현재 자신이 누구인지 밝혔던 밝히지 않았던, 인증이 되었던 안 되었던 간에, 이 리소스를 요청하는 것은 무조건 금지라고 말하고 있는 것이다.
HTTPS 프로토콜로만 접근해야하는 리소스에 HTTP 프로토콜을 사용하여 접근했을 경우에 서버에서 403 응답을 보내주기도 한다.
404 Not Found
상태 코드 404는 말 그대로 요청한 리소스가 존재하지 않다는 것을 의미한다.
405 Method Not Allowed
상태 코드 405는 현재 리소스에 맞지않는 메소드를 사용했음을 의미한다. 백엔드 프레임워크의 경우 특정 컨트롤러에 해당 메소드를 사용하는 로직이 없다면 자동으로 405를 내려주기도 한다.
406 No Acceptable
상태 코드 406은 서버 주도 컨텐츠 협상을 진행했음에도 불구하고 알맞은 컨텐츠 타입이 없다는 것을 의미한다.
사실 클라이언트는 서버에게 리소스를 요청할 때, HTTP 헤더의 Accept 필드를 사용하여 어떤 컨텐츠 타입의 리소스를 원하는지도 함께 이야기해준다. 일반적으로 이 필드를 명시하지않을 경우 브라우저는 자동으로 text/html을 비롯한 몇 가지 타입들을 스스로 정의해서 헤더에 담아주고는 한다.
GET http://evan.com/
Accept: text/html,application/xhtml+xml,application/xml,*/*
...이런 요청을 받은 서버는 클라이언트가 보낸 요청의 Accept 필드를 보고 앞에서부터 하나씩 찾아가며 요청받은 리소스와 알맞은 컨텐츠 타입이 있는지 하나씩 살펴보게 되고, 이후 알맞은 컨텐츠 타입이 있다면 HTTP 응답 헤더의 Content-Type 필드에 해당 컨텐츠 타입을 명시해주게 된다.
HTTP/1.1 200 OK
Content-Type: text/html이 과정에서 어떤 컨텐츠 타입의 리소스를 응답으로 내려줄 것인지는 전적으로 서버가 결정하게 되므로 이 과정을 “서버 주도 컨텐츠 협상”이라고 하는 것이다. 위의 예시의 경우 클라이언트가 받기를 원했던 컨텐츠 타입 중 첫 번째 우선순위를 가진 text/html를 받아왔지만, 만약 서버에 text/html 타입의 리소스가 존재하지 않는 경우, 서버는 application/xhtml+xml, application/xml 순서로 리소스를 탐색하게 된다.
만약 앞에 나열된 모든 컨텐츠 타입이 없는 경우 클라이언트가 요청했던 컨텐츠 타입 중 가장 마지막인 */* 와일드 카드에 걸리기 때문에, 서버는 리소스가 어떤 컨텐츠 타입인지 상관하지 않고 그대로 응답해줄 것이다. 그러나 만약 클라이언트가 요청한 컨텐츠 타입을 모두 탐색했는데도 불구하고 알맞은 리소스가 없을 경우 서버는 406 상태 코드와 함께 “니가 찾는 컨텐츠 타입과 맞는 리소스가 없어”라는 응답을 주는 것이다.
408 Request Timeout
상태 코드 408은 클라이언트와 서버의 연결은 성사되었지만 요청의 본문이 계속 서버에 도착하지 않는 상황을 의미한다.
HTTP 프로토콜을 사용하여 통신을 할 때는 반드시 클라이언트와 서버 간의 연결을 생성하고, 그 이후에 요청 본문에 해당하는 데이터를 전송하게 되는데, 408 상태 코드는 이 과정에서 연결은 제대로 생성되었지만 서버가 아무리 기다려도 클라이언트가 보냈던 요청 본문을 받지 못하는 경우에 발생하게 된다.
429 Too Many Requests
상태 코드 429는 클라이언트가 서버에 너무 요청을 많이 보내는 경우에 발생한다. 너무 많이 보냈다는 것은, 너무 짧은 시간 안에 빠르게 요청을 마구 날려대서 서버가 “워워 진정해”라고 하는 경우일수도 있고, 유료 API를 사용하는 경우에는 현재 금액으로 사용할 수 있는 API 요청 횟수를 초과해서 “돈을 더 내세요”라는 의미로 사용되기도 한다.
서버에서는 429 상태 코드와 함께 응답 헤더의 Retry-After라는 필드를 사용하여 “이 시간 이후에 재요청해봐”라는 의미를 전달할 수도 있다.
500번대
500번대의 코드들은 클라이언트가 아닌 서버에서 뭔가 말썽이 일어난 경우이다. 만약 이 상태 코드를 발견했다면 서버에서 뭔가 박살났다는 의미이므로 다소곳이 백엔드 개발자의 멱살을 잡아보도록 하자.
500 Internal Server Error
상태 코드 500은 백엔드 어플리케이션 내에서 뭔가 알 수 없는 에러가 발생했다는 의미이다. 대부분 제대로 핸들링되지 않은 에러가 발생한 경우가 많으므로, 에러의 원인을 클라이언트에게 알려주지 않는다.(라기 보다 알려줄 수 없는 상태인 경우가 많다)
또한 이렇게 핸들링되지 않은 에러의 원인을 클라이언트에게 고스란히 알려주는 것은 보안 사고가 발생할 가능성이 너무 크므로, 500 상태 코드로 에러의 발생 자체만을 알려주는 경우가 대부분이다. 만약 이 상태 코드를 만난다면, 바로 서버 로그를 까보거나 Sentry나 Bugsnag과 같은 에러 모니터링 솔루션을 적극 활용하는 것을 추천한다.
502 Bad Gateway
상태 코드 502를 만날 수 있는 가장 흔한 상황은 바로 백엔드 어플리케이션이 죽은 상황이다. 근데 왜 “Server Died”와 같이 직접적인 메세지가 아니라 “Bad Gateway”와 같은 메세지를 보내주는 것일까?
그 이유는 백엔드 아키텍처가 아무리 간단한 구조라고 해도 절대 어플리케이션 1개로만 구성되지 않기 때문이다. 여기서 말하는 게이트웨이는 어플리케이션 간의 추상적인 연결점을 의미하는데, 이 메세지가 의미하듯 백엔드의 아키텍처는 최소 2개 이상의 어플리케이션으로 구성된 경우가 대부분이다.
일반적인 경우 클라이언트가 보낸 요청은 곧바로 백엔드 어플리케이션에 전달되는 것이 아니다. 사실 백엔드 어플리케이션에 앞단에는 아파치나 Nginx 같은 서버 엔진이나 로드밸런서 같은 친구들이 대신 요청을 받아서 백엔드 어플리케이션으로 전달해주는 경우가 대부분이다.
server {
listen 80;
server_name evan.com;
location / {
proxy_pass http://127.0.0.1:3000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}Nginx를 사용하면 일반적으로 이런 설정을 사용하게 되는데, 이렇게 되면 Nginx는 80번 포트에서 대기하며 HTTP 프로토콜을 사용한 요청을 받아 3000번 포트에서 대기하고 있는 백엔드 어플리케이션에게 전달해주는 역할을 수행하게 된다.
이런 아키텍처를 사용하는 이유는 보안과 처리 효율 때문이다. 백엔드 어플리케이션 자체가 완전무결한 친구가 아니기 때문에 모든 요청을 안심하고 백엔드 어플리케이션에게 먹여줄 수가 없는 것이다. 그렇다고 누가 사용하는 지도 모르는 클라이언트에서 안전한 요청만 보내줄 것이라는 기대 또한 어불성설이다.
게다가 뭔가 연산이 필요한 요청이 아닌, 파일을 찾아서 보내주기만 하는 간단한 요청 같은 경우는 굳이 안 그래도 바쁜 백엔드 어플리케이션에게 시킬 필요가 없으므로 이런 서버 엔진이 대신 처리해주기도 한다.
그래서 백엔드에서는 앞 단에 아예 프록시 서버를 두어서 문지기 역할을 시키는 것이다. 이때 이 프록시 서버와 백엔드 어플리케이션 간의 연결된 추상적인 통로를 “게이트웨이”라고 부르는 것이다. 백엔드 어플리케이션이 죽어버릴 경우 앞 단의 문지기인 프록시 서버는 백엔드 어플리케이션에게 아무런 응답을 받지 못하게 되고, 클라이언트에게 502 Bad Gateway라는 응답을 보내주는 것이다.
503 Service Unavailable
상태 코드 503은 서버가 요청을 처리할 준비가 되지 않았음을 의미한다. 간혹 502 Bad Gateway와 비슷한 느낌으로 사용되기는 하지만, 503은 보다 “일시적인 상황”을 의미하는 상태 코드이며, 일반적으로 서버에 부하가 심해서 현재 요청을 핸들링 할 수 있는 여유가 없는 경우에 많이 사용된다.
AWS Lambda에서는 요청을 처리할 때 컨테이너의 동시 실행 갯수를 초과할 정도의 리소스가 필요하거나 어떤 작업의 처리 시간이 Lambda에 설정된 컨테이너의 최대 수명 시간을 초과했을 경우에 발생하기도 한다.
이렇듯이 503은 일시적인 상황을 의미하므로 429 Too Many Requests와 동일하게 응답 헤더의 Retry-After 필드를 사용하여 “이 시간 이후에 다시 요청해봐”라는 의미를 클라이언트에게 전달해줄 수 있다.
504 Gateway Timeout
상태 코드 504는 408과 마찬가지로 요청에 대한 타임아웃을 의미한다. 그러나 504 상태 코드는 클라이언트에서 보낸 요청 때문에 타임아웃이 발생하는 것이 아니라 백엔드 아키텍처 내부에서 서버끼리 주고받는 요청에서 발생한다.
앞서 이야기했듯이 백엔드의 아키텍처는 단순히 백엔드 어플리케이션 하나로만 구성된 것이 아니기 때문에, 클라이언트의 요청이 서버에 닿은 뒤에도 백엔드 어플리케이션끼리의 통신이 발생하게 된다. 만약 프록시 서버 역할을 맡은 Nginx가 백엔드 어플리케이션에 클라이언트의 요청을 전달했는데, 백엔드 어플리케이션이 일정 시간 동안 응답을 하지 않는 경우 Nginx는 클라이언트에게 504 Geteway Timeout을 내려주게 되는 것이다.
마치며
사실 이번 포스팅에서는 HTTP 상태 외에도 RESTful API에 대한 내용도 함께 이야기하려고 했지만, 다시 한번 분량 조절에 대실패하면서 포스팅을 나누어 작성하게 되었다.(점점 빈도가 잦아진다…)
앞서 이야기했듯이 이런 상태 코드와 같은 요소들은 딱히 안 지킨다고 해서 프로그램에서 에러가 발생하는 것도 아니기 때문에 가볍게 생각하고 넘어가기 쉽상이지만, 보다 명확한 인터페이스를 정의하게되면 프로그램의 작동을 예측하기도 쉬워지고, 프론트엔드와 백엔드 개발자 간의 커뮤니케이션에도 큰 도움이 되기 때문에 되도록이면 표준을 지켜주는 것을 권장한다.
이상으로 서버의 상태를 알려주는 HTTP 상태 코드 포스팅을 마친다.